


New Cypher AI Procedures

Director of Engineering, Neo4j
21 min read
Aka GraphRAG in Pure Cypher
Aka Solving a Cold Murder Case With GraphRAG
A year and a half ago, I wrote a blog post called GraphRAG in (Almost) Pure Cypher.
It’s now time to remove that “Almost” part from it. Back then, we had to use external functions or client side code to integrate the LLM. Not anymore!
As of December 2025, we have a new package of AI functions and procedures in Cypher and Aura that will do this and more.
NOTE: All the Cypher in this blog uses the CYPHER 25 syntax.
We’ll go through those new functions/procedures, what the differences are and how to use them. But we will of course need a case to demonstrate with. And let’s pick something other than a movie graph this time. Let’s instead aim at solving the biggest murder investigation ever using GraphRAG.
The Unlikely Murderer
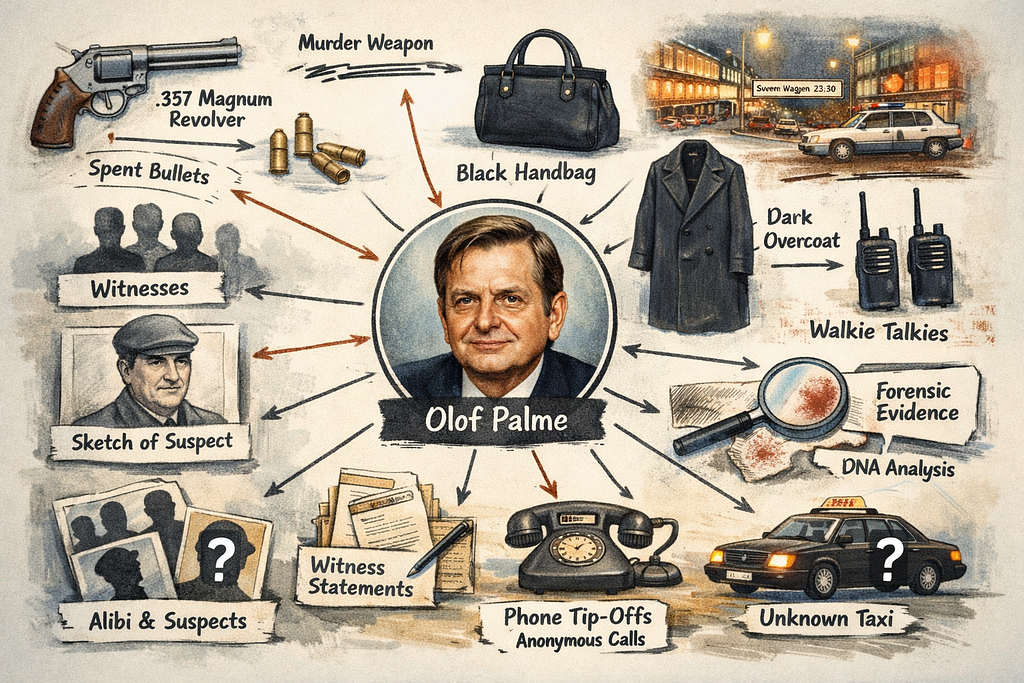
It was approaching midnight on Feb. 28, 1986 in the Swedish capital. The night was chilly, just below freezing, and it had been snowing earlier in the day. Now the snowing had stopped, and there was just a light breeze, but the stars were covered by clouds. The roads were covered by a layer of snow, but the pavements had been cleared up, allowing for a few pedestrians to stroll down Sveavägen, one of the main roads of Stockholm.
Among those pedestrians were an older couple walking hand in hand, heading south on the western side of the road. This was Olof Palme, the prime minister of Sweden, together with his wife, Lisbeth, who were heading home from seeing The Mozart Brothers movie at the Grand movie theater. Olof had relieved the security detail, telling them that they wanted to go on their own— this was Sweden after all.

The walk from Grand to their home in the Old Town of Stockholm was about 2 km and would take about half an hour, which must have been cold this winter midnight. But the prime minister and his wife enjoyed the crisp air and the walk.
