

Editor’s Note: This presentation was given by Dom Davis at GraphConnect Europe in May 2017.
Presentation Summary
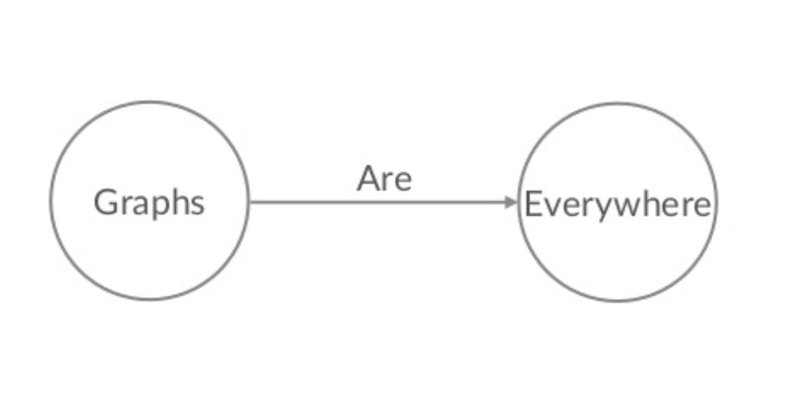
Graphs really are everywhere, and building your graph database model from the highest possible vantage point using natural language – and the language specific to your domain – helps you develop a model that truly stands the test of time.
Full Presentation: Decyphering Your Graph Model
In this blog, we’re discussing how to develop the best graph model for your particular domain from the highest possible level:
At the startup Tech Marionette, we’re building the next generation of configuration management databases. This is backed by
Neo4j because the assets in an enterprise don’t live in silos of a relational database. They’re interconnected graphs. And graphs really are everywhere! It’s not just a catchy marketing slogan.
Finding graphs is easy, but modeling them is the fun part. Most basic texts on graphs start with vertices and edges:

From there, we dive off into graph theory. That said, making the leap from the world of numbers and letters into something slightly more useful isn’t that hard. And being a property graph with Neo4j, we can embellish our data with some useful stuff.
But jumping straight into Cypher isn’t necessarily the best way to go about discovering the model of your world.
Building Your Model Using Natural Language
A graph is essentially a way of modeling the world using interconnected triples in the format of noun-verb-noun. Take the below example, graphs (noun) are (verb) everywhere (noun):
It’s just English. The astute among you may notice there are countless other languages out there, many of which don’t follow this particular format. But we can make this work for any language regardless of the order of subject, verb and object. You simply reason about your model in your natural language and then map it back to the subject-verb-object field graph when you’re done.
Building a Natural Language Model in Your Domain
If you’re going to model the world, let’s start with the nouns of that world. If I was going to model this conference, we might start with the nouns below:

Taking our nouns, we can then form sentences with verbs:

We’re creating a model that we can reason about because it’s using natural language. And once we have our nouns and our verbs, we have labels and relationships. The graph model just falls out nice and easy:

Now we can start embellishing our data. A “speaker” has a name, and the phrase “has a” implies a property. “Room” also has a name, and “talk” has a title and a start time – but does it have an end time? Or does it have a duration?
This really comes down to the question you’re going to be asking of your model. Questions like “How long did I spend in talks?” and “How long did I spend giving talks?” are possibly better answered with a duration, because it’s an easier calculation. But a question like “Will I be out of talk A in time for talk B?” may be easier with an end time.
We could put “company” and “roles” as properties of the speaker, but someone could have multiple roles at different companies. Also, “speaker has role at company” looks very much like verbs and nouns. Not only that, but “delegate has role at company,” too.
So let’s build these as part of the model, not tucked away inside properties.
Now we have the basis of a model that we’ve developed using language that’s easily understood, even by people who aren’t familiar with Cypher or Neo4j. This allows you to speak with these domain experts and build your model using natural language.
From Model to Graph
There are some considerations you need to take into account when you convert your model into a graph. While our verbs made sense of our nouns, we’re now viewing the world as instances of those nouns:

