Doctor.ai, a voice chatbot for healthcare, powered by Neo4j and AWS

Triple Neo4j-Certified Bioinformatic Data Scientist and Tech Writer
10 min read
By Sixing Huang, Derek Ding, Emil Pastor, Irwan Butar Butar, and Shiny Zhu
Supported by Maruthi Prithivirajan, Joshua Yu, and Daniel Ng from Neo4j
Big data, machine learning, cloud, and graph databases are transforming the healthcare industry. A vast amount of relation-rich medical data is stored in graph databases on the cloud and processed by machine learning. As a result, we gain a deeper understanding of the human body. This knowledge will lead to better prevention, more accurate diagnoses, and more effective treatments.
The technological advance also democratizes healthcare. It not only lowers the cost and makes medical procedures more efficient and widespread so that people with lower income can benefit, but it also makes both private and public medical data more accessible to everybody. The latter point is often overlooked. As Eric Topol put it in his book Deep Medicine:


This information asymmetry generally puts the patients at a disadvantage. Without full access to their own medical records and research results, let alone the software tools that make sense of the data, the patients are completely dependent on the doctors. In this case, only the doctors decide the prevention, diagnosis, and treatment. And many times even the doctors suffer from limited access to data.
On the one hand, without digitization, hand-written medical records and images are not readily available and transferable between doctors. That can lead to wasteful duplications of administrative works and medical procedures. On the other hand, the newest medical research spreads so slowly across the profession that many doctors can hardly benefit from it.
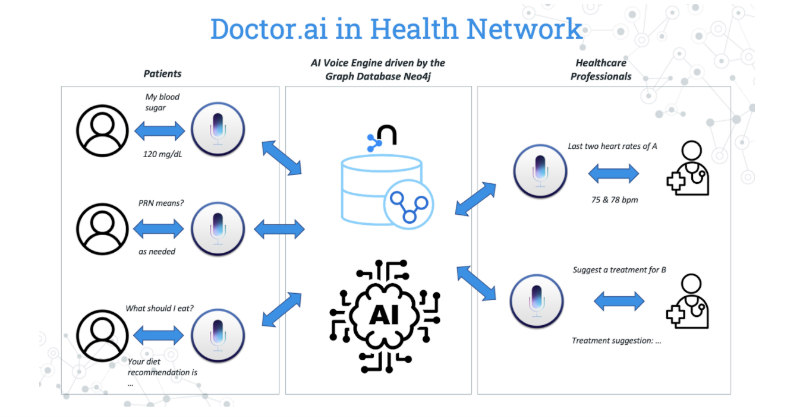
With this conviction and the inspiration from Deep Medicine, four Neo4j engineers and I made Doctor.ai in the Singapore Healthcare AI Datathon and EXPO 2021. It is a voice virtual assistant powered by the graph database Neo4j and AWS. This assistant can map a large amount of medical records to a graph and use the Graph Data Science (GDS) library to recommend treatments.
AWS Lex is the eye, mouth, and ear of Doctor.ai. It takes in voice or written inputs from the user and queries the Neo4j graph via Lambda. Finally, we have put together a React frontend on AWS Amplify for easy interactions.
Figure 1: The concept of Doctor.ai.
Although Doctor.ai is just a small datathon project, it does contain many technical highlights that are worth sharing. In a previous article, I documented all the setup steps for Doctor.ai. In this article, I am going to give you a more detailed overview of the inner workings of the chatbot.
The stand-in data, architecture, and inner workings of Doctor.ai
We used the eICU database to develop Doctor.ai. It is a collection of 200,000 ICU records from more than 139,000 patients between 2014 and 2015 in the United States. It contains dozens of tables. In addition, a pre-processed database eicu_crd_derived exists alongside the original. We can find lab results, diagnoses, treatments, demographic information, and other metadata in the database. In the datathon, we imported all these pieces of information out of six tables into Neo4j (Figure 2). Together, they give us a comprehensive picture of each ICU stay.