At the church of Fredrik Adolf, they crossed the street to the eastern side. It has been speculated whether this was because of the snow on the western side, or if there was another purpose, but we’ll probably never know. At 23:21, they reached Tunnelgatan, a small street to the left and a paint shop called Dekorima on the corner of Sveavägen and Tunnelgatan. Just as they had passed Dekorima, a man came up behind them, put a Smith & Wesson .357 Magnum revolver against Olof’s back and shot him in the spine at point blank range. He was dead before he reached the pavement. The man fired another shot against Lisbeth, lightly wounding her, before he fled down Tunnelgatan, crossing Luntmakargatan and up the stairs leading to Malmskillnadsgatan. And from there nothing conclusive is known.

This event spawned the largest police investigation ever, not only in Sweden, but worldwide. An investigation consisting of half a million pages, or 3,600 meters of shelf space. There were more than 10,000 witnesses interviewed during the course of 34 years. There would be several individual suspects, as well as conspiracy theories directed towards the Kurdish PKK, South Africa, and even the CIA. Trials were held, but without anyone convicted (well, the small-time criminal Christer Pettersson was found guilty in the first instance, but was acquitted in the higher instance).
In February 2020, the prosecutor of the case at the time, Krister Petersson (him having almost the same name as the prime suspect is a pure coincidence— they say), dropped a bomb. He said that before the first half of 2020 was over he would either prosecute someone or close the case. The population of Sweden held their breath (which is a feat to do for five months).
So came June 10, the day of the press conference. A press conference that could serve as the definition of anticlimax. To the surprise of most he did close the case, but while doing so he also presented a suspect, a suspect that could not defend himself because he was no longer alive. Krister said that the investigation could not get around this person, Stig Engström, and without the possibility to interrogate him, they closed the investigation. The big surprise was that they mentioned him by name, without being convicted of a crime.

In 2021, Netflix did a series called “The Unlikely Murderer” that assumed Stig was the murderer, and this is based on a novel with the same name by Thomas Pettersson (yes, that same surname once again) written already in 2018, even before the press conference. But many others, like Gunnar Wall, who wrote “Rättskandalen Olof Palme: mordet, syndabocken och hemligeterna” (“The Olof Palme legal scandal: the murder, the scapegoat and the secrets”) in 2023 claims the opposite.
Either way, the closing of the investigation meant that the entire police investigation, all those half a million pages, became public. Which in turn has spawned a large community of self-made investigators. And it also enables us to use a graph.
New AI Procedures
Let’s leave murders for a bit and get back to Neo4j, AI, and Cypher. We had some minimal support for embedding generation in Cypher, and other LLM API procedures in APOC. To enable everyone to use more AI capabilities directly from Cypher, we’re introducing a new top-level namespace ai.* and a cohesive set of functions and procedures that bring the previously split functionality into one place.
The support for vector indexes and vector search was introduced in Neo4j in the summer of 2023. Vectors were, at the time, represented as lists of floats. To use vectors, you needed a way to make the vector embeddings, and for this we introduce one function (genai.vector.encode) and one procedure (genai.vector.encodeBatch).
Those were wrappers for the API of the different AI providers like OpenAI, Vertex AI, and Amazon Bedrock. But there was no access for their other APIs, like text completions (hence the “Almost pure cypher” in my earlier blog). This has now changed.
At the end of 2025, Neo4j introduced vectors as a native data type as opposed to being just a list of floats. Those vector types have a dimension and precision and can be processed and stored more efficiently in the future.
Introducing Neo4j’s Native Vector Data Type
To make use of this new data type, new functions/procedures were needed. genai.vector.encode and genai.vector.encodeBatch are still there for backward-compatibility, but in the 2025.11 release, we added this new surface for embedding generation (documentation):
- ai.text.embed
- ai.text.embedBatch
- ai.text.embed.providers
Here’s an example on how you could use it:
MATCH (m:Movie)
// set vector embedding value
SET m.embedding = ai.text.embed(m.title + ' ' + m.plot,
'OpenAI', { token: $apiKey, model: 'text-embedding-3-small' })And for text generation (documentation):
- ai.text.completion
- ai.text.completion.providers
Note: Those bold are procedures and the others are functions.
