Welcome to the dark side: Neo4j worst practices (& how to avoid them)

Field Engineer
15 min read
Editor’s Note: Last October at GraphConnect San Francisco, Stefan Armbruster – Field Engineer at Neo4j – delivered this presentation on the worst (and best) practices for using Neo4j in your particular deployment.
For more videos from GraphConnects, check out graphconnect.com..
Oh, and one more thing if you’re reading the transcript: Remember that sarcasm and tongue-in-cheek comments don’t always translate well into the written word. I’ve tried my best to make humorous points clear, but if you’re in doubt, watch the video instead.
I’ve worked for the Neo4j team for more than three years now as a field engineer, and in that period, you see all kinds of things going wrong. I’m going to talk about worst practices and welcome you to the dark side.
We’ll walk through some stories and anecdotes, but don’t be scared, as I won’t mention any customer names.
Onboarding with Neo4j: What not to do
There are a number of pitfalls to avoid when first getting started with Neo4j, which include:
- Testing Neo4j for the first time on a mission-critical project
- Working with team members who don’t have any graph database experience
- Ignoring business requirements
- Skipping out on Neo4j training
- Working entirely independently and learning everything yourself
- Applying relational database logic and thinking
- Ignoring the learning curve
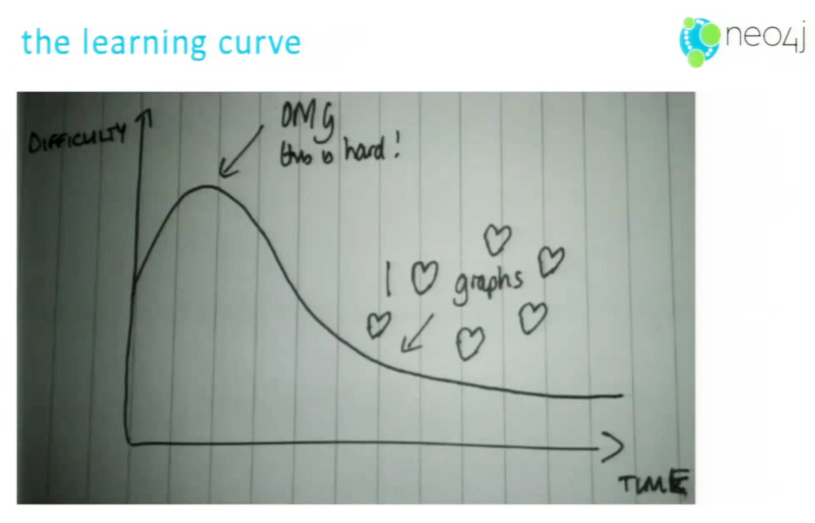
Mark Needham drew the following graph database learning curve:
In the beginning, learning how to use the graph database software can be challenging. But as time goes on, the ease of use increases significantly, until you get to the point where almost everything in your life looks like a graph.
The dark side of graph data modeling
Because graphs are schema-less, you might be tempted to ignore its design, to neglect documenting the graph model and to skip out on naming conventions.
Consider the following example of a Neo4j customer: I once worked with a traditional, large-scale German enterprise that required everything in the graph database be written in German, including relationship types and labels.
They had a team member whose sole responsibility was to translate text from German to English and vice versa. And even though Neo4j is UTF-8 (and fully capable of handling German umlauts), if you run the same query on a client that runs English locale and on a client that runs German locale, you’ll end up with different results.
To some of you, this difference is already obvious, but if you didn’t, you could have spent days and days debugging that single language issue.
