


Modeling Agent Memory

Consulting Engineer, Neo4j
8 min read

How can graphs help us model different types of agent memory?
The migration from isolated LLM calls to agentic systems requires a more thoughtful approach to memory management. As these systems become more dependent on long-term memory, we must develop processes to appropriately handle the different situations and types that may arise.
A talk given by Harrison Chase, CEO of LangChain, at the DeepLearning.AI Dev Day conference inspired the ideas for this post. There, he discussed how LangGraph is approaching memory management and the different types of memory they’re identifying and addressing. While he acknowledged that this is novel territory, the ideas they’re developing are moving the field forward, providing a solid foundation for solving this problem. This article discusses how to implement and expand upon the ideas in Harrison’s presentation in a graph database such as Neo4j.
Please note that this article assumes familiarity with LLM agents and graph databases.
Short-Term Memory
Short-term memory is generally ephemeral and exists within the scope of a single conversation thread. It can contain a history of conversation messages and doesn’t typically require an external database for management. Since short-term memory is usually tied to messages, long conversations can cause performance loss due to high token counts. We can alleviate this by maintaining a window of messages passed to the LLM for processing or generating a summary of previous messages at recurring intervals, which can then pass to the LLM instead. The LangGraph documentation provides more details on how to manage short-term memory.
Long-Term Memory
Long-term memory allows an agent to access information from previous conversations. It can inform improvements to the system, such as iterating on the prompt instructions or few-shot examples. The following memory types are based on our understanding of human memory and contain examples of how it to implement it in a graph database. These examples will be more conceptual than code-based but should provide a framework for your development.
Writing Memory
There are two methods of writing memory: in the hot path and in the background. Writing in the hot path requires memory writing to occur during runtime. This allows updates to be immediately available to the agent and enables better transparency to the end user by exposing these processes. However, comes at the cost of additional processing and possibly increased latency.
Writing in the background provides a separation between the primary application and the memory management system. This allows memory to be updated less regularly, which can lead to de-duplicating work — at the expense of the agent missing potential updates to its knowledge base. Both methods are viable in managing agent memory, and their appropriate usage will be detailed for each memory type below.
Memory Types
Semantic Memory
Semantic memory contains facts about the world. For an agent, this can be information about the user, such as name, age, or relationships to other people. This could also take the form of a collection of documents used in a RAG pipeline. This type of memory requires information to be properly maintained and can change frequently, which leads to complexity in creating, updating, and deleting memories appropriately.
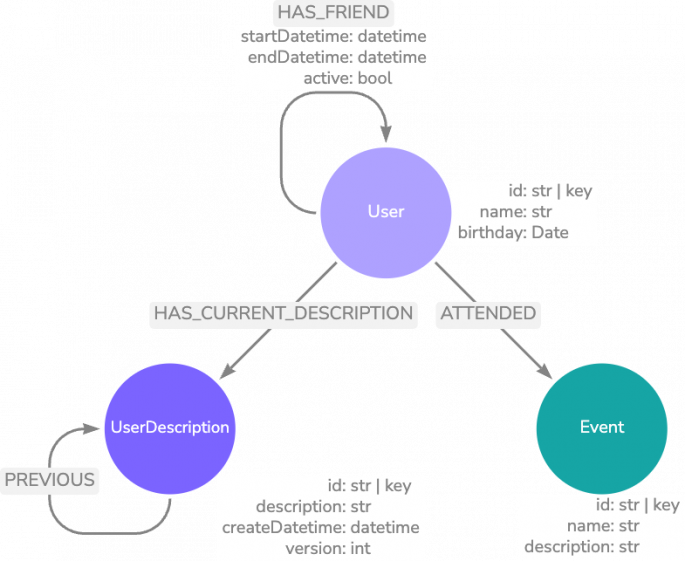
Below is a possible graph data model that contains information about a user profile. In this data model, we also can track the relationships a user has with other users, as well as events they attended.