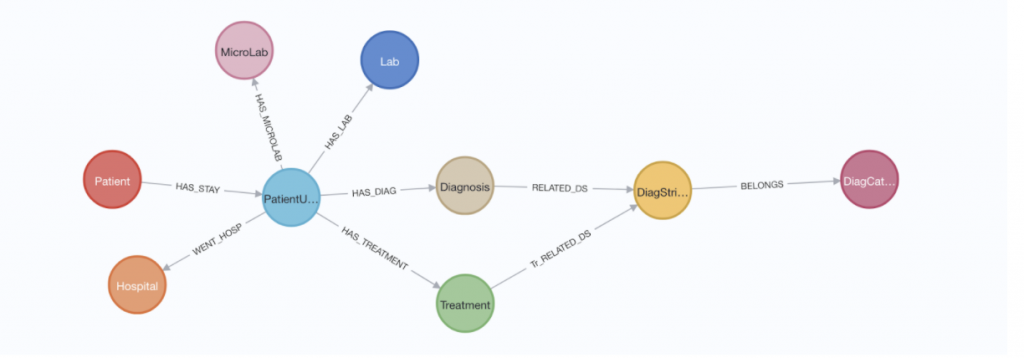
Figure 2: The Neo4j data model for Doctor.ai.
Meanwhile, we began to construct the infrastructure on AWS. Instead of AuraDB or the Neo4j public AMI, we opted for a customized Neo4j installation on an EC2 instance, because the AMI default settings were too constrained. Lex was the natural language understanding engine behind Doctor.ai. To query the Neo4j database, the user dictated or typed the questions to Doctor.ai. Once the user intent was understood, Lex triggered the Lambda function to carry out queries against Neo4j. A CI/CD react frontend based on React Simple Chatbot by Lucas Bassetti was hosted on Amplify to serve the clients (Figure 3).
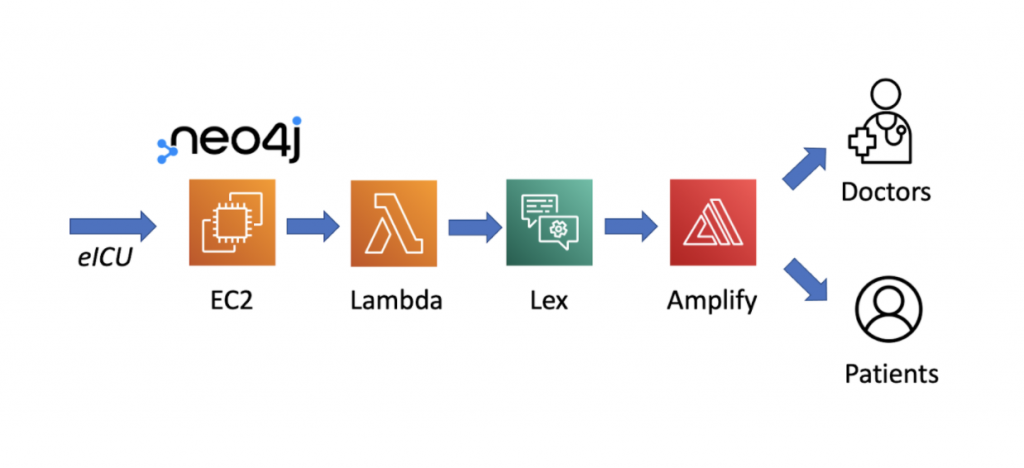
Figure 3: The AWS architecture of Doctor.ai.
The setup of EC2 and Amplify was quite straightforward. Most of the coding took place in Lex and Lambda. Lex may give the wrong impression that it can understand every casual conversation with some AI magic. The reality is that Lex is a specialized bot. It can only understand some predefined intents, and we the programmers need to implement each one of them.
Intent, utterance, and slot are three concepts that need some explanation. Intent is a wish that the user wants the chatbot to fulfil. For example, the user may want to count how many ICU visits a patient has had. To fulfil it, the user must dictate a language expression to the chatbot. And that language expression is an utterance.