The new vector type is now the output type, allowing for seamless interoperability, but that’s not the only difference. Here are some more:
- Naming
They use the ai.* namespace instead of genai.*. There’s also a more strict and consistent naming scheme that will make the addition of more functions/procedures easier. They’re all in the form of ai.[noun].[action] where the noun is either the subject or the predicate of what is operated on or returned and then follows what to do with it (and sometimes with a fourth part for meta-procedures). - Extending the library
Where the old were only meant to enable the creation of vectors, the goal now is to extend the namespace with more API wrapper and AI helpers over time. In the first release, we have the ai.text.completion, which enables the full GraphRAG experience in Cypher, but there’s more to come. - Less strict on models
The legacy functions/procedures only accepted the models that were known at the time of implementation, where the new are more open and accept any model name that the backing API will accept. With a domain that is changing so rapidly, this is crucial. - No default model
With the old functions/procedures, you didn’t have to specify a model name, there was a default, but now you have to. This could be seen as a regression of usability, but it’s actually the opposite. In the rapidly changing world of AI, models get deprecated. If that happens with the one that was set as default, the default would have to be changed, and the user wouldn’t notice. Instead, the vector search would just stop working as the embeddings done later on the questions would no longer match the embeddings stored, and you wouldn’t know why. By having a model explicitly defined you would instead get an error, so that you can upgrade the stored embeddings.
Documentation for both sets can be found here:
For this blog, I’ll use OpenAI as provider, which only has two required parameters: the API key (token) and the model. I’ll use the text-embedding-3-small model for the embeddings and GPT-5.2 for text completions.
Some actual example usage will follow in next chapter.
Solving a Murder With GraphRAG
Cypher 25
To begin with, all the Cypher in this blog uses the CYPHER 25 syntax. You can check your default language with:
SHOW DATABASES YIELD name, defaultLanguageIf your database (e.g., neo4j) is running CYPHER 5, you can change it with:
ALTER DATABASE neo4j SET DEFAULT LANGUAGE CYPHER 25If you don’t want to change the default for all queries, you can prefix the queries with CYPHER 25:
CYPHER 25
MATCH ...Creating the Graph
To take on this cold case with GraphRAG, we need a graph. As I wrote, the investigation is now public, but that’s not as good as it may seem. To get it, you need to make a request for each file you want, which has a cost (2 SEK per page). And the documents will be redacted, to remove sensitive and personal information. Getting all the files would cost about USD $100,000 and take a long time, and you would still just get it in paper format (even though the investigation is digitized these days, they are only managing public requests in paper form).

There are others who have already done so, if only for just a small subset of the investigation, and some even made it public, in digital format online. One of the biggest ones is wpu.nu.
Fortunately for us, it’s in a wiki format, and a wiki is, as we all know, a graph. So importing all of that into a graph isn’t too hard.

I only created Pages and Categories in the structure of the wiki. We can improve this further by having an LLM extract entities like Persons, Suspects, Witnesses etc., but let’s keep it simple for now.