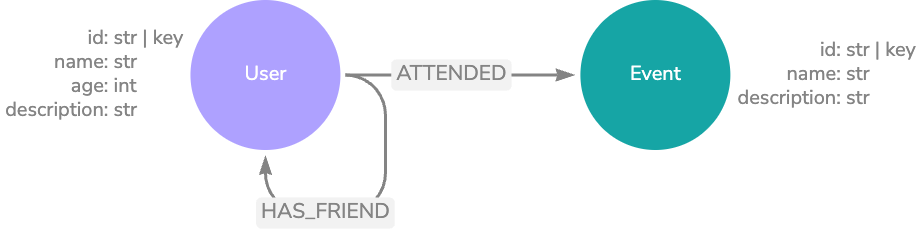
Here’s an example of how this may look in practice. Information about the current user may be retrieved dynamically according to the input question. For example, if the question requires knowledge about what the user does for fun, you can use a query to grab information about events they’ve attended.
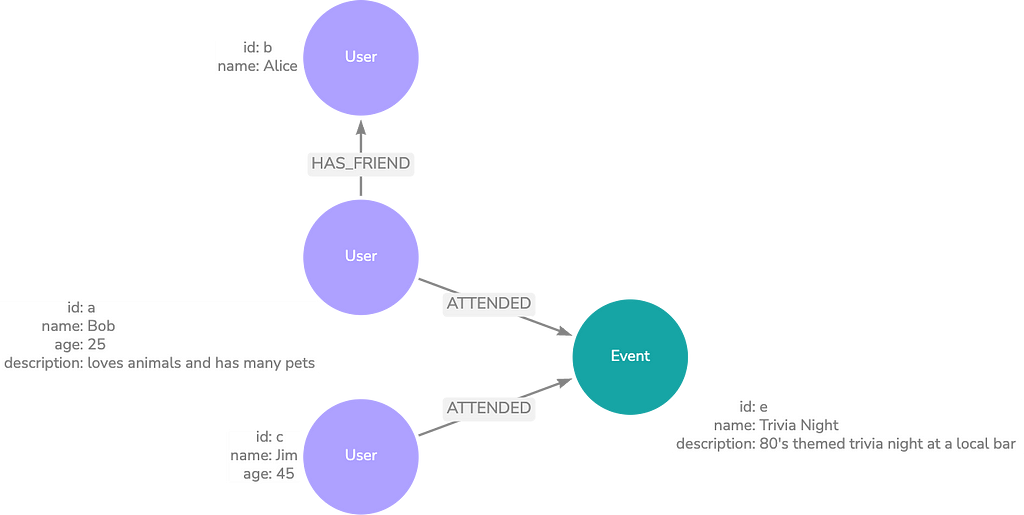
The process of updating these memories may look like this:
- Prepare entities or unstructured text from the conversation to write as memory.
- Search for the top k memories in the database that are similar to the incoming prepared data.
- Identify if there is new or conflicting information in the user query.
- Update the existing memories with new nodes or values.
- Create or delete relationships.
Semantic memory lends itself well to hot-path updating. This prevents the agent from communicating out-of-date information to the user. Since this data is typically used in a RAG pipeline, it poses a risk of delayed writing in the future.
Episodic Memory
Episodic memory stores remembered experiences. These contain information about event details and past agent actions. A common use case for this type of memory is in few-shot prompting. Previous question-answer pairs store in the graph to provide examples in the prompt. Performing a similarity search between the user query and questions in the database accomplishes this.
The image below shows a graph data model that stores user questions and the Cypher query used to retrieve the data. Using similarity search and a simple graph traversal, we can retrieve the top k most relevant examples from the database and inject them into the prompt to inform novel Cypher generation.
Cypher is the query language used to retrieve data in a Neo4j graph database.

