From Know Your Customer to Know Your Network: A Paradigm Shift Empowered by Neo4j


5 min read

Tax evasion scandals unveiled to the big public through Panama Papers and Paradise Papers increased the regulatory scrutiny on banks’ compliance processes.
One of the main tools used by compliance departments in financial institutions is the KYC. Know Your Customer (KYC) is the process of a business identifying and verifying the identity of its clients. The term also refers to the bank and anti-money laundering regulations, which governs these activities.
In most financial institutions, this process is currently not fully automated and necessitates heuristic and human intervention, thereby limiting an in-depth analysis.
The current regulatory landscape adds additional pressure on financial institutions that are required to collect and assess more data about their clients.
For example, the fifth European anti-money laundering directive requires more transparency by setting up publicly available registers for companies, trusts and other legal arrangements. The Bank Secrecy Act enhanced by the Patriot Act asks from financial institutions additional efforts to identify clients’ connections.
The Problem with KYC
The KYC process focuses on the information concerning the customer solely at a standalone level and does not build the bigger picture, ignoring the connections with other relevant counterparties. In the current regulatory context, the client discovery process goes beyond the traditional boundaries of the KYC procedures.
The major problem with the concept of KYC is that it is mono-dimensional, static and backwards-looking. An efficient screen tool should provide a fully-fledged picture of a client with the links to the connected parties. Therefore, a paradigm shift is necessary to improve the concept of KYC, with a dynamic, multi-dimensional and forward-looking idea of Know Your Network (KYN).
For such an endeavor, the client discovery process should employ advanced tools and methodologies able to collect information automatically and to perform data linkage.
The Wunderschild: AI Meets KYC
Our platform Wunderschild brings innovation in the KYC screening by using AI in the client discovery process.
The goal of such a platform is to empower the users with search functionality aiming to extract information about a person or a company, including the global network of connections. The backbone of such a network may gather not only the information about individuals and companies but also to record the appropriate connections.
A plain example of such links is the relations between a company and its shareholders. The connections and linkages between the nodes of the network are extracted from the third-party data, encompassing business registers, list of sanctions, media articles and courts’ documents. The set of connections is enriched through machine learning algorithms aiming to identify “hidden” links.
For example, individuals with interests in companies incorporated in different countries are identified with advanced entity resolution algorithms. Moreover, such algorithms aim to connect data from various data sources, written in different languages, to analyze relationships between person and entities and to quantify the complexity of a network.
If the “user story” of the platform seems simple and straightforward, its implementation raises several technical challenges. As mentioned above, our framework is built around the concept of KYN, and its foundation is a data lake reassembling different data sources.
Graphs Display Information as a Network
Neo4j came out as the best solution to fit our needs from both business and technological perspectives.
