Proudly releasing: Efficient graph algorithms in Neo4j

Head of Product Innovation & Developer Strategy, Neo4j
5 min read
I am very happy to announce the first public release of the Neo4j graph algorithms library.
You can use these graph algorithms on your connected data to gain new insights more easily within Neo4j. You can use these graph analytics to improve results from your graph data, for example by focusing on particular communities or favoring popular entities.
We developed this library as part of our effort to make it easier to use Neo4j for a wider variety of applications. Many users expressed interest in running graph algorithms directly on Neo4j without having to employ a secondary system. We also tuned these algorithms to be as efficient as possible in regards to resource utilization as well as streamlined for later management and debugging.
These algorithms represent user-defined procedures which you can call as part of Cypher statements running on top of Neo4j.
Kudos
Big thanks goes to Martin Knobloch and Paul Horn from our good friends at Avantgarde Labs in Dresden who did all the heavy lifting. From reading tons of papers and tuning and parallelizing implementations, to providing performance testing and implementers documentation – most of the work you see in this library is theirs.
Tomaz Bratanic also helped immensely with documenting the library, providing explanations and examples on small graphs and detailing syntax information for all graph algorithms.
Our documentation is still a work in progress, so please bear with us! However, please let us know if the existing sections are helpful or you have ideas on how to improve the documentation.
The graph algorithms
The graph algorithms covered by the library are:
Centrality:
- PageRank
- Betweenness Centrality
- Closeness Centrality
Partitioning:
- Label Propagation
- (Weakly) Connected Components
- Strongly Connected Components
- Union-Find
Path-Finding:
- Minimum Weight Spanning Tree<
- All Pairs – and Single Source – Shortest Path
- Multi-Source, Breadth-First Search
Most of the graph algorithms are available in two variants: One that writes the results (e.g., rank or partition) back to the graph, and the other, suffixed with .stream which will stream the results back for further sorting, filtering or aggregation.
To select which part of the graph to run the graph algorithm on, you can provide a label and relationship type as first parameters. Then, add configuration options depending on the algorithm. For instance, iterations and damping-factor for PageRank.
PageRank on DBPedia
Here we run PageRank on DBPedia (11M Page-nodes, 125M Link-relationships):
CALL algo.pageRank('Page', 'Link', {write:true,iterations:20});
+--------------------------------------------------------------------------------------+
| nodes | iter | loadMillis | computeMillis | writeMillis | damping | writeProperty |
+--------------------------------------------------------------------------------------+
| 11474730 | 20 | 34106 | 9712 | 1810 | 0.85 | "pagerank" |
+--------------------------------------------------------------------------------------+
1 row
47888 ms
CALL algo.pageRank.stream('Page', 'Link', {iterations:5}) YIELD node, score
WITH * ORDER BY score DESC LIMIT 5
RETURN node.title, score;
+--------------------------------------+
| node.title | score |
+--------------------------------------+
| "United States" | 13349.2 |
| "Animal" | 6077.77 |
| "France" | 5025.61 |
| "List of sovereign states" | 4913.92 |
| "Germany" | 4662.32 |
+--------------------------------------+
5 rows
46247 ms
Graph projection
One really cool feature is the ability to load a projection of a (sub-)graph of your data into the graph algorithm by passing Cypher statements to select nodes and node-pairs and choosing the “cypher” graph loader. The compiled Cypher runtime of Neo4j 3.2 (Enterprise) benefits this load strategy.