Here’s an example of how this may look in practice. A possible retrieval method is to perform a similarity search against the question embeddings in the database and then traverse to the associated Cypher queries. The top k question texts and Cypher query statements return and format into a few-shot examples.
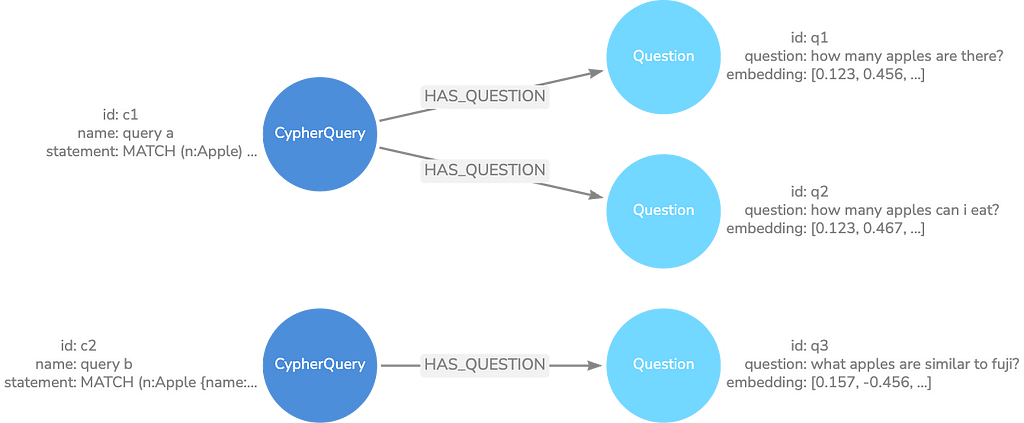
A Cypher query may have many questions. This is because some user questions may differ in explicit text but have the same semantic meaning.
The process of updating these memories may look like this:
- The agent generates a Cypher query to retrieve information from a Neo4j database.
- The user rates the returned result from the agent as good or bad.
- Positive feedback kicks off a process that writes the Cypher query and question to the database to use for future examples.
Episodic memory is better written in the background with receipt of user feedback. This prevents the inclusion of bad or unhelpful memories, which would ultimately diminish performance.
Procedural Memory
Procedural memory stores how to do something. In real life, this type of memory helps us write with a pen or play guitar without thinking about the explicit actions. Through practice, these actions have become internalized in our brains, and we no longer have to think about how to perform them.
For AI systems, procedural memory is a combination of the model weights, code, and prompts. This type of memory is commonly used to store system prompts, tool descriptions, and instructions since the prompts are most accessible to us. These memories can update in a feedback loop from the end user or another system, such as an LLM-as-a-judge. Just as we learned to write through practice and feedback, an agent can learn a task by refining its internal set of instructions.
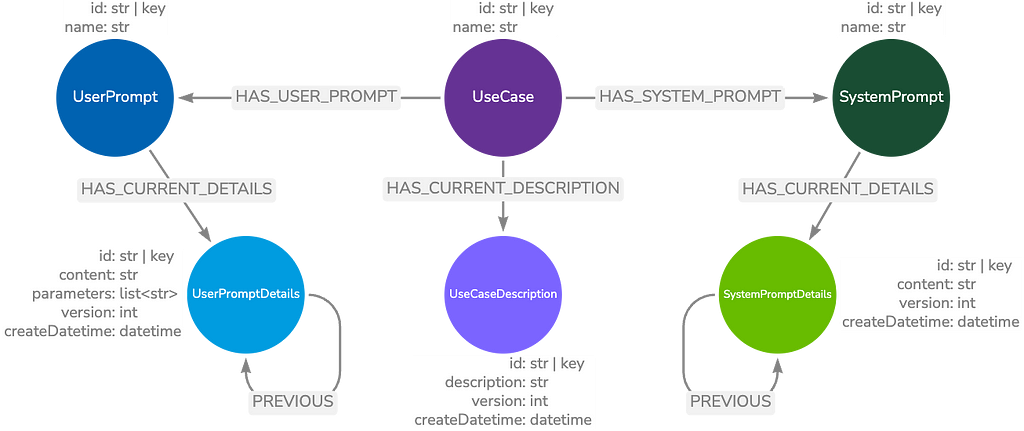
Here, the graph data model stores information about prompts. It contains both system and user prompts for a particular use case.
