Don’t choose one database… choose them all!

Data Scientist CTO, Capgemini U.K.
19 min read

Editor’s Note: This presentation was given by Dave da Silva at GraphConnect Europe in May 2017.
Presentation summary
Capgemini, a global leader in consulting, technology and outsourcing services, believes that using multiple databases improves your ability to unlock the business benefits of data.
While one database might be good for certain tasks, not all databases are the right solution in every case.
The data scientists at Capgemini believe you should start with one database that partially meets all your analysis needs, such as SQL, then add in other databases such as graph or NoSQL to clear up any bottlenecks that may arise.
Later in this post, you’ll see examples of using multiple databases to solve a business problem. We’ll then explore the pros and cons of using multiple databases.
Full Presentation: Don’t Choose One Database… Choose Them All!
Capgemni’s Dave da Silva introduces the idea of using multiple databases to fulfill all of your data analysis needs.
Capgemini U.K. is a huge global company. For this blog, however, we’re going to explore the work we do within the data science team and within the U.K. That’s a team of around about 50 or so U.K.-based data scientists.
We work very closely with our colleagues overseas – especially in Northern Europe, in North America and in India – but we’re very focused on the U.K. clients specifically. We get all shapes and sizes, but our clients tend to be quite large organizations.
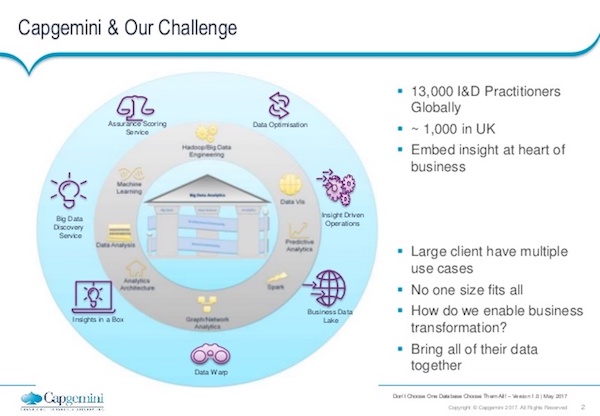
A client comes to us and says, “We have lots of data; we’ve been gathering it for many years now. The data sits in our nice relational databases, but we wanted to use that data to gain insight, and to reap the business benefit. Come and help us do that.”
Those are the sort of questions we get. They’re not well-formed analytical problems. They’re more questions about discovery or conducting experiments. And that poses an interesting challenge for us. It’s definitely interesting in that we’re not mandated to take a certain approach or find a certain answer, but it is certainly challenging.
It’s very hard to design a solution when you have an amorphous problem or poorly defined problem. That’s really driven us down to this approach to say, “We can’t select the best database from the beginning because we’re probably going to be wrong. But actually, even if we do have a very well-defined problem, there probably isn’t one database that meets that analytical need perfectly.”
You might find one or two that meet the analytical need quite well. In some cases, it might just be one database. But more often than not, it’s quite a wide problem and you want to be able to implement the best technologies to help to address the challenge.
The above image provides a quick overview of some of the big database solutions out there. We’re all familiar with those. We’ve then got Hadoop, which has emerged over the last decade as a way to start looking at really large data sets. Of course, you’ve got graph databases.
In this image, we’ve got the appearance of more in-memory databases and in-memory analytical approaches as well. Again, they are good for very fast ad hoc querying, but there present challenges as well. And then the other big group to highlight above is Lucene, which is a very complex, free text search database.
These are just five data points in that whole landscape. There are hundreds more, however, and there are many hybrids sitting between these broad categories. So this image gives you a bit of a snapshot into what these technologies look like when you’re a data scientist, and when you’re looking out there at what helps address the analytical problems clients pose to us.
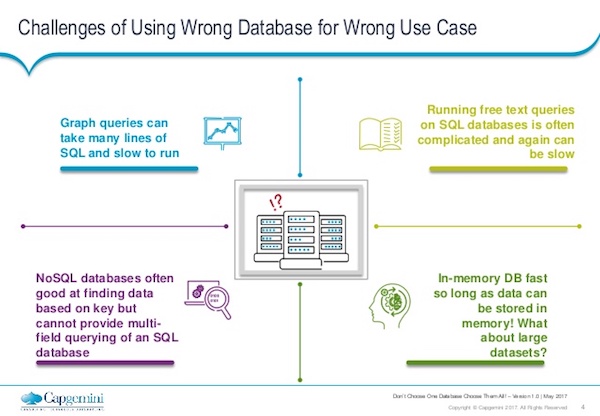
Strengths and limitations of using different solutions
What are the strengths and limitations of these different solutions?