Here is an example for Union-Find:
CALL algo.unionFind('
MATCH (p:Page) WHERE p.title CONTAINS "Europe" RETURN id(p) as id
','
MATCH (p1:Page)-[:Link]->(p2:Page)
WHERE p1.title CONTAINS "Europe" AND p2.title CONTAINS "Europe"
RETURN id(p1) as source, id(p2) as target
',{graph:'cypher',write:true});
+-------------------------------------------------------------+
| loadMillis | computeMillis | writeMillis | nodes | setCount |
+-------------------------------------------------------------+
| 2975 | 2 | 30 | 23467 | 4322 |
+-------------------------------------------------------------+
1 row
3013 ms
Performance testing
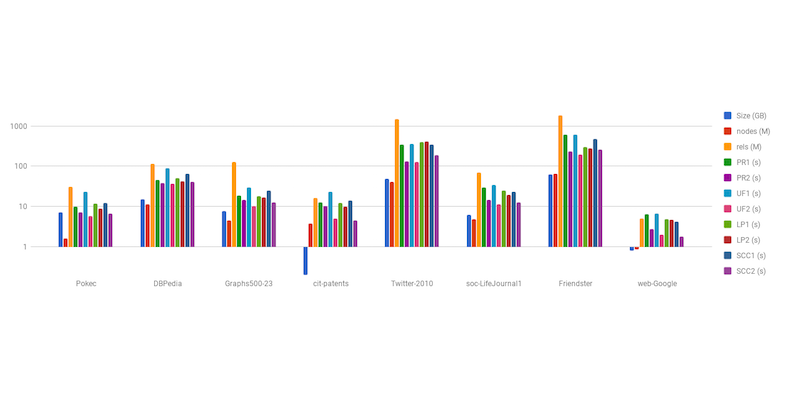
For several of the algorithms (PageRank, union-find, label-propagation, strongly-connected-components), I ran preliminary tests on medium and larger datasets that have also been used in other publications.
The table below contains database size as well as node and relationship counts. For each graph algorithm, you see the runtime (in seconds) of the first and second run.
Comparing them with other publications, those runtimes look quite good. But of course the real confirmation comes from you running the algorithms on your own datasets on your own hardware.
|
Graph |
Size (GB) |
nodes (M) |
rels (M) |
PR1 (s) |
PR2 (s) |
UF1 (s) |
UF2 (s) |
LP1 (s) |
LP2 (s) |
SCC1 (s) |
SCC2 (s) |
|
Pokec |
7.3 |
2 |
31 |
10 |
7 |
24 |
6 |
12 |
9 |
12 |
7 |
|
DBPedia |
15 |
11 |
117 |
46 |
38 |
91 |
37 |
51 |
43 |
65 |
41 |
|
Graphs500-23 |
7.9 |
5 |
129 |
19 |
15 |
29 |
10 |
18 |
17 |
25 |
13 |
|
cit-patents |
0.2 |
4 |
17 |
13 |
10 |
23 |
5 |
12 |
10 |
14 |
5 |
|
Twitter-2010 |
49 |
42 |
1468 |
349 |
131 |
353 |
128 |
405 |
405 |
339 |
189 |
|
soc-LifeJournal1 |
6.3 |
5 |
69 |
30 |
14 |
34 |
11 |
25 |
19 |
23 |
13 |
|
Friendster |
62 |
66 |
1806 |
611 |
235 |
619 |
196 |
296 |
282 |
483 |
257 |
And here is the obligatory chart.
Please note that this is log-scale to fit larger and smaller datasets in one chart.
Installation
We provide two releases, one for Neo4j 3.1.x and one for Neo4j 3.2.x
Installation is easy: just download the jar-file from the release link below, copy it into your $NEO4J_HOME/plugins directory and restart Neo4j.
Note: For Neo4j 3.2.x you will also have to add this line to your $NEO4J_HOME/conf/neo4j.conf config file:
dbms.security.procedures.unrestricted=algo.*
Feedback
We would love to hear your thoughts on the new graph algorithm library!
Please try out this library on your data and let us know how it worked. Raise GitHub issues if you run into any problems and don’t forget our #neo4j-graph-algorithm channel in the neo4j-users Discord if you have questions.
Implementation
The library is currently limited to handle 2 billion nodes by design, but in future versions we will remove those limits as we more tightly integrate this work.
Our general approach is to load the projected data from Neo4j into an efficient data structure, compute the algorithm and write the results back. All three steps are parallelized as much as possible to maximize CPU and I/O utilization.
We use a composed Graph-API interface to provide the algorithms access to the graph data, which is loaded into different representations by GraphFactory instances. Both the loading and writing back of results happens in parallel batches.
Feel free to have a look at the code, give us feedback or even add your own algorithm implementation based on the existing infrastructure.
We welcome any pull request with new algorithms, bug-fixes or other improvements.
Happy computing,
Michael
References
- Graph Algorithms Developer Page
- Releases
- GitHub Repository (please star if you like it)
- Documentation
- GitHub issues
- Neo4j Slack community
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


New research finds enterprises earn 230% ROI with Neo4j Graph Intelligence Platform

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3