To use vector search on our graph, we need to add a vector index. This still has the same syntax as before and is done like this:
CREATE VECTOR INDEX page_embeddings IF NOT EXISTS
FOR (p:Page) ON (p.embedding)Now we can use the new procedure to create a vector embedding for all of the pages (we need to have our OpenAI API key in the parameter $apiKey):
MATCH (p:Page)
WHERE p.plain_text IS NOT NULL AND size(p.plain_text) > 0
SET p.embedding = ai.text.embed(p.plain_text, "OpenAI",
{token: $apiKey, model: "text-embedding-3-small"})However, the above query makes one API call for every node in our graph, which is inefficient. When you have multiple embeddings to do, it is better to use the batch procedure:
MATCH (p:Page)
WHERE p.plain_text IS NOT NULL
WITH collect(p.plain_text) AS texts, collect(p) AS pages
CALL ai.text.embedBatch(
texts,
"OpenAI",
{token: $apiKey, model: "text-embedding-3-small"}
) YIELD index, resource, vector
SET (pages[index]).embedding = vectorThis query will fail on this dataset though, since there is a limit of a total of 300,000 tokens per batch, and we have more than four times that. So we’ll batch the calls in batches of 400 pages (chosen because it is a fifth of the data set, so should keep us below the limit):
MATCH (p:Page)
WHERE p.plain_text IS NOT NULL AND size(p.plain_text) > 0
WITH collect(p) AS pages
WITH [i IN range(0, size(pages) - 1, 400) | pages[i..i + 400]] AS batches
UNWIND batches AS batch
CALL(batch) {
UNWIND batch AS page
WITH collect(page.plain_text) AS texts, collect(page) AS pages
CALL ai.text.embedBatch(
texts,
"OpenAI",
{token: $apiKey, model: "text-embedding-3-small"}
) YIELD index, resource, vector
SET (pages[index]).embedding = vector
}GraphRAG
I won’t go through what GraphRAG is, but you can read more on that in my earlier blog, linked above. But just to recap, the main parts of a GraphRAG flow are:
- Embed the user question as a vector
- Do a vector search to find the most relevant document(s) as entry points into your graph
- Do a graph traversal to find neighboring documents that provide the LLM with more complete context
- Ask the question to the LLM, providing all the documents as context for the question, asking it to answer only based on that context
So let’s take it from the top and do the Cypher needed, using the new AI procedures, to do our cold murder case chatting. The first step would be to embed the question (that we have in a parameter called $question):
WITH ai.text.embed($question, "OpenAI",
{token: $apiKey, model: "text-embedding-3-small"})
AS embeddingSecond step was to do the vector search. Here I will find the top two most relevant nodes (you’ll see why later), but having the vector search return the top 20 approximate hits first to increase accuracy (the vector search itself is done with approximate nearest neighbor, and this way we make it less approximate):
CALL db.index.vector.queryNodes(
'page_embeddings',
20,
embedding)
YIELD node AS page, score
WITH page, score ORDER BY score DESC LIMIT 2A small sidetrack here: As you see, the vector search is done as a procedure call, which is what was introduced when vectors were introduced in 2023. Early next year (2026) you’ll see new language support for working with vector search and combining it with other forms of filtering and more embedded in the Cypher language itself.
Now we get to the third part, which the most interesting part of GraphRAG, and also where we can make the most tweaking and improvement of our results: the graph traversal.
As we saw above, I asked for the top two best matches from the vector search. The first thing I will do is to take everything linked to or from these pages. But then I will also (and this is where we will get the most benefit from the graph) try to find the shortest paths between these two pages, assuming that there will be relevant clues to find there.
We achieve this with a subquery that does a union between the different traversals we want to do:
WITH collect(page) AS pages
CALL(pages) {
UNWIND pages AS page
RETURN page
UNION ALL
UNWIND pages AS p
MATCH (p)-[:LINKS_TO]-(page:Page)
RETURN page
UNION ALL
WITH pages[0] AS p1, pages[1] AS p2
MATCH path = ALL SHORTEST (p1)((:Page)-[:LINKS_TO]-(:Page)){0,4}(p2)
UNWIND nodes(path) AS page
RETURN page
}We’ll look at what this subgraph could look like in next chapter when we take this for a test run.