SQL has been around for years, and will be around for years. It’s very good and powerful, and handles fairly complex queries. However, these queries grow and grow and grow, and as a result get slower and slower, especially as you start to do multiple joins across large databases.
When trying to do analysis and follow a train of thought through the data, it really breaks that up if you’re having to write these long queries and wait many minutes or hours to execute and get a solution.
We’ve all been in the situation where we’ve fired a query off at 5 o’clock in the evening, come in the next day, and it’s crashed overnight or it’s not quite what we’ve been looking for. So then we lose another day of productivity and get an increasingly pissed off client at that point.
We then go on to our free text queries. We know with SQL databases regexes may be performed, where one is able to do some nice fuzzy logic around trying to find those features within the unstructured data fields. But again, it often proves to be quite challenging and time-consuming to write those queries and get your regexes working perfectly. It may also be very time-consuming for them to run. Likewise, they’re quite expensive queries to run on the database.
There are better solutions out there, such as the Lucene-based indexes, for example, like Elasticsearch. Then we go down to the in-memory databases. These are lightning fast, but as the name suggests you need a lot of memory. As your data set gets bigger and bigger, if it won’t fit in any more memory, you’ve got to be clever about how you select data to put into memory or you need to just go out and buy more hardware. There’s obviously implications to that, and so, in-memory databases are not a silver bullet solution to your database woes.
Finally, you’ve got a whole range of other nice SQL solutions out there – the Hadoops of this world – and a whole other range of derivatives that are very good if you’re finding specific key values. But again, these solutions have their limitations and are often limited to batch-type queries rather than the real-time querying we all aspire to do.
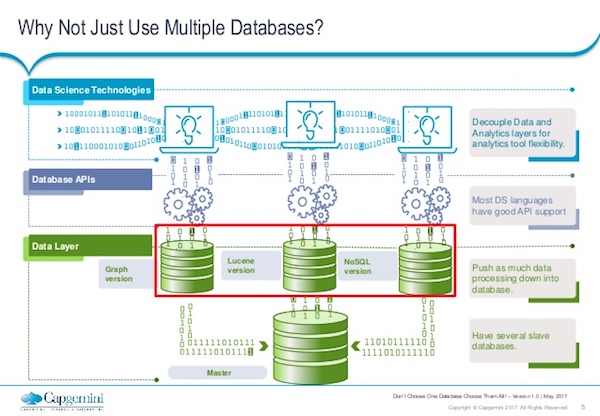
Why not just use multiple databases?
Our solution is very straightforward and it’s slightly pointing out the blindingly obvious.
Rather than trying to find the perfect database that does all of the things you require of it – it’s cheap, it’s performant, it’s reliable, it has the community behind it, and all those good things – we quickly came to the conclusion the perfect database doesn’t really exist for every analytical problem out there. But rather, each database exists for very specific analytical problems or specific use cases.
But, when you’re trying to acquire a range of things with a single client or multiple clients, you’re setting yourself up to fail if you try to find the perfect database. You end up with these lengthy discussions with colleagues, with the community and meet ups with the clients about this database versus that database, the pros and cons, and you end up disagreeing. It doesn’t really go anywhere.
So we said, “Well, let’s just embrace that sort of ethos, and go for as many databases as needed to resolve that problem.”
We’re saying, “Well, actually, if you’ve got a problem of trying to traverse data in a graph traversal, then get a graph database to do it. Don’t try and hack your SQL database to do it or optimize your SQL database to do something it’s not really designed to do. Just embrace the technology that is designed to do that.”
If your problem also needs fuzzy text search on top of that, again, you may try and hack Cypher or hack SQL to make it do that for you – and it will do it – but it will be creaking along by then. At that point, it’s time to bring in a database that is designed and optimized to traverse data.
Databases are not data science – they’re components of it. So on top of those individual databases, the next layer up is our database APIs.
So again, how are you connecting with those databases? How are you writing data to them and reading data from them? Most of the common databases have multiple APIs so it’s not a limiting factor here. You’re not going to be caught in a situation where you can’t actually access your database.
Then we’ve got a step above that again. So we’ve now got the data science technologies, the typical languages – your Pythons, your R, Spark and various other data science languages – you might bring to bear in this particular problem. You’ve also got your graphical user interfaces – your SASs, SPSS, etc. They all sit on top of this and you’re using those APIs that connect to all the different databases. You might find you have one or more technologies that connect to one or more databases.
Ultimately, you’ve got your databases containing either your whole data set duplicated or components replicated across multiple data stores. But you’re probably going to need a master version of the truth. And that’s particularly pertinent in very regulated industries. We’ll hear from clients, “Tell me what the authoritative version of this data is.”
So, of course, you may well have a master data source sitting at the bottom – which one would depend on your use case. We’re specifically not saying what that master data store should be, because it would depend on your combination of other databases and the nature of that store. Personally, I’ve always found that a good old relational database generally fits that purpose, but again, it depends on your use case.
Examples of using multiple databases
Let’s move on to a business example: your typical car insurance fraud example.
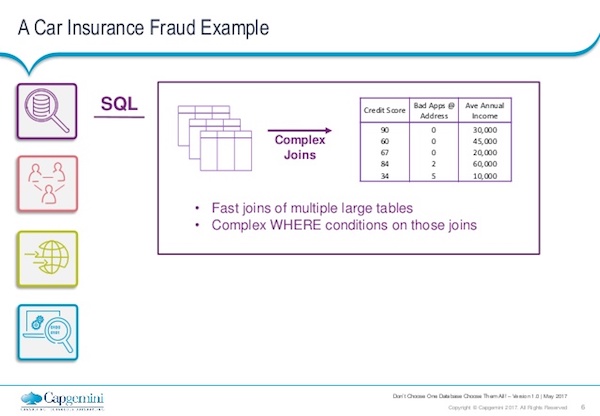
Now we’re going to bring together multiple database technologies to produce a table or a vector that you might feed into more advanced analytics.
Let’s start with an SQL database, everyone’s favorite.
SQL databases are great for joins – bringing in other fields of data and joining them to your original source data. For our fraud example, we might start with someone’s credit score or how many previous applications they’ve applied for – just a simple integer. Their income might also be a characteristic we want to look at when we’re trying to assess their propensity to commit fraud or have problems with their car insurance. These typical joins are great for an SQL database.
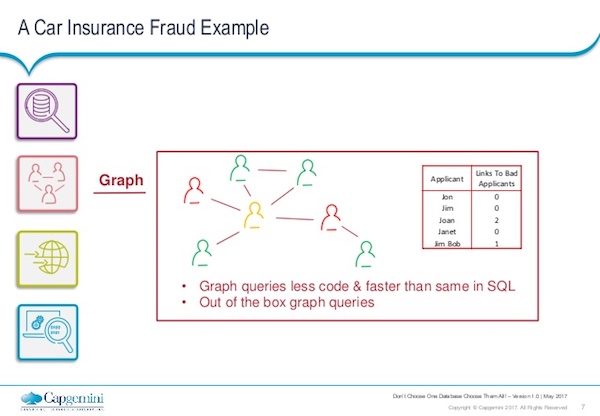
But then you want to do multiple traversals. For example, who is a friend of a friend of a friend, who shares the same address or same historic addresses. Or maybe certain individuals have been connected to the same vehicle.
These are queries that would require two or three or four inner joins on a SQL database, and this is a very cheap query to do in a graph database. So that’s where you really start to bring in the graph technologies alongside your SQL technologies.
A typical field you might wish to generate from your car insurance fraud detection [or related] example is the links to bad applicants. So, who have we seen in the past who’s committed fraud or has been a problem for the insurance company in the past? Are they within two or three steps of our current applicants?
Let’s review the NoSQL database.