First, Neo4j is a graph database and therefore is coherent with the concept of KYN aiming to display the information related to an individual or a company as a network. Second, it stores efficiently the structure of the data harboured in the data lake. Last, but not the least, Neo4j accelerates enormously the work of the front-end developers because it already englobes the relational data representation.
For representing the structure of networks and relational data, Neo4j has a substantial advantage over other solutions. Nodes’ features are fed from the data lake, including information recorded in various languages and sometimes in multiple alphabets. The node features discovered in the data lake contain the basic information (representing a company or an individual) as well as an external reference to a full dossier with more comprehensive information, stored in a different database storing JSON records.
The search functionality of the platform computes a normalized string similarity metrics (i.e. Levenshtein distance) to find the relevant nodes. This operation is time-consuming, and one of the main challenges is to optimize the speed of search function in the Neo4J graph database.
Significant performance improvement is achieved through the Lucene full-text search engine which is already embedded in the Neo4j database. The search features are configured using indexing, thereby increasing the execution speed.
The code in the exhibit below creates an index named searchIndex on nodes with label Any with properties searchKey.
CALL db.index.fulltext.createNodeIndex(
"searchIndex",
["Any"],
[
"searchIndex",
"countryOfOperation",
"countryOfResidence",
"countryOfIncorporation",
"countryOfOrigin"
]
);
The figure below shows the KYN at work, depicting the network of companies connected to President Donald Trump in the United Kingdom. The exhibit also shows the results of the search for the string “Donald Trump” with the corresponding matching score established on the distance between the target string and the nodes’ name from Neo4j.
The data used in this case comes from the United Kingdom’s registrar of companies. The network provides a full historical view upon the companies where the President was either shareholder or director and the related individuals. The second and third-level connections are also presented. The complexity of the network for each node is depending on the number of links with other parties.
The complexity computation is straightforward because the database is graph-based.
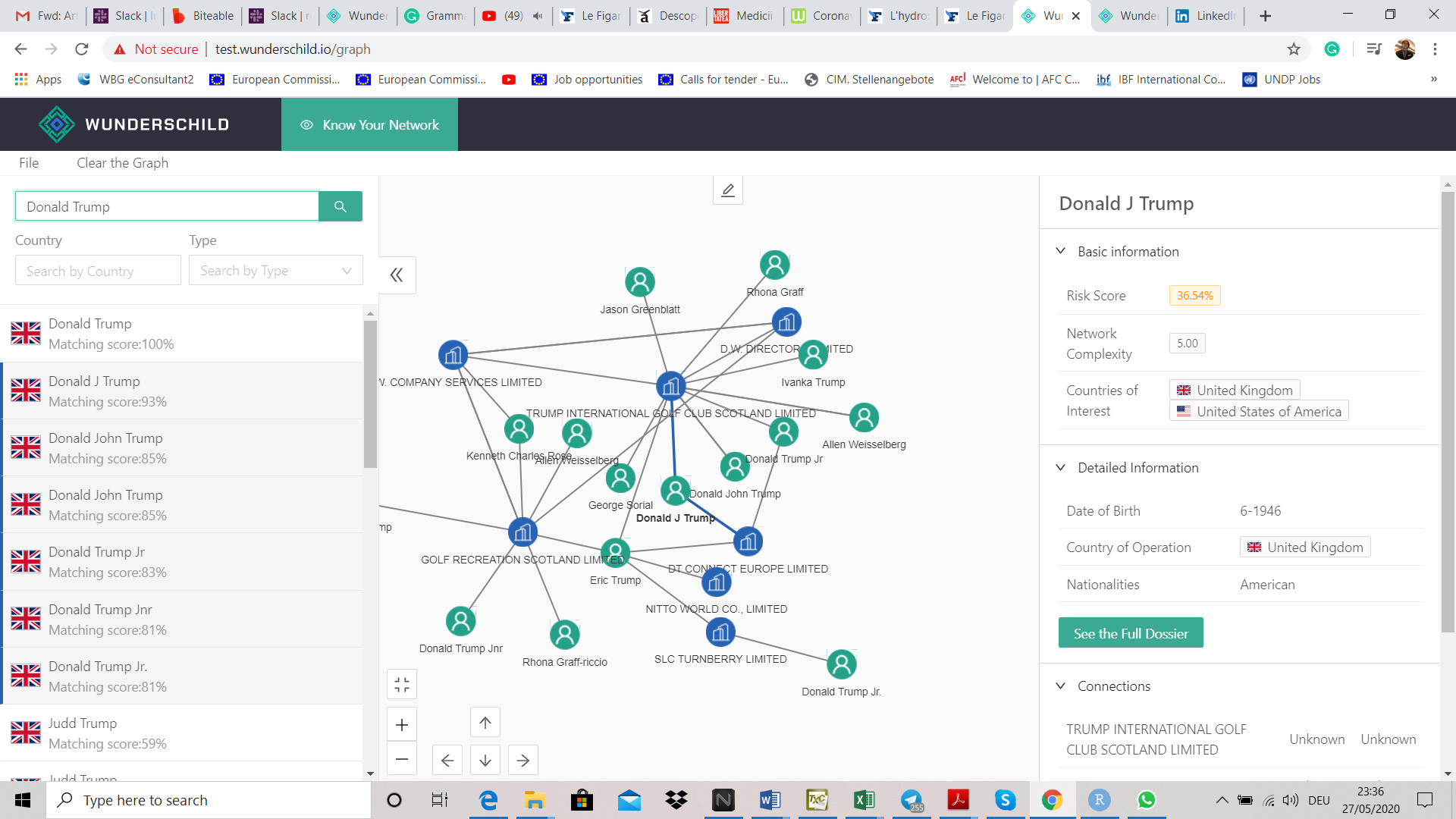
Figure 1. Historical representation of Donald Trump’s network of companies incorporated in the United Kingdom
The code in the exhibit below shows an optimized search query for the case mentioned above. The search query specifies some filters related to the country (UK) and the type of node (Person or Company). Compared to a traditional database adding a filter to the query is easy and does not hinder the perimeter of the connections.
The displayed network includes the full set of unfiltered connected nodes.
CALL db.index.fulltext.queryNodes( "searchIndex", "searchIndex:(Trump) AND (countryOfOperation:GB OR countryOfResidence:GB OR countryOfIncorporation:GB OR countryOfOrigin:GB)" ) YIELD node, score WITH node AS result, score AS resultScore MATCH (result)-[connection]-(connected) RETURN result, connection, connected, resultScore LIMIT 10;
Another major challenge for Neo4j is the implementation of a robust entity resolution algorithm. This topic will be discussed in the following article. To be continued!
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report
Fraud rings hide in the connections: Graph-Enriched Detection for Databricks Genie with Neo4j

APRA just put the financial sector on notice over AI. Government agencies need to take notes.


Finding the fastest way out: How Dijkstra’s algorithm finds shortest paths
