
DB-Engines, Informix and Neo4j: An Origins Story

CEO & Co-Founder, Neo4j, Inc.
3 min read
A funny thing happened four-ish weeks ago.
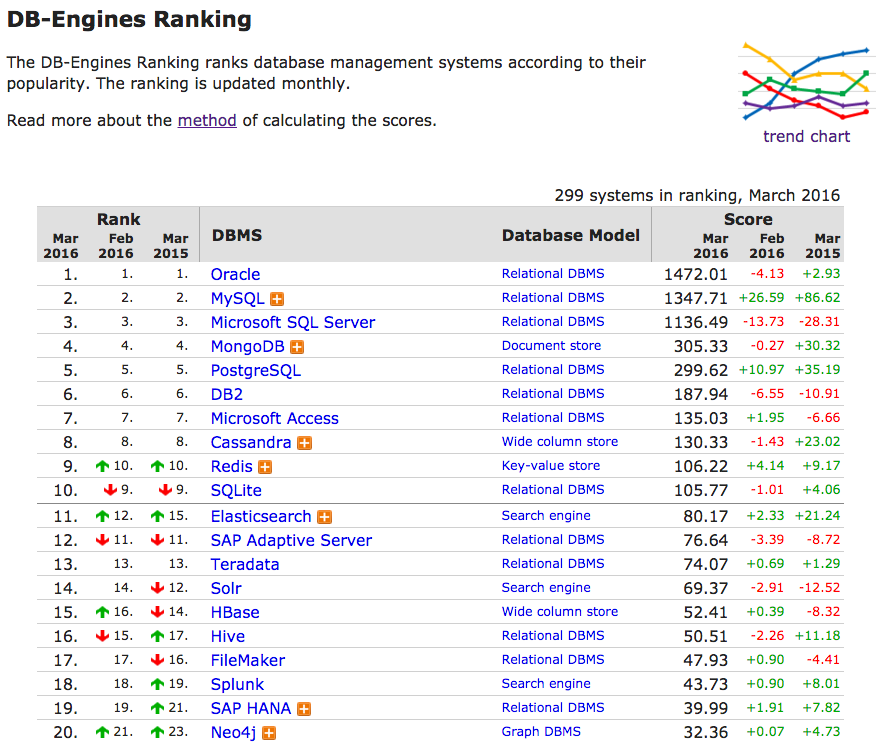
On March 1st, the database industry monitor DB-Engines published their usual monthly ranking report for the world’s most popular database management systems. For the first time, Neo4j was listed in the top 20.
This is certainly a moment of pride for me as a co-founder, and I look forward to Neo4j rapidly working its way towards the top ten. Of course, even this step along the way is a huge validation that graphs really are eating the world.
But this isn’t about our accomplishments. There’s a deeper story underneath the surface, and in order to appreciate it, we’ll need to take a look back to a time before graph databases were a thing.
Choosing Our First “Big Four” Database
It all started when Peter, Johan and I were working on an enterprise content management system (ECM). At the time, we had a three-tier architecture that was pretty standard.
At the top we had a web presentation layer, below that was a relatively unknown app server called Silverstream, and at the bottom of our development stack was a relational database called Informix.
For those of you who don’t remember Informix, it was one of the “Big Four” databases that emerged as winners of the RDBMS wars in the 80s (the other ones, of course being Oracle, DB2 and Sybase, which was later overtaken by Microsoft SQL Server and subsequently acquired by SAP… but I digress).
This was a very standard architecture in the late 90s and early 2000s. But here’s where we ran into problems.
The Challenge of Connected Data
In any content management system, you’re going to have a lot of connected data, and ours was no exception. The problem was that as an RDBMS, Informix wasn’t optimized to handle the relationships between all our data.
Of course, we tried every tuning trick in the book. We even brought in an armada of Informix consultants to helps us optimize our data access, but it was always slow and limited no matter what we tried.
And not only that, but from a developer productivity perspective, we found ourselves constantly bogged down by having to work through the mismatch of our connected domain model and the abstraction exposed to us by our database of choice.
While it was certainly a best-of-breed relational database, Informix simply couldn’t handle the connected-data queries we (and our users) asked of it daily.
Faced with the challenge of using an RDBMS for connected data, we decided to create a new kind of database optimized for connected data: The graph database.
Coming Back Full Circle
The story of how we had to define a category for our newly invented product is one for a different day (or a different blog post!), but it’s certainly been a long journey – validated along the way by developers and architects that faced the same issues with connected data in their RDBMS.
Now, it’s been fifteen years since our first back-of-the-napkin sketch for the idea of a graph database, and as of this month, we’re in the top 20 database management systems used globally.
Oh, and by the way, who was the previous holder of the #20 position on DB-Engines?

That’s right, Informix.
Share Article



Explore
Related Articles