While “speaker has role” in our model made sense, “Dom Davis has CTO” doesn’t work in English, which shows that the semantics of our model didn’t survive the translation into the graph world.
I’ve highlighted another potential issue by having “role” as a one-to-many relationship, which requires the speaker-to-role relationship to be one-to-one.
To understand why, we need to look at a slightly different data set:
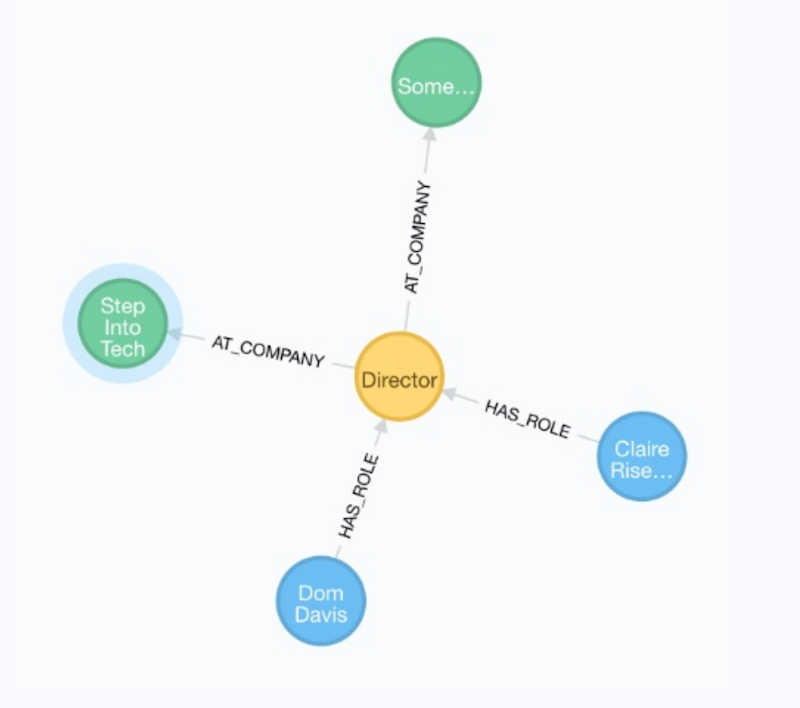
Person (blue) has role at company (green). Because director (yellow) has many relationships in and many relationships out, with this particular model, it’s impossible to tell who is the director of which company.
Instead, we need to have an unambiguous route or path for us to follow with the below, Model A:
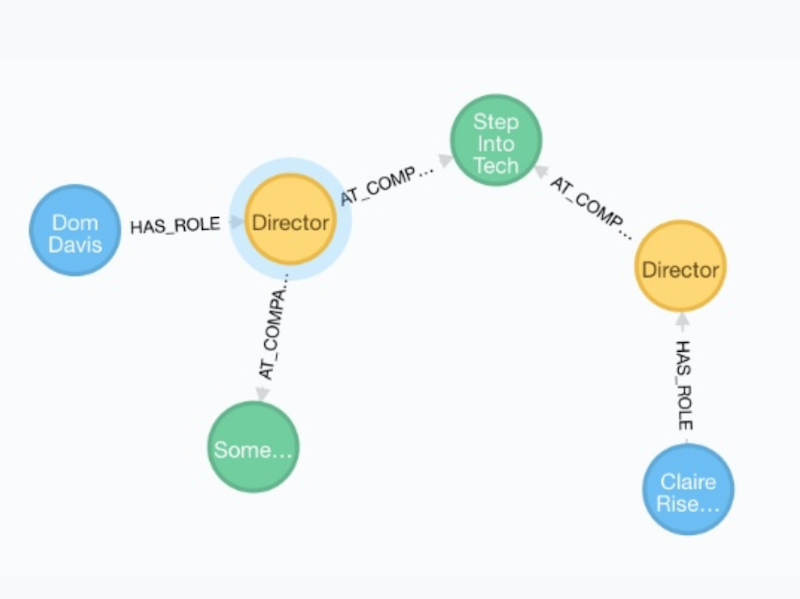
But this isn’t the only way we could have modeled the data. If we just care about companies and company directors, Model B might actually be more sensible:

Data-wise, Models A and B are pretty much the same. Although Model A is more flexible, having hundreds of different relationships between roles is not a good design.
We can store properties like “start dates” on the role, as well as on the “has_director” relationship, but we can’t index those properties and they are extremely inefficient to search. Relationship properties are really only there to help you make a traversal decision, or to give you data once you’ve made that particular traversal.
If you’re going to search on relationship properties, that’s a sign you may need to stick them in a node — even if adding extra nodes into the model may be an alien concept. But unless you have an atomic node and an atomic relationship with no properties, your graph could always be described with more nodes.
Diving Into Cypher
While (:Speaker {name: "Dom Davis"}) can also be written as (:Speaker)-[:HAS_NAME]->(:'Dom Davis'), let’s consider the “speaker-has-role” path in determining which works better:

For my conference profiles, I needed to include a primary role that could be dropped into my bio. We could tag this in our relationship with the “has role.”
But wherever you see this particular construct…

… you can also replace it with a specific relationship type:

You can also record it as a new node, which in this case has something coming off the role:
The abundance of ways to describe things within the graph is why you really want to drive the model with the language of the domain, not from the Cypher query.
If you consider the graph model that I’m working with, we have the idea of concepts, properties and relationships. This might sound like one-to-one mapping with nodes, properties and relationships in the graph, but it’s more complex than that. I have no idea how many properties a particular concept may have, and I have no idea what they’re going to be called.
Hopefully, we all agree that the below setup is absolute madness:
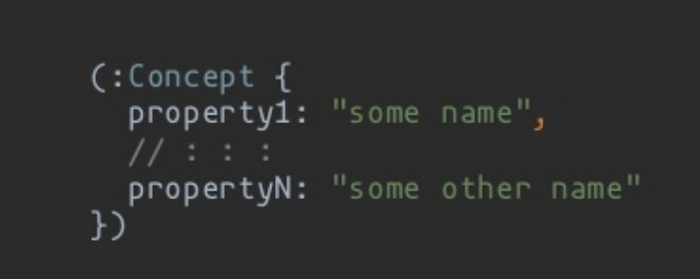
And while this next example is more extensible, I don’t want to see the query plan for things like “find me all the concepts with a ‘name’ property:”

Instead, we looked at how we described the domain. Concepts have properties, so while “has a” implies a property on a node, “has many” implies relationships and nodes.
The solution is the following, which effectively defines property nodes using property nodes and relationships (which is all very meta):

And then below this, we have the idea of instances, which have values:

So we’re defining a schema on our graph and then storing data under that schema.
In fact, we even have a schema node, which lets us do some really interesting stuff in our meta-model. Because the concepts defined in our model can called different things by different people, we can include the idea of “aliases” and “primary language.” You can then define aliases on that model and start asking questions using the terms you would naturally use.
Take a ticketing system for example. You could talk about any ticketing system you’d like, such as Jira or Bugzilla, and each ticketing system could have tickets, issues or tasks. All you have to do is add the aliases:

Conclusion
While the building blocks that Neo4j provides are simple, they’re also incredibly flexible and powerful. In the preceding example I’ve used them to model something that’s very basic, but which in itself lets you model something quite complex.
Have I just reinvented the wheel? No, because when we came to model the domain, we weren’t talking about ticketing systems. We were talking about arbitrary concepts — schemas, concepts, properties, relationships, instances and values — with properties and relationships between them. These were my nouns as I was discussing the domain.
We shouldn’t ignore what the language of the domain is telling us. If we wrote our model at the level of labels, nodes, relationships and properties as our nouns, we would continually have to change our queries and extend our query library every time the model changed.
When we use our model with more arbitrary concepts, it provides us with two models to describe and reason about: the meta-model. The meta-model is mostly complete and static, while the new model is evolving. And we reason about it using the same type of language, and the same advice applies because it really is just graphs all the way down.
Share Article



Explore
Related Articles


How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs


Integrating Neo4j With Symfony: Profiling Queries and Centralized Logging