In terms of data modeling, it’s important to find the middle ground between placing all attributes and properties in a single node and separating each attribute into an individual node. Both of the following extremist approaches will cause significant problems for your graph, as you can see below:
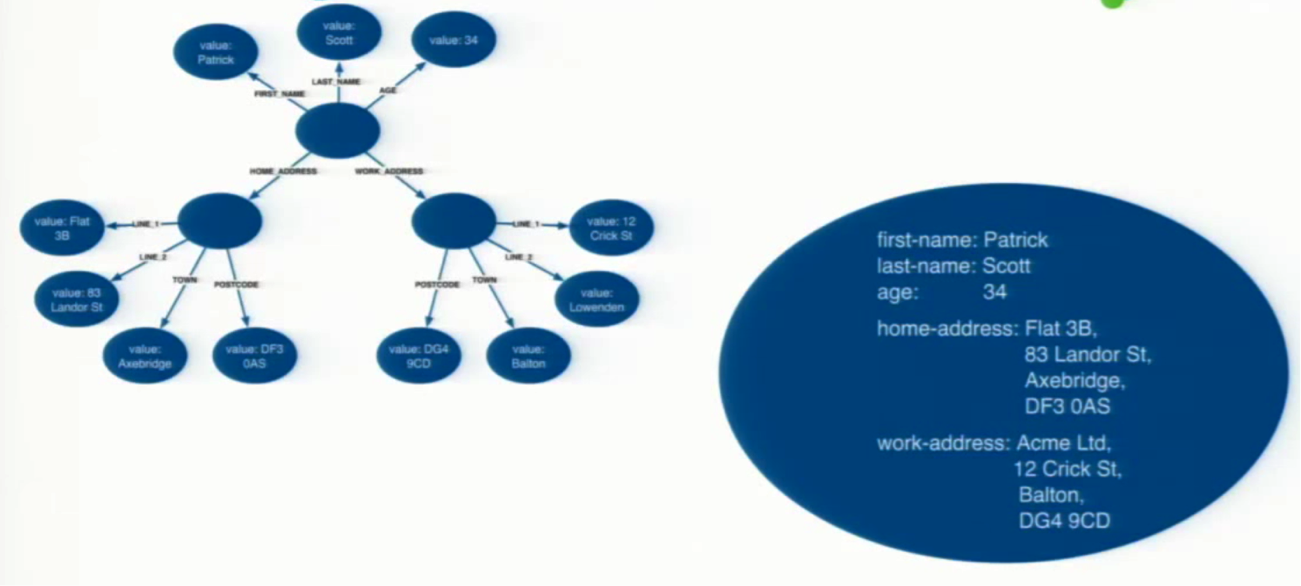
Of course, the right way to model that kind of case is in the middle so everything that is a thing on its own should be a node. So a person, of course, and maybe their address should be a node on its own, but then you should make use of properties which describe the attributes of those entities.
You can also encounter issues when developing relationship types in your graph database. On the left in the below example, there is only one relationship type: CONNECTED_TO. In the example on the right, they have scoped every relationship with an instance, meaning there is a single relationship type per relationship.