For example, the user can utter “How many times has patient ABC visited the ICU?” or “Tell me the counts of patient ABC’s ICU visits.” Both are going after the ICU visit counts of patient ABC. In this case, the name of the patient is a slot. We use slots to constrain our query. A slot needs a value from the current or the previous utterance. Otherwise, Doctor.ai will raise a follow-up question about it. Once the name of the patient is known, Doctor.ai will try to calculate the ICU visit counts.
In Lex, intents are defined in the “Intents” page of the chatbot (Figure 4). Each intent mainly consists of sample utterances, slots, and fulfilment actions. When a user dictates or types some utterance to Doctor.ai, Doctor.ai will try to classify the user’s intent. If the classification is successful and all the slots are filled, Doctor.ai will carry out the fulfilment actions. Finally, we need to define a fallback intent when the user’s intent is not clear.
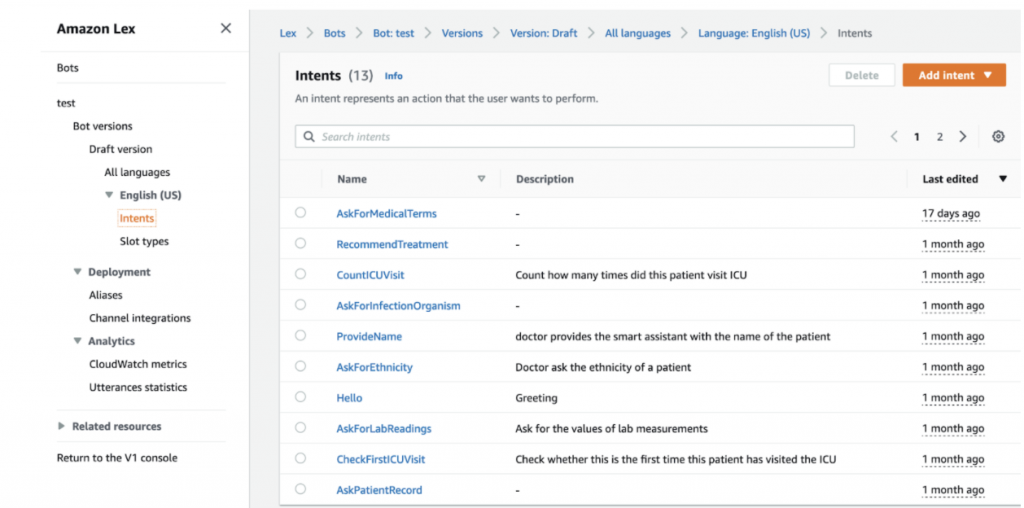
Figure 4: The “Intents” page of the Doctor.ai.
Let’s learn how to set up intents by going through the “CountICUVisit” intent. This intent is about how many times a patient visited the ICU. First, we defined eight sample utterances – that is, a user likely utters one of these expressions in order to have this intent fulfilled. Lex learns through these samples so that it will recognize other similar utterances in production. Because we just want to know the visit count of one patient, we set the patient’s name as the slot.
