


Combating Money Laundering: AML Compliance Program Design

Enterprise Account Manager
1 min read

Money laundering is among the hardest activities to detect in the world of financial crime. Funds move in plain sight through standard financial instruments, transactions, intermediaries, legal entities and institutions – avoiding detection by banks and law enforcement. The costs in regulatory fines and damaged reputation for financial institutions are all too real. Neo4j provides an advanced, extensible foundation for fighting money laundering, reducing compliance costs and protecting brand value.
In this second blog in our six-part series on using graph technology to fight money laundering, we dive into the details of the money-laundering detection process and explain the benefits of using Neo4j for money-laundering detection at scale.
Money Laundering Detection Process
Large banks commonly process millions of transactions per day that are subject to AML compliance, each of which is associated with one or more parties.
AML challenges are daunting for a variety of reasons, including:
- Banks must process tens of millions of records in real time each day
- Banks serve individuals, corporations, other banks, and a world of educational,
governmental and non-profit institutions - Globally, transactional data is recorded in many languages, address formats, and
character sets, and that data is encrypted and obfuscated to maintain its privacy - Transactions follow various formats such as SWIFT, ACH and wire transfers
- Data fields often contain unstructured data, misspellings and inconsistencies
- Parties to transactions may be owned by other entities, which makes it even more difficult
to identify everyone involved in a transaction
Processing transactions involves two steps:
- Resolve entities for each party by determining the degree of certainty the company knows all of the parties
- Flag suspicious activity by scoring suspicious transactions and parties for risk
Resolving entities and flagging can be automated using scoring models, which makes subsequent manual investigation more effective.
Regulations require businesses to have an AML program in place. One team typically performs entity resolution (ER) and flagging, and another team investigates.
Resolving Entities
Prior to using Neo4j, companies relied solely on standalone text analytics and AI/ML to resolve entities. While the accuracy and efficiency of these methods has improved, they still cannot account for relationships in the underlying networks of parties and payment chains. Using these relationships makes the process more effective. Neo4j stores the rich connections in this complex network of people, places, institutions, behaviors, and times in order to improve the accuracy of the entity resolution process.
Moreover, Neo4j performs both text and graph analytics in place without having to move massive amounts of data across siloed applications. This results in faster, more efficient processing and more accurate scores.
To illustrate, two entities with similar text analytic scores may make payments to similar subsets of counterparties and may be affiliated with the same legal entities. These two entities may be associated directly or indirectly with entities that are on a watch list, have unknown
ownerships, or are located in high-risk geographies. Neo4j can detect these previously undiscovered relationships between the entities to more accurately identify the same entities using a process that combines graph and text analytics.
One of the challenges of entity resolution (ER) scoring is that information about parties can initially be limited. Initial profiles of customers might be based on information reported by the customers themselves. A counterparty’s initial profile might be limited to a party name,
address, bank name and address, and account number. Over time, business processes must enhance party profiles with third-party data, information related to transactions and account activity, and details learned by investigators of flagged transactions. Millions of entities must be resolved in real time for billions of transactions daily.
For each transaction, onboarding and account creation, the entity resolution process:
- Compares parties in the transaction to already-known parties
- Adds previously unknown parties to the database
- Adds new data captured in transactions to the party master