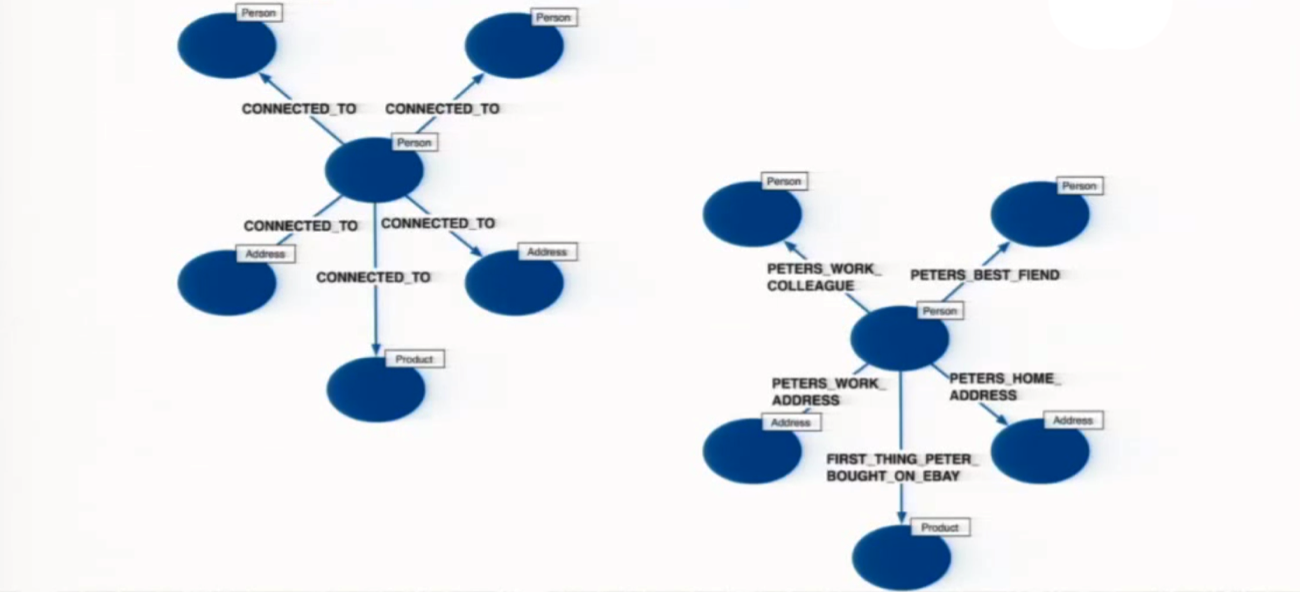
But you need to be careful when it comes to the number of relationship types, because Neo4j limits the number of relationship types to 65K to keep the database fast.
Worst practices for BLOBs in Neo4j
Another common mistake I see is using Neo4j as a Binary Large Object (BLOB) store. You might have heard that we do support byte type properties, and we do support arrays of primitives so byte arrays are possible. This, of course, opens up the possibility of storing gigabytes of data in a property value.
Honestly, the reason for that is because we organize properties in BLOB. At the end of the day, all the properties go into one file, and if it’s a huge property, it’s cluttered all over the file, and it takes a very long time to read that.
Using BLOB data in Neo4j is one of the very few real anti-patterns for graph databases, in my opinion. If you have to deal with BLOB data, choose an appropriate store for that use case and use Neo4j to store the URL that points you to the binary data.
The dark side of hiding aspects in your data model
Another pitfall to avoid is hiding aspects.
In the below example, we (incorrectly) modeled the country as a property of the person. If we want to find all my friends who live in the UK, the first query below traverses both the Mark and Michael nodes and then filters out Michael.
However, if you treat the country as a constant on its own, your query will be more efficient because it won’t have to touch the Michael node at all. While this may not make much of a difference in small datasets, it can really slow down your queries in a much larger dataset if you are hiding your main concepts in your data model.

Query patterns should influence the way you model data, which is very different from relational databases. In the graph world, you take the query patterns into consideration when deciding on your data model.
Best and worst practices with Node IDs
Honestly, adding get ID on the node interface was one of the worst design decisions ever made in Neo4j.
Node IDs have a semantic and give you the offset of that node or relationship within the store file. Consider the following example: Let’s say you delete a node that has a reference in MongoDB (or your other third-party database), only you forget the reference in Mongo to that now-deleted node.
After the original node is deleted, there’s a free space in the node file, so when you create a new (likely unrelated) node, it now uses the same previously-used Node ID. The dangling reference now points to something semantically completely different, which can cause huge problems in your database.
Instead of relying on the semantic-driven ID, you can store a UUID property, place an index on that and then reference the UUID. Then, even if you delete the node in the future, and you forget about the reference from a third-party system, you’ll end up with an error message instead of a dangling reference.
Indexing: The good, the bad and the ugly
Neo4j provides a number of different ways to index data, but not all of them are the best. While legacy manual and auto indexes give you fine-grained control, they shouldn’t be your top choice.