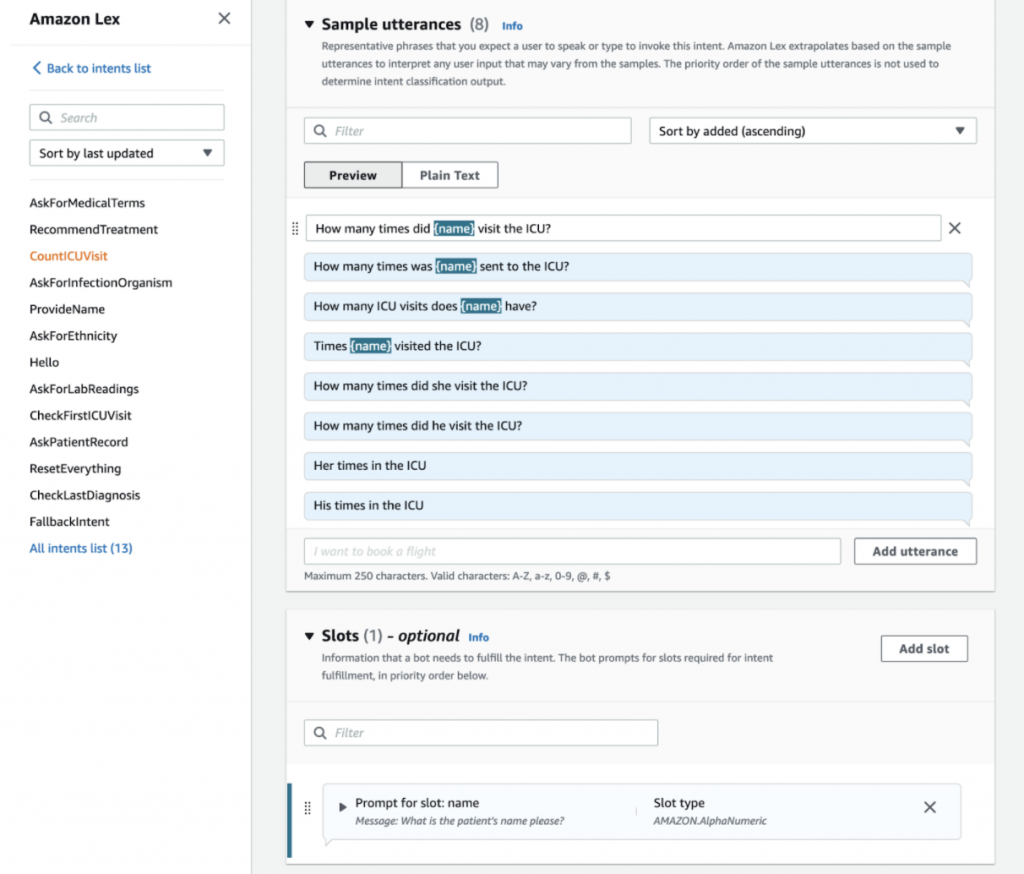
Figure 5: The “CountICUVisit” Intent.
Also, in a normal conversation, there is no need to mention the name of the patient repeatedly. Once it is mentioned in an early utterance, both sides will know who is referred to in the later dialogues (Figure 6). In Lex, we can set this up via “Contexts” (Figure 7). Before we ask Doctor.ai to count a patient’s ICU visits, we could have already revealed the patient’s name in our “ProvideName” or “CheckFirstICUVisit” Intents. So we can turn on those two contexts in the “Input contexts.” And we also informed Lex that its “name” slot can get its value from these two contexts (Figure 8). Because “CountICUVisit” intent can also be the input context for some later conversation, we hence “output” the “name” value from it in the “Output context” too. (Figure 7).

Figure 6: Slot value can be provided via context.
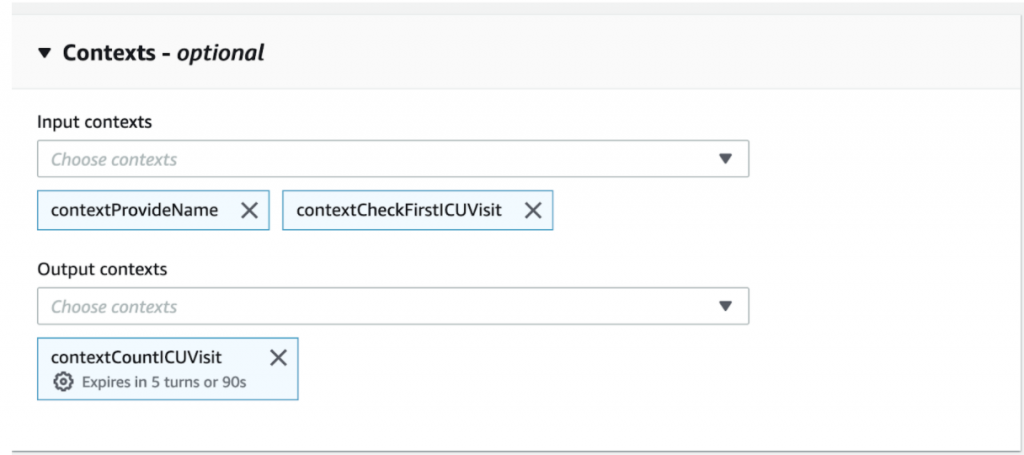
Figure 7: The setup of contexts.