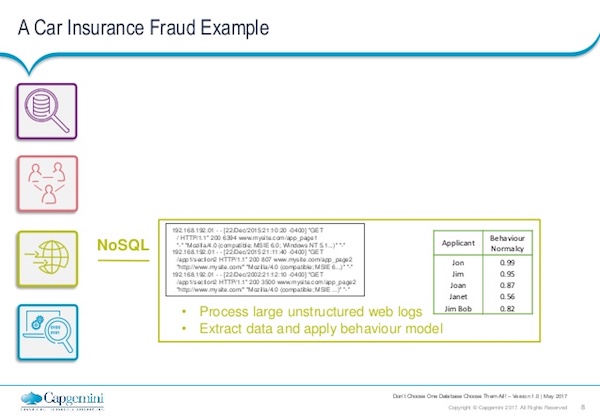
This is where you might start to bring in things like telemetry data. A lot of insurance companies in the U.K. are now starting to encourage their users to fit these little dash-top boxes to their vehicles. It registers things like how aggressive you are when you accelerate or brake, for example, generating loads of machine data worth analyzing and incorporating into your fraud example.
It’s those types of queries against that lovely machine-generated-but-very-vast-data set, where a NoSQL database really comes into its own. We just called it behavior normalcy in the graphic below. So we want to know, are they an aggressive driver? Are they a passive driver? We’re adding this to our vector to use for our detailed analysis later.
And finally, we arrive at text data. We’re a big fan of the team atElasticsearch – they have a great database. We’re doing many searches against free text data. So looking at chat logs with insurance companies, maybe they’ve provided comments within their application, where they’ve tried to describe an accident they’ve had in the past or explain away a speeding ticket they’ve had.
When trying to analyze that data, to bring it into your application, again, use a database that’s really configured to do that sort of thing and it will do it fast. Because remember, what we’re trying to do here is for the end users. They want to be able to go onto the company’s website, tap in all their details and get a response instantly. They can’t afford to wait 24 hours. You’ve already lost that customer by that point.

Bringing together just these four technologies, in this particular example, you’re now able to generate an input vector or a feature vector, which you might then feed into machine learning, a sort of clustering approach, really advanced analytics approaches, to try and assess the propensity of this applicant to cause you problems in your insurance industry.

Pros and cons of multiple databases
Let’s talk about the benefits and costs of using multiple databases, as a sort of penultimate slide.
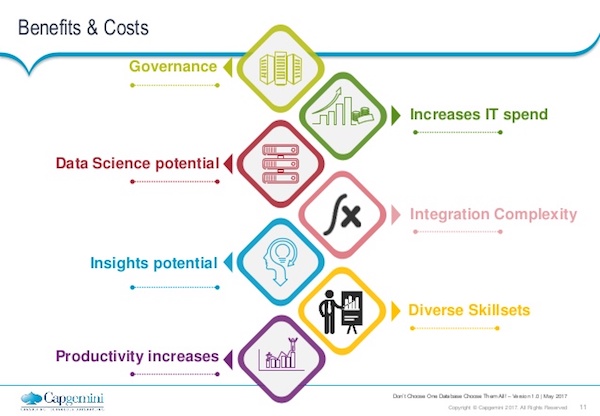
There are pros and cons to this approach. I’m not claiming that you should immediately embrace having multiple databases, because there is a cost to doing that. But before we go onto the cost, let’s talk quickly about the advantages.
So starting at the bottom of the graphic below, we have productivity. This may seem like an obvious one, but if you can maintain momentum as you’re doing analysis – as you’re trying to feed results out to users, to customers, etc., where they’re getting web performance, where they click, look for a result and it appears within milliseconds or seconds – that’s really what we’re aspiring toward.
You simply won’t achieve that in the majority of applications with a single database, because it’s optimized for one purpose and you’re trying to use it for multiple purposes.
Next, let’s think about insights potential.
What that means from our perspective is there are things you simply can’t do in a relational database, or in a graph database, that you can do in others. You might get to a point in your analysis, or in your products, where you say, “We simply can’t add that feature because our underlying database isn’t capable of doing it. It’s a complete dead-end.”
You can spend hours and hours trying to hack it to make it do that for you, but ultimately some things just don’t work. The example we hear all the time for graph is four or five or six hops from your first node. In a large relational database, you’ll simply run out of memory or time, and you’ll have a whole avenue of insights there you don’t have access to.
