
The Future of the Intelligent Application: Scalability for Unlimited Growth

Vice President, Product Marketing
1 min read

Modern applications come with new requirements. Such applications incorporate intelligence and learning. They require full context to support smart decision-making in real time. These applications must be able to scale without limits to meet unexpected demand. Furthermore, next-generation applications demand straightforward, robust security and flexible architecture to comply with ever-increasing regulations.
Last week, in blog one of our four-part series on the future of the intelligent application, we looked at emerging requirements for intelligent applications, why graph databases will power intelligent applications and gave an overview of graph data science.
This week, In blog two of this four-part series, we examine scalability, including sharding and federated graphs.
Scalability
Neo4j scales with your data and your business needs, minimizing cost and hardware while maximizing performance across connected datasets.
Relational databases scale, but with limited connections across tables. As a result, JOINs severely degrade performance.
Neo4j invented the graph database. Data integrity is not only fundamental to the graph model, but to the customers who rely on a graph database in mission-critical applications. Enabling unbounded vertical and horizontal scalability required that the graph data would never be corrupted so that enterprise organizations could scale safely and with confidence.
Sharding
A large graph database may have trillions of nodes. Consider LinkedIn, for example. Picture all of the people in your professional network as a single, coherent graph. The physical storage of such a graph is divided, or sharded, across many servers or clusters, despite the fact that it’s still a single graph dataset.
While common in the relational database world, sharding is relatively new to graph databases. Sharding is the division of a single logical database into as many physical databases as required.
The ability to divide the graph database across many servers is key to scalability as well as the ability to support use cases such as compliance with data privacy regulations. For example, regulations such as GDPR stipulate that data for a particular country’s citizens must be physically stored in that country. The portion of the graph for those geographic customers can thus be sharded to fulfill those requirements.
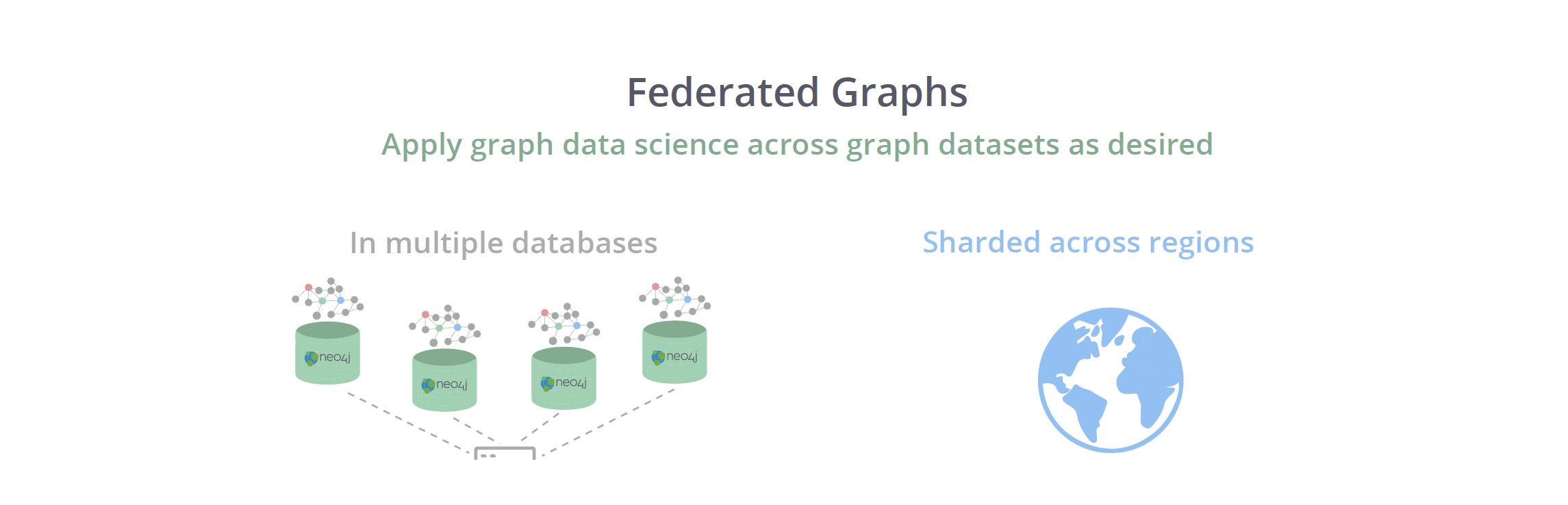
Federated Graphs
While sharding divides graphs, federated graphs bring multiple graphs together, supporting queries across graph databases that may have different logical structures.
Queries against massive graphs that share a schema
A massive graph sharded across many physical servers can be thought of as a single logical graph. Federated graphs encompass multiple Neo4j servers, creating a logical view of the servers and the databases hosted by those servers.
A federated graph creates a virtual graph that is – from the application or user perspective – one enormous graph database. When a client application or a user runs a query against such a graph, that query interacts with potentially tens or hundreds of machines and databases to store or retrieve data.
Queries against disjointed graphs
Neo4j not only handles queries against large, sharded graphs that share the same data model; it also supports queries across disjointed graphs. In effect, this makes all the data in an enterprise’s graph databases searchable with a single query.
The ability to query across disjointed graphs is an entirely new capability for the graph database world. No other graph database on the market offers this feature.
Conclusion
As we have shown in this second blog of our four-part series on the future of the intelligent application, Neo4j scales with your data and your business needs, minimizing cost and hardware while maximizing performance across connected datasets.
Next week we will focus on fine-grained security.
Today’s applications need a flexible, secure and scalable foundation – with prototypes in days, not months. Click below to get your copy of The Future of the Intelligent Application and learn why startups and enterprises alike build on Neo4j.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



