
Discovering Hidden Skills with an Enterprise Knowledge Graph


5 min read

Within a growing organization, finding the right information can take up a good part of your day.
As teams and people become more spread out, both geographically and organizationally, knowledge becomes exponentially harder to find. In addition, when you’re busy, doing work often gets prioritized over sharing knowledge. Getting your internal information into a knowledge graph helps mitigate these issues, allowing you to focus on what’s important for your business.
Even though apps like Slack and Microsoft Teams are helping us to centralize our knowledge, the data is still virtually unstructured, obfuscating the real value embedded in thousands of messages, documents, blog posts and emails. Looking through these often feels like a treasure hunt, taking up a ton of time we’d rather use for building new things.
In this post, we solve these information-sharing issues by using Neo4j to build, store and analyze an enterprise knowledge graph.
A knowledge graph can be used to identify the relationships between the different entities in your company (people, skills, files) and make them easily analyzable from a single endpoint, such as a web app. By dynamically inferring structure from this unstructured pile of information, you cut out the hunt and skip to the treasure right away.
Knowledge Graphs in the Wild
Knowledge graphs have been widely used by organizations to make sense of their data. Some have used knowledge graphs to revolutionize the way we search the web, and others use knowledge graphs to get to space. Unsurprisingly, the hype for knowledge graphs is real – and is likely to increase in the near future.
Fundamentally, all knowledge graphs serve a similar purpose: structuring information in order to simplify searching your data.
With a knowledge graph in place, data can be enriched with more information derived from the network structure itself. This newly discovered context is where knowledge graphs shine, by providing completely new insights into your existing information.
In the case of our enterprise knowledge graph, we focus on modeling people, documents, messages and their relationships. Once those are in the database, we use this information to enrich the graph with skills and link people to their skills based on the content they created.
Building our Slack Knowledge Graph
Neo4j as a company sends over 50,000 messages every single month through our internal company Slack channels – everything from communication around a particular client or project to niche features of the product. Messages are part of channels, with responses containing a variety of links, attachments and emojis.
This data is naturally represented in a graph:
The data model used for the Slack knowledge graph data.
Let’s say we want to find a User sending a Message in a Channel mentioning a certain Skill. Using Cypher it would look something like this:
MATCH (user:User)-[:SENDS_MESSAGE]->(message:Message)-[:POSTED_IN]->>(channel:Channel),
(message)-[:MENTIONS_SKILL]->(skill:Skill { name: “apoc” })
RETURN user, message, channel, skill
Using the Slack Knowledge Graph: Determining Our Skills
Using our newly built knowledge graph, we determine our user’s skill levels dynamically by looking at their Slack interactions. We use a number of metrics to determine a “skill score” for each user, for example:
- Using natural language processing (NLP) techniques to extract common word sequences and map them to an internal skills hierarchy. For example, if someone is commonly talking in a channel dedicated to the Cypher query language and is mentioning the
UNION ALLcommand, we can assume they’ll be a good candidate to answer our question on map comprehensions. - Next, we check how other people respond to a user’s messages. If someone answers a question and gets many positive responses, either in text or by using emojis, their answer will get extra points, resulting in more “skill points” for that user.
- Similarly, if a user is commonly mentioned in close proximity to the name of a particular client, they may know more about the status of the projects of that client. If such a project requires a certain skill, the user also gets more points in that skill.
This scoring method was implemented using Python and the Neo4j driver library, which makes it easy to retrieve/store data using Cypher. From our generated Python dataframe with skill levels, we write back to Neo4j:
driver = NeoDriver(url, user, password)
for user in output:
for skill in output[user]:
score = output[user][skill]["skill_score"]
create_query = """
MATCH (u:User{name: $user}), (s:Skill {name: $skill})
MERGE (u)-[:HAS_SKILL {weight: $weight}]->(s)
"""
driver.query(create_query, user=user, skill=skill, weight=score)