Pragmatically, as a data scientist, you say, “I could spend three or four days trying to make this regex work reliably and quickly, or I could not do it and take a bit of a shortcut with an alternative approach that will take me a couple of hours.” We’ve all got to be pragmatic when we’re looking at these solutions, especially when you’re working on a deadline for clients.
So actually, by giving our data scientists a whole range of tools to draw upon, you’ve suddenly greatly increased their ability to find these insights within the time available.
The final big benefit is governance.
I know it’s probably the most boring one, but this is the real killer. If you’re trying to productionize your systems, governance will be the thing, the red line, that prevents that from happening. Having multiple databases is a very good way of segmenting the queries your users are carrying out, but it may also potentially be segmenting your data.
So you might say, “Well, we’ve got this whole range of BI users over here who just need to access these sorts of databases to generate their dashboards.” So let’s put all that in a relational database, give them access to that, connect Tableau to that (or whatever tool you might be using, Spotfire, etc.), and it’s really very separate and distinct from the rest of your data at that point.
Then you might say, “We’ve then got the data science users who want access to everything.” Fine, do that for them, but make sure it’s a very specific and limited group of users who have superuser power. So by having separate databases, it’s very clear-cut where access is to those different data resources. That makes your governance model very black and white, which is a huge benefit once you’re trying to productionize these systems and reassure security you’re not going to cause a data breach for your organization.
There are a lot of positives, but we’ve got to talk about negatives and give a reasoned argument to this.
So, of course, increasing IT spend is a negative. Not all of these databases are free. Even with Neo4j, there are paid full versions. So potentially, as you start to bring in multiple enterprise databases, you have to pay for multiple licenses. Depending on how the database is, how the applications are licensed, this may scale quite nicely or it may be horrible to scale.
Again, it depends on which ones you use. Of course, databases don’t tend to play well when you have multiple databases on the same server. You might need additional hardware to service these different databases. So there is a cost to doing it in terms of your hardware and software.
Another negative is integration complexity. You’re looking at a tangled web of databases with multiple connections going to multiple applications, all of which you’re trying to secure and maintain access for for your users. It can become a bit of a nightmare, so you’ve got to bear in mind there’ll be an increased cost of building the system and also an increased cost of maintaining it as well in terms of integrations.
Finally, diverse skill sets are needed.
If you have an SQL database, say an Oracle database, then you need an Oracle DBA and a few people who know how to use it. It’s a very specific, very bounded skill set. Soonyou start to bring in three, four, five databases of different flavors, and potentially very different flavors if you’re bringing in things like Hadoop, as well, for example.
Suddenly, the range of skills you call upon for your team is increasing as well. You’ve got the interfaces between them, so you need people who are able to configure Kerberos across all of these different databases. It’s a huge challenge in terms of manning that team.

The key point here is, we found within the data science team in Capgemini, that these multiple databases do give us a greater ability to unlock business insights. And that’s really what you’re trying to do here.
You’re not trying to create a playpen for data scientists. You’re trying to create a system that allows you to get business benefit for your clients. As a bonus, though, you’re going to have happier data scientists who do now have a bigger playpen. You’ll also have happier end users who get faster, more performant systems and they do their jobs far more easily without having to wait for queries to execute overnight.
That said, there is a cost. You may find a multiple database approach actually fails for smaller projects. If you’ve only got a team of two developers and you’ve got a couple of weeks to put together a discovery activity, standing up five different database types is probably going to be prohibitively expensive. Or it’s going to require skill sets that don’t exist within your two-developer team.
However, when you get to larger engagements, larger projects here and certainly more towards your live solutions, suddenly that cost-benefit balance starts to shift. The advantages of multiple databases start to outweigh the costs of implementing that.
I’d recommend working iteratively, starting small. You might say, “Well, we can use a relational database that meets 90 percent of our needs. Let’s start with that.” Prove some business benefit and prove where performance bottlenecks are.
If you are doing multiple inner joins, and you’re finding that’s the query that’s killing your database, that really then gives you the justification to move on and say, “We need to bring in a graph database alongside that to take the weight off the relational database at that point.”
Iterate in this manner, again always adding a database, testing to see if it meets your performance needs.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3



Why machines need embeddings: Turning graph structure into features

Finding hidden bottlenecks in flight networks with Aura graph analytics on Databricks