Before going to the last part, we need to build a context string from all these pages (but limited to the top 20 most occurring ones to avoid overflowing the context window):
WITH page, count(*) as freq ORDER BY freq DESC LIMIT 20
WITH collect("PAGE: " + page.title + "n" + page.plain_text) AS texts
WITH reduce(
context = "",
text IN texts |
context + CASE WHEN context = "" THEN "" ELSE "nn" END + text
) AS contextAnd now we’re at the final step: querying the LLM to get the answer to our question based on the context we just gathered. This is the part that you couldn’t do in Cypher before (without turning to APOC Extended, which isn’t available in Aura). But now with ai.text.completion, we can:
RETURN ai.text.completion(
"Answer the following Question about the Olof Palme murder based on the Context "+
" only and provide a reference to where in the context you found it. "+
" Only answer from the Context. If you don't know the answer, say "+
"'I don't know'.nnQuestion: "
+ $question + "nnContext:nn" + context,
"OpenAI",
{
token: $apiKey,
model: "gpt-5.2"
}
) AS resultHere is the full query with all the parts together:
// Embed the question into a vector
WITH ai.text.embed($question, "OpenAI",
{token: $apiKey, model: "text-embedding-3-small"})
AS embedding
// Find the two most relevant pages (with the most similar vectors)
CALL db.index.vector.queryNodes(
'page_embeddings',
20,
embedding)
YIELD node AS page, score
WITH page, score ORDER BY score DESC LIMIT 2
// Do a graph traversal from those two nodes
WITH collect(page) AS pages
CALL(pages) {
UNWIND pages AS page
RETURN page
UNION ALL
UNWIND pages AS p
MATCH (p)-[:LINKS_TO]-(page:Page)
RETURN page
UNION ALL
WITH pages[0] AS p1, pages[1] AS p2
MATCH path = ALL SHORTEST (p1)((:Page)-[:LINKS_TO]-(:Page)){0,4}(p2)
UNWIND nodes(path) AS page
RETURN page
}
// Create the context as a string
WITH page, count(*) as freq ORDER BY freq DESC LIMIT 20
WITH collect("PAGE: " + page.title + "n" + page.plain_text) AS texts
WITH reduce(
context = "",
text IN texts |
context + CASE WHEN context = "" THEN "" ELSE "nn" END + text
) AS context
// Query the LLM based on the question and the context
RETURN ai.text.completion(
"Answer the following Question about the Olof Palme murder based on the Context "+
" only and provide a reference to where in the context you found it. "+
" Only answer from the Context. If you don't know the answer, say "+
"'I don't know'.nnQuestion: "
+ $question + "nnContext:nn" + context,
"OpenAI",
{
token: $apiKey,
model: "gpt-5.2"
}
) AS resultSolving the Murder
Let’s put our GraphRAG query to the test with this question:
How likely does it seem to be that Stig Engström really murdered Olof Palme?
We do that by populating the parameters like this before running the query above:
:param {
question: "How likely does it seem to be that Stig Engström really murdered Olof Palme?",
apiKey: ***
}The traversed graph used as the context for this question, after the vector search and the traversal, looks like this:
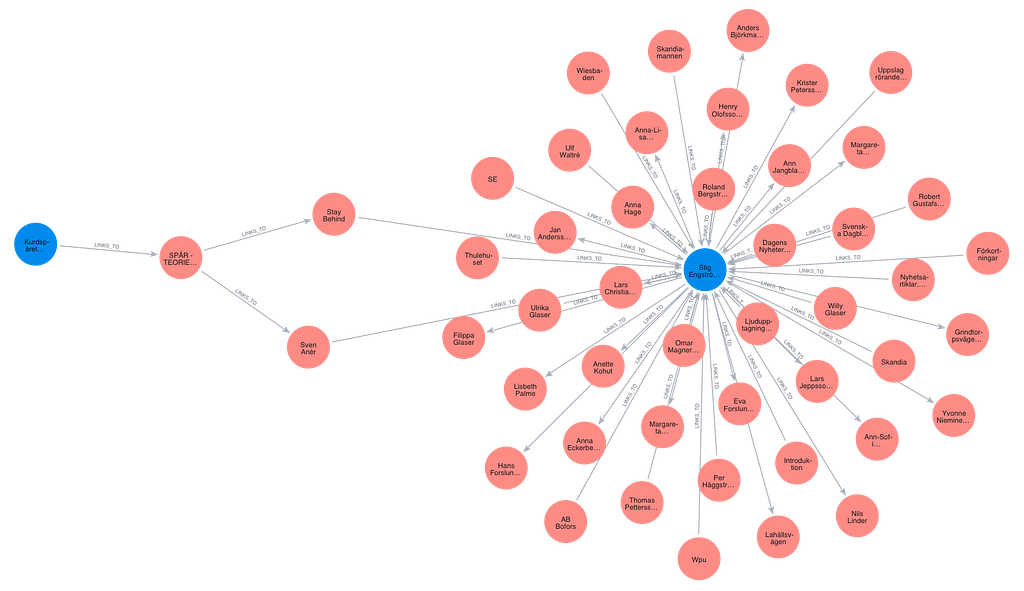
Before looking at the result, let’s talk about languages. The questions I ask are in English, but most pages in the graph are in Swedish. This is perfectly ok since the embedding model we use (text-embedding-3-small) is multilingual, the vectors represent the content independent of language, and so is the text completion model (GPT-5.2), so we can chat in English even though the documents are in Swedish.
