


Using GraphQL Middleware With Neo4j GraphQL

Senior Software Engineer, Neo4j
6 min read
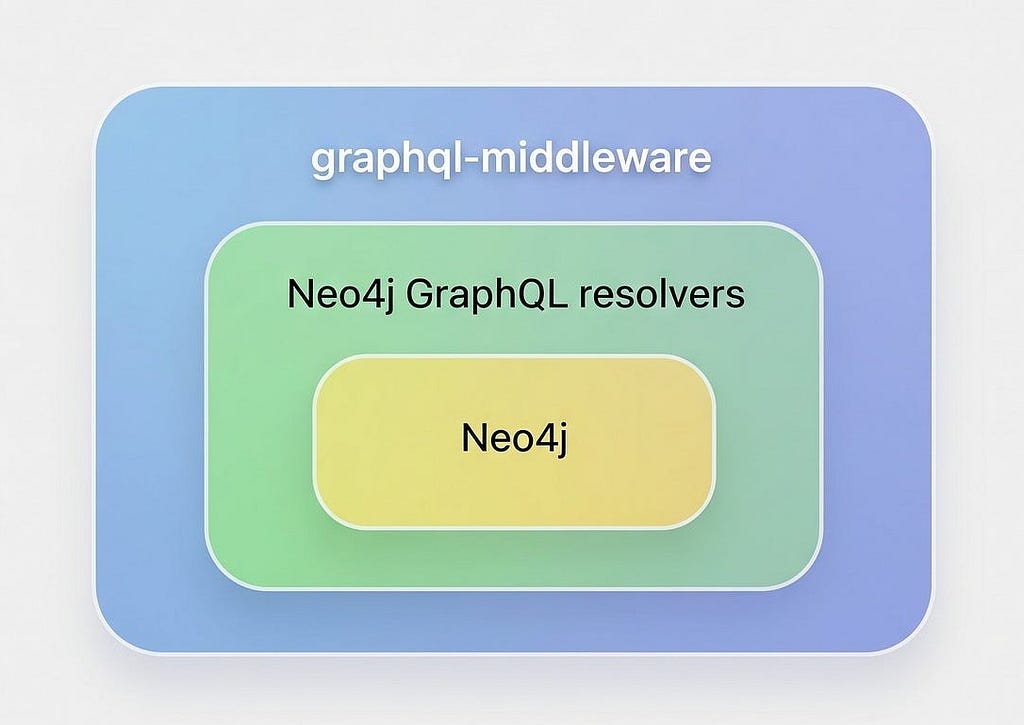
Neo4j GraphQL is a library that auto-generates GraphQL APIs from type definitions, creating complete CRUD operations, relationship traversals, and optimized Cypher queries without writing resolvers. If you’re new to Neo4j GraphQL, check out the official documentation to get started.
Neo4j GraphQL provides powerful built-in features, including but not limited to:
- Automatic CRUD operations
- Complex relationship traversals
- Optimized Cypher queries
- Built-in filtering and sorting
- Authentication
- Authorization
- Cypher directive for user-defined operations
- Custom resolvers
This set of features already provides a significant amount of flexibility to support various user requirements. But sometimes your requirements go beyond what these built-in features can achieve. At this point, some users may consider abandoning the auto-generated resolver entirely and writing their own custom logic.
However, you can wrap your auto-generated Neo4j GraphQL resolver with custom logic that intercepts specific GraphQL operations. This approach allows you to retain all the benefits of auto-generation while adding exactly the custom behavior you need.
GraphQL Middleware
This guide makes use of graphql-middleware, a library that provides a way to wrap and extend the behavior of your GraphQL resolvers. It acts as a layer that allows you to apply reusable logic, such as logging, validation, or authentication, across multiple resolvers in a consistent and modular way.
Logging Every Request
Consider this Neo4j GraphQL setup:
import { ApolloServer } from "@apollo/server";
import { startStandaloneServer } from "@apollo/server/standalone";
import { applyMiddleware } from "graphql-middleware";
import * as neo4j from "neo4j-driver";
import { Neo4jGraphQL } from "@neo4j/graphql";
const typeDefs = /* GraphQL */ `
type User @node {
id: ID! @id
name: String!
email: String!
posts: [Post!]! @relationship(type: "AUTHORED", direction: OUT)
}
type Post @node {
id: ID!
title: String!
content: String!
author: [User!]! @relationship(type: "AUTHORED", direction: IN)
}
type Query {
me: User @cypher(statement: "MATCH (u:User {id: $userId}) RETURN u", columnName: "u")
}
`;
const driver = neo4j.driver("bolt://localhost:7687", neo4j.auth.basic("neo4j", "password"));
const neoSchema = new Neo4jGraphQL({
typeDefs,
driver,
});
const server = new ApolloServer({
schema: await neoSchema.getSchema(),
});
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 },
});
console.log(`🚀 Server ready at ${url}`);Add logging to every single operation without touching the generated schema:
import { applyMiddleware } from "graphql-middleware";
/* ...existing code... */
const logMiddleware = async (resolve, root, args, context, info) => {
const start = Date.now();
console.log(`🚀 ${info.fieldName} started`);
try {
const result = await resolve(root, args, context, info);
console.log(`✅ ${info.fieldName} completed in ${Date.now() - start}ms`);
return result;
} catch (error) {
console.log(`💥 ${info.fieldName} failed`);
throw error;
}
};
// Wrap your executable schema
const schemaWithLogging = applyMiddleware(await neoSchema.getSchema(), {
Query: logMiddleware,
Mutation: logMiddleware,
});
const server = new ApolloServer({ schema: schemaWithLogging });Each query and mutation is now logged. Your auto-generated resolver is unchanged, but you’ve added custom behavior.
Query the users:
{
users {
name
}
}You should see in your server:
🚀 users started
✅ users completed in 23msEmail Validation Before Database Writes
You can use middleware to enforce specific business rules before data is written to the database. For example, you can ensure that email addresses provided during user creation are valid. By using middleware, you can intercept and validate the input before it reaches the Neo4j GraphQL resolver.
Add a middleware that validates the email input in the createUsers operation. A validation error will be thrown before it reaches the Neo4j GraphQL resolver, and the GraphQL client will receive an error message: “Invalid email addresses detected.”
/* ...existing code... */
const validateEmails = async (resolve, root, args, context, info) => {
// Only check createUsers mutations
if (info.fieldName === "createUsers") {
// Note: This is a simplistic and intentionally flawed email validation example, but good for demonstration purposes.
const invalidEmails = args.input.filter((user) => !user.email.includes("@"));
if (invalidEmails.length > 0) {
throw new Error("Invalid email addresses detected");
}
}
return resolve(root, args, context, info);
};
const schema = applyMiddleware(
await neoSchema.getSchema(),
{
Query: logMiddleware,
Mutation: logMiddleware,
},
{
Mutation: validateEmails,
}Try to create a user with the email not-an-email.com:
mutation createUsers {
createUsers(input: [{ email: "not-an-email.com", name: "simone" }]) {
users {
email
}
}
}Working With Neo4j GraphQL
Most of the above is applicable even outside Neo4j GraphQL, but there’s an important concept when writing middleware for Neo4j GraphQL resolvers.
Here’s the key difference from how traditional GraphQL resolvers are usually built:
- In traditional GraphQL resolvers, each field resolver executes independently, potentially causing multiple database calls.
- In Neo4j GraphQL resolvers, the root field resolver (like users or createUsers) analyzes the entire query tree and executes one optimized Cypher query.
The N+1 problem is solved in Neo4j GraphQL by analyzing the entire GraphQL operation (via the info object) and generating optimized Cypher queries that fetch all requested data in a single database round-trip.
Consider this query:
{
users {
name
email
posts {
title
content
}
}
}Neo4j GraphQL doesn’t execute separate resolvers for name, email, posts, title, and content. Instead, the users field resolver generates and executes a single Cypher query that returns all the data at once. The nested field resolvers simply return the already-fetched data from memory.
Timing Matters
Timing matters for middleware. By the time the individual field resolvers execute, the database has already been queried, and the data is available in the resolver’s result.
Consider the logMiddleware from above:
const logMiddleware = async (resolve, root, args, context, info) => {
const start = Date.now();
console.log(`🚀 ${info.fieldName} started`);
try {
const result = await resolve(root, args, context, info);
console.log(`✅ ${info.fieldName} completed in ${Date.now() - start}ms`);
return result;
} catch (error) {
console.log(`💥 ${info.fieldName} failed: ${error.message}`);
throw error;
}
};Apply logMiddleware to queries and the user’s name:
const schema = applyMiddleware(
schema,
{
Query: logMiddleware, // wraps all the Queries and it's executed before the database round-trip
},
{
User: {
name: logMiddleware, // wraps only the User's name field resolver and it's executed after the database roundtrip
},
}
);Run this query:
query {
users {
name
}
}You should see:
🚀 users started
... Neo4j resolver generates and executes Cypher ...
✅ users completed in 48ms
🚀 name started
✅ name completed in 0msNote how the name resolution happens after the round-trip to the database.
Also note the following differences:
- Query- and mutation-level middleware runs before and after the Neo4j GraphQL autogenerated resolvers.
- Type- and field-level middleware runs only after the Neo4j GraphQL autogenerated resolvers.
Stack Multiple Types of Middleware
It’s possible to apply multiple types of middleware for the same field. For instance, you can apply diverse middleware to the same users resolver:
const schema = applyMiddleware(
schema,
{
Query: {
users: async (resolve, root, args, context, info) => {
console.log("A started");
await resolve(root, args, context, info);
console.log("A completed");
},
},
},
{
Query: {
users: async (resolve, root, args, context, info) => {
console.log("B started");
await resolve(root, args, context, info);
console.log("B completed");
},
},
},
{
Query: {
users: async (resolve, root, args, context, info) => {
console.log("C started");
await resolve(root, args, context, info);
console.log("C completed");
},
},
}
);The order in which middleware is applied is important because they execute in sequence. Each middleware wraps the next one, creating a chain of execution from outermost to innermost.
When you run the query:
query {
users {
name
}
}Server output:
A started
B started
C started
... Neo4j GraphQL user resolver ...
C completed
B completed
A completedThe user’s resolver is wrapped in three layers of middleware.
Summary
GraphQL middleware with Neo4j GraphQL gives you the best of both worlds: the power of auto-generated schemas and the flexibility to inject custom logic exactly where you need it. When you need custom logic, graphql-middleware lets you keep the rapid development benefits of Neo4j GraphQL while adding exactly the custom behavior you need.
The GraphQL ecosystem evolves rapidly. The Guild has developed Envelop with its own graphql-middleware plugin.
This guide uses graphql-middleware because it’s server-agnostic and delivers the clearest path to understanding middleware with Neo4j GraphQL. If you need a more comprehensive plugin ecosystem, we recommend exploring Envelop.
Resources
Using GraphQL Middleware With Neo4j GraphQL was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