An example of how a message and a reply are modeled in the graph. Here, the initial message refers to the skill Cypher (being posted in a dedicated cypher-genius-bar channel), resulting in the replier (Michael) also getting points in the skill.
Data Loading and Architecture
Slack makes their workspace information available via bulk exports and API’s. In our case, we fed the information through a set of Kettle transformations and jobs before persisting it into a Neo4j AuraDB cluster. Once there, a number of Python scripts are run periodically to add structure around the messages before assigning scores to users against a predefined skill hierarchy.
Besides Slack information, we added data from Github, Google Drive and Salesforce, which can be linked to the hyperlinks posted in Slack. Then, if someone mentions a Google Drive document, we can parse that document for relevant information as well.
After loading the data into Neo4j AuraDB using Kettle and Python, our custom graph app in Neo4j Desktop acts as the main way for users to explore the data.
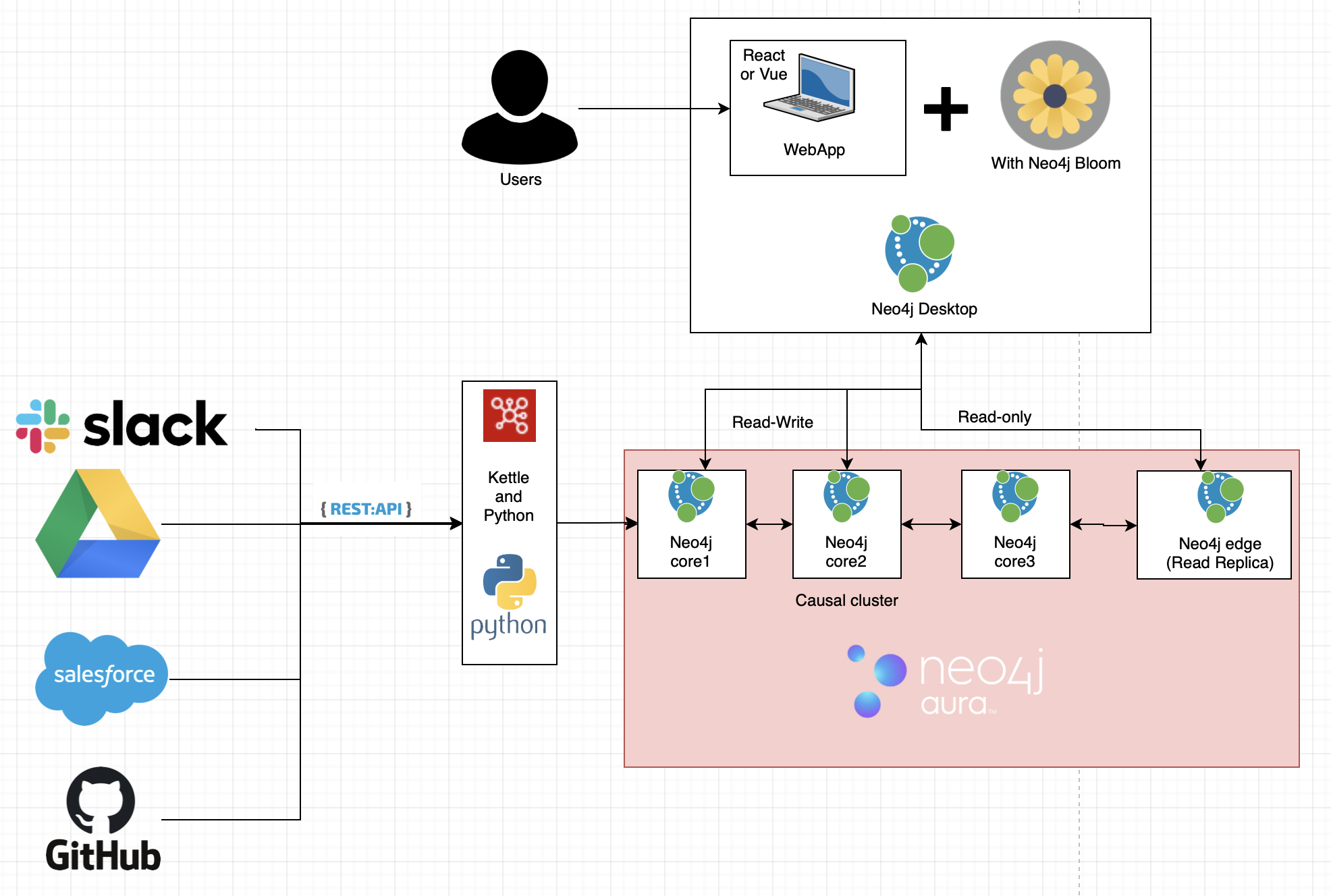
An overview of the architecture of the application built around the Slack knowledge graph.
Search and Analysis: Building a Custom Dashboard
Collecting this data is all well and good but if it cannot be used in a convenient way it simply will not be used. Having the luxury of using this data internally, we were able to quickly develop a UI as a Graph App and deploy it internally via Neo4j Desktop.
The UI not only identifies the users and skills that are most prominent within the company but also identify the skills that are lacking. As messages are time-based, we’re also able to identify the latest trends and see how mentions of particular technology stacks have changed over time.
Wrapping Up
We have shown how to design, construct and use a knowledge graph based on Neo4j’s internal Slack history. By structuring our data as a graph, we’re able to gather new, contextual information that generates new (otherwise hidden) insights into our organization, skill levels for each of our users.
In short, knowledge graphs are an amazing tool for driving change through data analysis – getting the most out of the data you already have!
Share Article



Explore
Related Articles



How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs