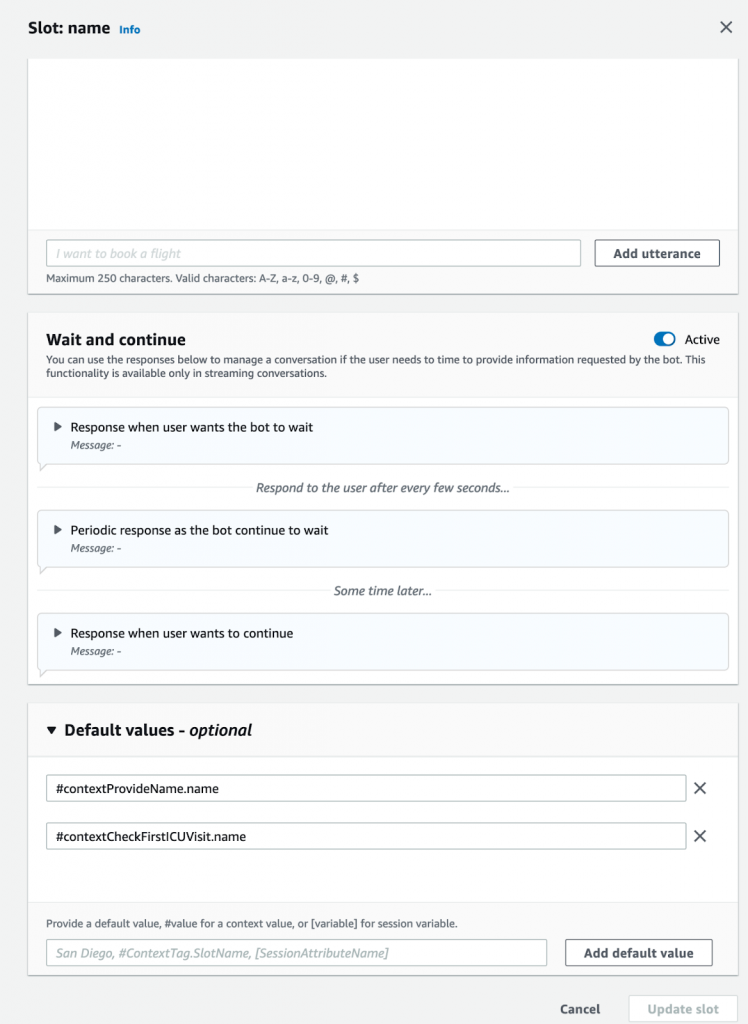
Figure 8: The name slot can get its value from context.
Once Lex is set, we can configure the Lambda in “Fulfilment.” Lex is connected to a Lambda via its alias (Figure 9).
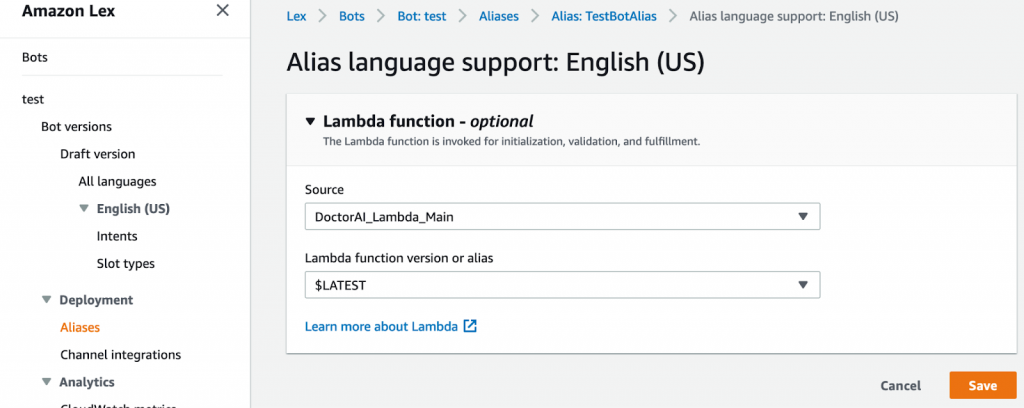
Figure 9: Lambda in Lex alias.
When Lex receives an utterance, it transmits an “event” object to the Lambda function. This is a JSON object that contains the name of the intent. Lambda then calls the corresponding function to create an appropriate response. In our CountICUVisit, Lambda queries Neo4j with the following Cypher:

Then Lambda integrates the result into a response utterance like this:
Lambda sends this response back to Lex (Figure 6) to close this “call and response” cycle.
Other intents were handled similarly. Pleasantries such as “Hello,” “ProvideName,” and “Fallback” were even simpler. The most challenging was the “RecommendTreatment” intent. In this intent, a doctor asks Doctor.ai to recommend a treatment for a patient. Behind the scenes, we first computed the cosine similarities among patients based on their lab results:
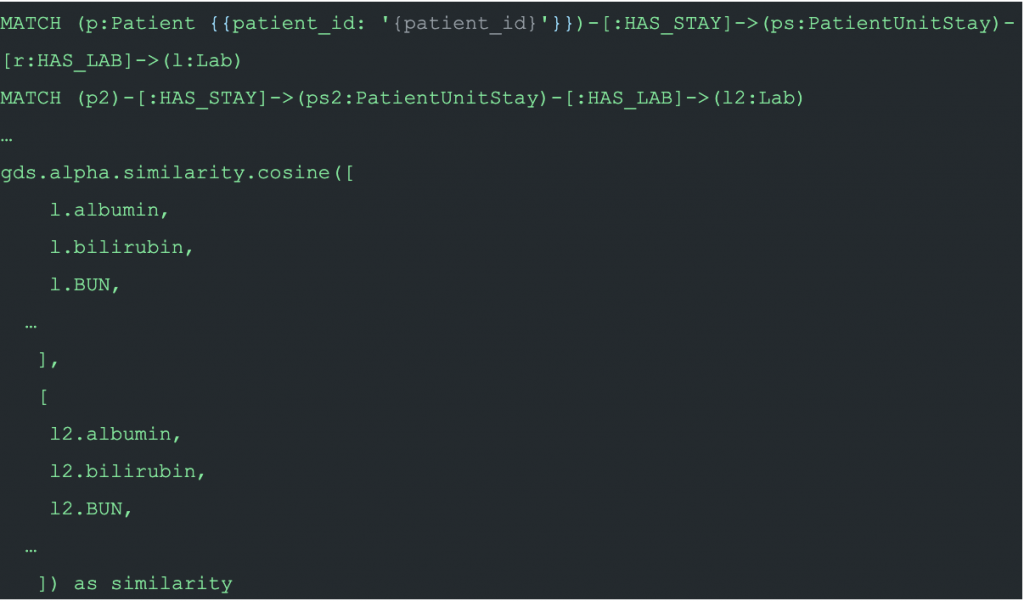
And when it is time to do the recommendation for a target patient, Doctor.ai first looks for a patient of the same gender, with an age gap smaller than 10 and a similarity of at least 0.9. If that similar patient also suffered the same ailment but received a treatment that was new to the target patient, a suggestion will be made.
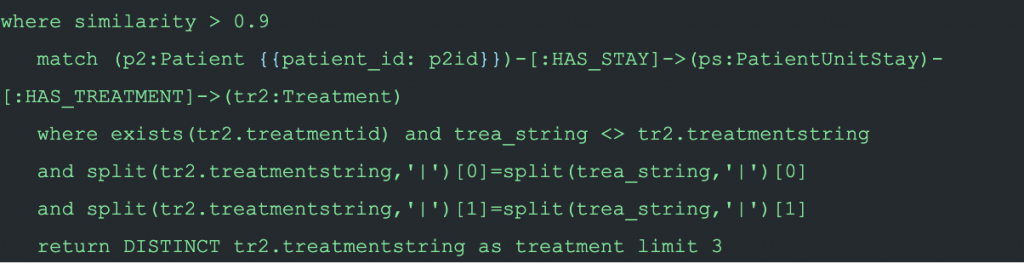
After everything was set, we built the bot and hooked it up with the frontend. The react frontend is based on React Simple Chatbot by Lucas Bassetti. It uses the AWS credential and some other data in the form of environmental parameters to communicate with Lex. We used Chrome browser to input voice and the package “speak-tts” to vocalize the response.