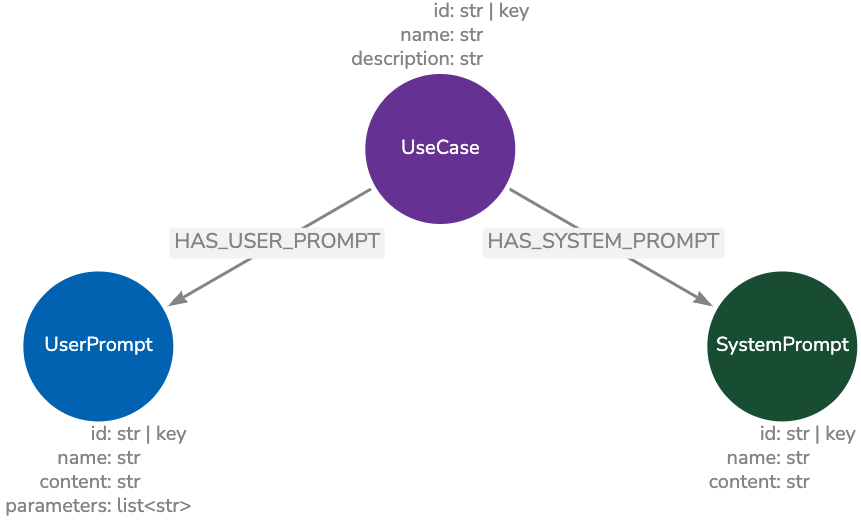
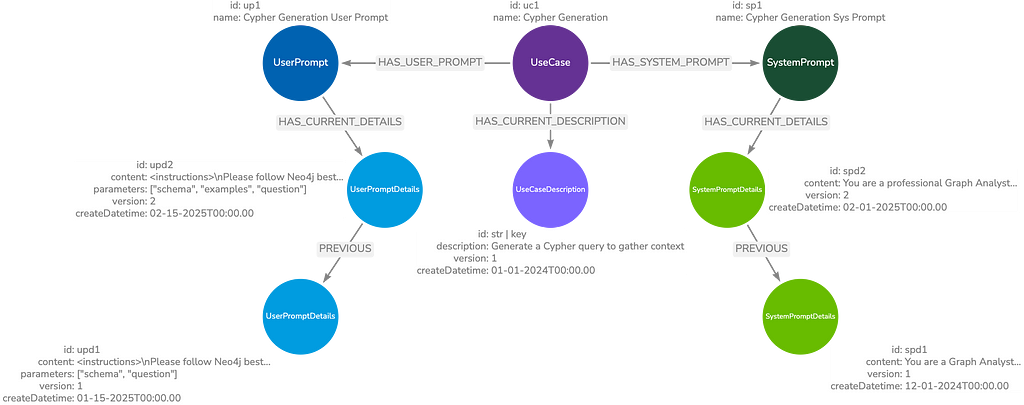
This is how the data may look for a Text2Cypher agent. A possible retrieval strategy is to retrieve these prompts anytime a new chat session starts. This ensures the implementation of any updates made since the previous session.
Note the difference between episodic and procedural memory. In the Cypher generation example, episodic memory recalls the explicit question and Cypher pairs, whereas procedural memory recalls how the Cypher generates.
The process of updating these memories may look like this:
- A series of prompt, answer, and feedback triples collect as input.
- An LLM takes this series and generates a new prompt that adheres to the provided feedback.
- This new prompt writes into the database.
Procedural memory also lends itself well to being written in the background once feedback is received. In the example of improving prompts, it’s probably best to wait until many feedback responses are received so the LLM performing the improvement can align with a more representative sample of the user base.
Temporal Memory
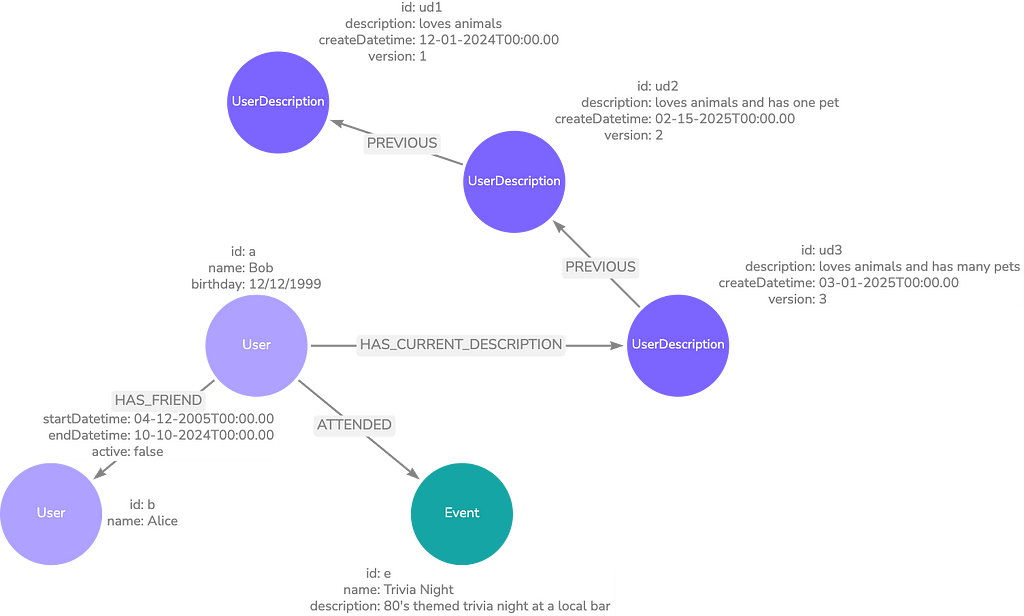
Temporal memory stores how data changes over time. This can apply to any previously discussed type and allows the agent to be aware of how things have changed. In the example of storing the semantic memory of a user profile, we can implement temporal memory in a few ways. One is by including timestamps on HAS_FRIEND relationships with other users to identify the beginning and end of personal relationships. The other is implementing a PREVIOUS relationship between nodes we want to maintain versions of. In the example below, we pull out the user description into its own UserDescription node to track it in this manner. The image below shows the updated user profile data model that incorporates semantic and temporal memory.
We see an applied version of this data where the user description has updates over several months. Notice that the User node only has a HAS_CURRENT_DESCRIPTION relationship with the most up-to-date UserDescription. This makes retrieval easier. We also see that Bob used to be friends with Alice until recently.
Another example would be tracking prompt versions with the procedural memory type. Here, we have a primary prompt node with the prompt name. It connects to a sequence of UserPromptDetails or SystemPromptDetails nodes with a PREVIOUS relationship to the most recent version. This allows the retrieval of the prompt while allowing previous versions to be easily accessible for auditing or reverting changes.
We can see the applied version of this data model for a Text2Cypher agent, where changes in prompt content and parameters are easily accessible.
Summary
Agent memory is one of many rapidly evolving concepts in GenAI. As with many other aspects of AI, it makes sense to base our initial model on how we understand this to work in humans. Harrison and team acknowledge that these ideas around managing memory may change in the future, but this provides an effective way to begin thinking about these concepts.
The data models from this article are on GitHub. And check out the LangGraph memory documentation.
Modeling Agent Memory was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Beyond the Lakehouse: Why Your Microsoft Fabric Strategy Needs Neo4j Graph Intelligence