The answer we get back is:
It seems uncertain how likely it is that Stig Engström really murdered Olof Palme. The Palme investigation identified Engström as a reasonable suspect in 2020, but his role at the scene of the murder is unclear and no final verdict has been established, as he was deceased when the preliminary investigation was closed. Testimony and theories provide conflicting pictures: Engström may have been an exaggerated witness, a possible perpetrator or a passive witness. It is also discussed that he may have had access to weapons through a friend, but the evidence is unclear. In summary, his role in the incident is very uncertain and no conclusive evidence has been presented against him.
Reference: Stig Engström page, especially the sections “Mordkvällen och utredningen” and “Sammanfattning av status”, as well as the page “SPÅR — TEORIER”.
OK, nothing conclusive, but at least it seems to indicate that we shouldn’t be as certain about Stig’s guilt as the prosecution seemed to indicate when they closed the investigation. Let’s now see if we can get a definitive answer:
Can you tell us who murdered Olof Palme?
And the answer:
I don’t know.
In the context, there is no definitive or final identification of who murdered Olof Palme. A variety of different clues, theories, suspects and conspiracies are consumed, but no personal identity is established as the proven murderer. Several people and groups are pointed out in different scenarios; for example, the PKK clue, the Police clue, Stay Behind, the South Africa clue, Christer Pettersson, etc. are mentioned. But no one has been identified with final certainty as the perpetrator based on the available material in this context.
Reference: See all sections under “SPÅR — TEORIER”, “I utredningen (sammanfattning)” on the page “Olof Palme”, and the summary under “Granskningskommissionen” as well as the page “SOU 1999:88”.
Summary
What a bummer. Turns out we couldn’t solve the murder of the Swedish prime minister. But I guess that’s a relief for the Swedish police who spent 34 years and more money than any other police investigation on it. Would have been a bit embarrassing if I had solved it in a few hours.
But at least we got to learn how to use the new Cypher AI procedures.
Joking aside, I think this could be a very powerful tool. In our case, we only had around 2,000 documents out of half a million. Just at the end of the investigation, they did digitize the material, which was a great benefit for the possibility of searching the material, but that was just before they closed it.
Based on that, with all the uncensored documents in digital form, one could have built a really comprehensive graph of it. And I do believe that an LLM together with GraphRAG and specialized agents would have been able to open some new paths in the investigation, even if it wouldn’t give them the answer in black and white.
One thing we could see in our tests here was that the most interesting references in the answers provided did not come from the nodes directly neighboring those returned from the vector search, but in the shortest path between the two nodes, which shows why GraphRAG works best on an actual graph source (which can easily do those more advanced traversals).

A final side note: Just as I clicked the button to send this blog for review I got a push from my news service that the current chief prosecutor Lennart Guné would hold a press conference. There he said that he would change the reason for having the investigation closed, that it would not be because Stig Engström is a suspect, but instead that it’s because it isn’t likely that the case would be resolved. This makes it easier to reopen the investigation if new evidence should surface, and it also acquits Stig Engström as a suspect. Quite the coincidence that this happened (after five years without hearing anything), just as I finished this blog.
New Cypher AI procedures was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