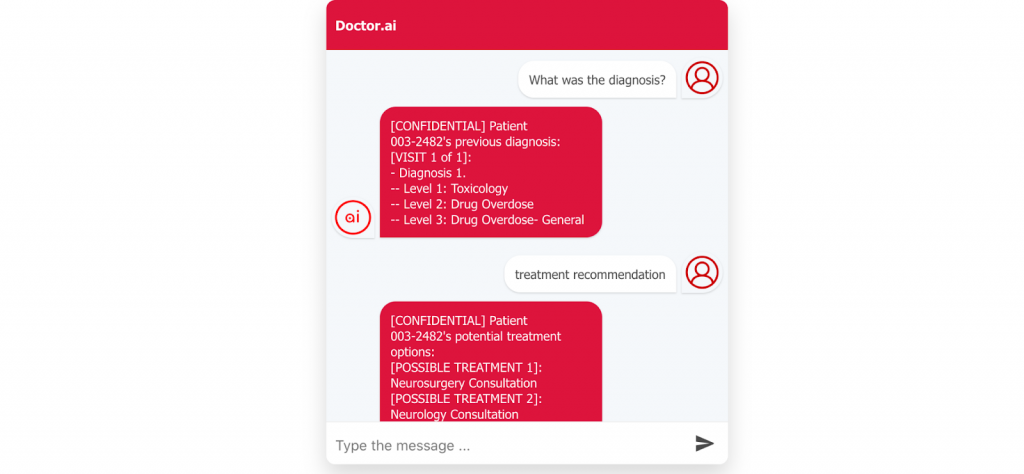
Figure 10: Treatment recommendation in the react frontend.
Finally, you can set up Doctor.ai yourself by following the instructions in “Doctor.ai, an AI-Powered Virtual Voice Assistant for Health Care.”
Conclusion
Unlike the open-domain chatbot Meena from Google, Doctor.ai is a specialized chatbot: it just focuses on healthcare informatics. So we the developer can also just focus our effort on enriching its healthcare-related functionalities. Currently, Doctor.ai has some very basic functions. But it needs more.
For example, it can sound a warning if the lab results are out of the normal ranges. We should be able to improve its treatment recommendation by utilizing knowledge graphs such as Hetionet. Since both the medical records and Hetionet are stored in Neo4j, we can even attempt to merge them both. As a result, we will be able to do queries that are too complex for non-graph databases.
The voice interaction of Doctor.ai needs improvement, too. On the one hand, Chrome could pick up our dictations but errors were too common. On the other hand, the “speak-tts” package butchered many abbreviations such as “ICU” so that some answers were quite unintelligible. In contrast, the Alan Voice AI Platform can correct the inputs on the fly and achieve impressive accuracy. So switching to Alan can be an option.
In its current form, Doctor.ai relies on AWS. This reliance can be a double-edged sword in the future. On the one hand, AWS is the largest cloud provider and we can reasonably expect it to remain in business for a long time. On the other hand, Lex is just a SaaS that can be modified or even shut down any time by AWS. Therefore, we should consider switching to an open source solution. However, the training of a language AI is capital-intensive and only a handful of institutions can afford it.
As a datathon project, Doctor.ai has demonstrated that functional medical chatbots are within our reach. But how fast can it be a part of our national healthcare system? This is not only a technical but also a political and ethical question. But individual patients or doctors can use this virtual assistant privately to manage their own medical records. So a bottom-up adoption can be a possibility too.
Intrigued? Learn more about how graph technology serves healthcare and other life services.
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


Zero-Copy Graph Reasoning on Snowflake: Getting Started With Neo4j Virtual Graph