Seriously, you should always use schema indexes whenever possible. Schema indexes were added in Neo4j 2.0, and now with Neo4j 2.3, they have been significantly improved. You can now do prefix queries based on indexes as well as range queries, and I hope we see more in the future on that. Our long-term goal is leave legacy indexes behind entirely.
There’s a story about that. When we first released Neo4j 2.0, we had converted all the functionality of the legacy indexes into the schema indexes, but we had done it really fast. That’s why we initially labeled the older indexes as “legacy.”
But there are cases when you still need legacy indexes. For example, if you want to do full-text indexing, you can’t do that with schema indexes. Sorry. As we work to replace legacy indexes entirely (including for full-text indexing), we’ve chosen to make legacy indexes a little bit hard to use. So if you’re finding them difficult, that’s good, because one day, they’ll be gone forever.
Another major mistake: Indexing everything.

All too often, I’ve seen developers create a label and then create an index for all the properties that label could (or should) have. After all, they might use that index one day, right? Wrong.
I’ve seen one example of a graph store with less than a gigabyte of data and the index folder was 150 gigabytes. They had just indexed everything.
With Neo4j, Indexing basically means you trade write performance for read performance. So you invest more in the writes than you gain on the reads every time you create an index.
If you have an index that you never use in a query, your CPU gets a little bit warmer, the disks get a little bit fuller and probably since your system is smaller, my sales colleagues happily sell you another instance to increase your performance.
A few words on the dark side of Cypher
A quick note on Cartesian products: It’s pretty common that developers from the RDBMS world will write queries that result in a Cartesian product, so in Neo4j 2.3, we now have a warning if the Neo4j Browser detects that you’ve typed a Cartesian product with your Cypher query.
As you get familiar with the MERGE statement, you may get the impression that it guarantees uniqueness. However, it doesn’t. Just try to run the shell command below, which runs 100 concurrent requests to merge a person named “John” into your graph.

After that statement, you will still end up with multiple Johns in the database. If you really want uniqueness, use the UNIQUE constraint. That’s why we have it.
Worst (and best) practices with importing data
Another thing: When using PERIODIC COMMIT, the theory is that for each 1000 or 10,000 rows, a new transaction is opened. In version 2.2, if you use PERIODIC COMMIT or EXPLAIN, you will see the word EAGER in the query plan, which means that PERIODIC COMMIT won’t work with your dataset. This was a huge challenge in version 2.1, but has been greatly improved in versions 2.2 and 2.3.
Whenever you run into a problem with LOAD CSV, try to analyze the statement and check for the EAGER pipe. There is an excellent blog post by Mark Needham that explains how to get around this.
Cypher also allows you to deal with dynamic relationship types. In the below example, consider that CSV fragment on the right. We want to connect people to other people using a dynamic relationship type.

We use FOREACH to mimic dynamic types, which allows us to create a collection that has either one element or is empty, and with the FOREACH loop iterate over that collection. If the condition is true, we iterate once over that, while if the condition is false, we iterate zero times because we don’t have an if-then-else conditional statement.
Unmanaged extensions
A good practice up until version 2.1 was to spin up a new ExecutionEngine for each request. We understood this was a problem, so since 2.2 you have graphdatabase.execute. ExecuteEngine still exists, but it’s deprecated, so you should realize you’re doing something wrong if you’re using it.
Another major mistake is to ignore the principles of REST. Let’s again consider our customer in Germany: They decided to do a lot of stuff in extensions, and they grabbed one example from the Web, which was as a POST request. They said, “Oh, this works nicely, so let’s copy and paste that 100 times. For each of our use cases, we’ll use that kind of strategy.”
Unfortunately, they ended up using POST for read requests. Of course, that got pretty complicated once they tried to put a cache in front of that. If they would have used REST the right way by using the GET method here, you can probably cache that.