Connecting new information to the information already known about entities gives companies
better data for their flagging algorithms, thus reducing false positives and negatives.
The Neo4j scoring process indicates the degree of certainty as to whether a party is already in
the database by performing a two-step process:
- Text analytics that determine text similarity
- Localized pattern matching that determine context similarity
The Benefits of Using Neo4j for AML
Neo4j not only enables the native storage of the rich connections in this complex network of
people, places, institutions, behaviors, attributes and times – it goes even further to identify suspicious patterns in those networks.
By leveraging Neo4j to answer these kinds of questions, compliance teams:
- Better comply with AML and other global risk and compliance (GRC) regulations
- Make more accurate predictions
- Save money on regulatory fines
- Increase sales by improving brand reputation
- Reduce costs associated with false positives and false negatives
- Meet the most stringent requirements for performance, availability, security and agility
at extreme scale
Text Analytics Scoring
Using text analytics to score transactions introduces significant challenges. Transactions contain unstructured data, misspellings and inconsistencies in language, formats and character types. In other cases, transaction details are quite limited.
After transactional data is parsed, extracted and normalized, to enrich the information Neo4j
applies text algorithms to score similarity among entities. For example:
- Jaro-Winkler Distance, which compares first or last names in different sources
- Sørenson Dice, which gauges similarity between two samples
- Levenshtein Distance, which compares strings for misspellings, punctuation differences
and other subtleties
Neo4j uses the resulting enhanced, scored party information as the basis for pattern
matching.
Localized Pattern-Match Scoring
Localized pattern matching looks for attributes having direct or indirect relationships to other anchor attributes. Common pattern-match scores can include shared-attribute anchors such as address, phone number, email address or domain.
Localized pattern-match scoring algorithms also consider the number of paths from the anchor point to resolved entity as well as the number of hops. When scoring paths, techniques such as linear, pareto, logarithmic and weighted scoring are used for aggregation. Other techniques also boost and exclude weights based on relationship types.
Graph Algorithms
Maintaining an AML database presents some unique challenges. Over time, a database grows to contain millions of parties and billions of transactions – an unwieldy size for non-graph technologies that makes analysis inefficient. It is also all too common for an AML database to
contain inaccurate, incomplete, old or missing information.
To handle these unique AML challenges, Neo4j uses graph algorithms to:
- Fill in gaps of missing and inaccurate data
- Identify subgraphs that are relevant for scoring the current transaction
- Combine normalized string-similarity and pattern-match scores to produce an overall
similarity score - Weight relationships among similar entities and apply community-detection techniques
Graph algorithms run in near real time because they are applied to a subset of the overall graph. Later, to enhance the value of information in the AML database, Neo4j can run graph algorithms over the entire graph to assess historical similarities scores between entities as
transaction and party histories grow and enhance the richness of the data.
Flagging Suspicious Activity
Once entities have been resolved, the AML process flags suspicious entities and transactions. Transaction analysis follows money trails by tracing transactions across counterparties, who subsequently may make payments to others.
To keep pace with money launderers, investigators must constantly improve their systems with better data, models and judgments. Neo4j’s AML Framework gives investigators the power they need to keep pace because it:
- Reduces the volume of false positives and false negatives
- Automates and instills rigor to the ER-scoring process
- Acquires connected data that enriches the master party dataset
- Cultivates domain expertise to model relationships to help identify payment chains
The AML process scores suspicious parties and transactions using localized pattern-match
scoring algorithms that look at structural and behavioral patterns that include:
- Guilty by Association scores
- Suspicious structure scores such as entities with unknown ownership, cash-incentive
businesses and high-risk geographies - Suspicious behavior scores involving transaction structuring and payment-chain layering
such as rapid movements, accumulation and concentration of funds
Guilty by Association Scores
It is common to judge people by those with whom they associate, and the same holds true in
anti-money laundering analysis. Guilty by Association scores are based on the quantity, quality
and distance of a party’s relationships with suspicious entities. In graph terms, algorithms
create scores that are based on paths and hops from start to end points.
Some Guilty by Association scores include customers associated with the following watch lists:
- Regulatory and law enforcement actions
- Negative news coverage
- Global and narrative sanction lists
- Politically Exposed Persons (PEPs)
- High-risk individuals or legal entities
- Legal entities with unknown ownership
- Counter-parties in high-risk geographies
- Banks in high-risk geographies
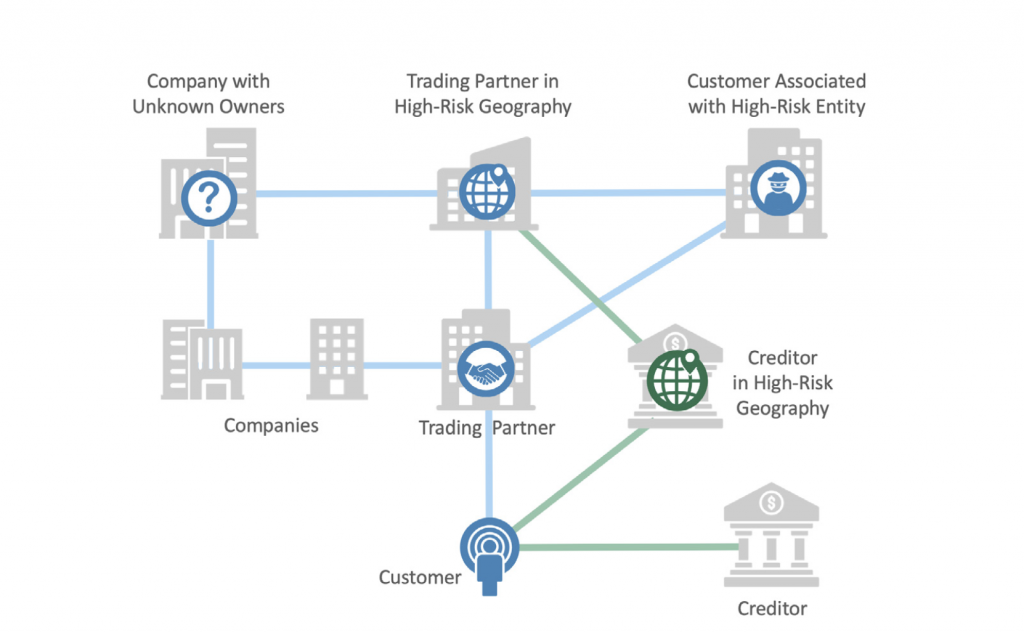
Guilty by Association algorithms score parties based on the quantity, quality
and distance of related parties’ relationships with suspicious entities.
Finding Suspicious Activity Using Graph Algorithms
As with the ER process, the flagging process applies several scoring algorithms before
applying graph algorithms.
After Guilty by Association, Layering, Undervalued Invoices and other scenario analyses are
executed, run these graph algorithms:
- Weakly Connected Components algorithm to identify the network of account holders in a
payment chain that high-risk accounts use to conduct money laundering - Centrality algorithm to determine the role and relevance of the accounts in the network
- Clustering algorithms such as Louvain or Strongly Connected Components to identify
subnetworks and payment chains within the money laundering network
Investigating Suspicious Transactions
Investigating flagged transactions by centralized teams is expensive. An investigation can
lead to their filing a Suspicious Activity Report (SAR), which law enforcement agencies use to
initiate enforcement actions. Besides reducing false positives and negatives, the Neo4j AML
framework provides more relevant facts and circumstances surrounding the transactions
that were flagged as suspicious in the SAR, making the investigation process easier and
more thorough.
One of the key goals of flagging is to produce a highly automated playbook of templated,
parameterized questions that can be used to flag suspicious entities, transactions and
activities.
Parameterized playbook questions written by IT staff help your analysts explore various AML
behaviors without having to write code. Just like in sports, playbooks aren’t perfect, and being
adept at calling a new play that changes the current game plan is crucial.
Investigators need to understand the facts and circumstances surrounding a flagged entity or
transaction. They must be able to filter, expand paths and ask ad-hoc questions at interactive
speeds to explore the full context of the structure, behavior and time surrounding the
flagged items.
Conclusion
The sheer volume of data makes AML information impossible to comprehend without a self-service data visualization tool that supports real-time, natural language and ad hoc analysis.
Neo4j Bloom and the graph algorithms in the Neo4j Graph Data Science Library enable
analysts to visualize suspicious clusters and entities at a high level.
Next week, in blog three of our six-part series on fighting money laundering with graph technology, we will explore the inner workings of an enterprise-class AML solution architecture, explaining concepts such as index-free adjacency as well as the use of graph data science for analyzing suspicious patterns at scale.
Stop money laundering in its tracks. Click below to get your copy of How to Combat Money Laundering Using Graph Technology.
Share Article



Explore
Related Articles

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths

Whose Signature Really Matters? Understanding PageRank Through Yearbook Signatures

From Cafeteria Cliques to Graph Communities: Understanding the Louvain Algorithm
Detect Fraud Faster With a Transaction Graph

Why LeBron James Shouldn’t Drive Your Recommendations: The Intuition Behind the Jaccard Coefficient