Also in unmanaged extensions: If your code involves additional dependencies that are not part of Neo4j itself, don’t forget to put them in the plugins folder. Otherwise, they will prompt some sort of error message, and you’ll wonder why for days.
Finally, one thing you see in a lot of examples on the web is that people tend to build a javax.ws.rs.core.Response on their own, directly from their unmanaged extensions. In my opinion, this is against the design principles of JAX-RS, so you should return your clauses — your Data Transfer Obects (DTOs) — and leave it up to provider clauses to transfer that into JSON or XML or whatever response you want.
I found this library very useful for rendering your custom DTO clauses. That helps a lot if you have to add on the clause path.
Testing
It’s a common temptation to skip testing altogether. It’s hard, after all, but it’s a step you just can’t skip.
When (not if) you test, make sure to use tools like TestGraphDatabaseFactory, the Neo4j Harness Tool or Neo4jRule. Also, be sure not to scatter your test reference graph all over the code base, because if you do, then a single design change means that you have to change that in 1000 places.
There’s also great tooling options from the greater Neo4j ecosystem. There’s the nice Graphgen tool, there is Neode from Michael and Ian, and of course the neo4j-spock-extension is a shameless self-plug. If you don’t use Spock yet, take a look at the Spock framework. It’s totally independent of Neo4j.
Neo4j deployment
In should go without saying, but never use milestone releases in your production applications. We’ve had prospects and community members who have used unstable, milestone releases on production machines and it went horribly wrong in every way imaginable.
Remember that there’s no upgrade path between milestone releases – they’re for testing and feedback only!
Another major snag that gets a lot of developers: Remember to read the release notes for your current version of Neo4j. They aren’t just “write only” documentation written for our own entertainment.
Also worth mentioning is to make sure you’re always looking at server tuning and/or JVM configuration. I don’t care what language you work with, you can’t treat the JVM as a black box.
What about the operating system? Personally, I hate Windows, so I don’t do anything on it. But up until version including 2.1, there was a good technical reason to avoid it as well because one of the two cache layers was off-heap in Linux but on-heap on Windows systems. That meant there was no way to cache a large graph on a Windows system in a proper way.
With the current version, that’s vanished so now, but I do have anecdotal evidence that Windows memory management is much worse than Linux. I have a couple of cases where a customer comes and says, “Well, I’m creating a POC on that graph, and the query takes 25 seconds.” They give me the graph DB folder. I spin up the version myself, no tuning and the query count goes down (on my crappy three-year-old laptop) to 12 seconds. So, we can already gain 50 percent by just switching OS. I’ve no idea why that happens. Maybe someone can explain why, but I think it’s just Windows.
The worst practices of running a Neo4j cluster
It’s critical that you understand the concept of clustering. Just because the Neo4j team has spent years implementing it doesn’t leave you off the hook.
Also, when you run a cluster over subnet boundaries – especially if you cross multiple regions – it makes it easy for the NSA because the network traffic in the cluster is not encrypted, so everyone can read your data.
And don’t forget that your Garbage Collection (GC) pauses should never take longer than the cluster timeout. What results is the lovely* (*sarcasm) effect of a round-robin master switch.
Additionally, if you use ha.push_factor=0 you will have branching data, and that is a nightmare. That point is made very clear in the documentation, so don’t complain about if branching happens to your data – it should be expected.
Don’t live on the dark side of the community
Finally – and most importantly – one of the worst things you can do is to become an isolated node as a Neo4j developer. But you don’t have to live on the dark side of the community.
Join one of our in-person meetup groups; discuss your challenges on our (very active) Google Group; or ask your questions on Stack Overflow and use the Neo4j tag.
If you don’t do any of these things, then you might make it into my “Neo4j Worst Practices” presentation next year!
Inspired by Stefan’s talk? Register for GraphConnect Europe on April 26, 2016 at for more industry-leading presentations and workshops on the evolving world of graph database technology.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

