
The Future of the Intelligent Application: Why Graph Technology Is Key

Vice President, Product Marketing
5 min read

Data, AI, intelligent applications. They’re no longer separate topics, or even separate conferences. O’Reilly announced that it is merging its data and AI conferences, saying, “Data feeds AI; AI makes sense of data.” Further, both power applications. In 2016, Ben Lorica – then program chair of the O’Reilly Strata Data and AI Conferences – predicted that soon “some features of AI will be incorporated into every application that we touch, and we won’t be able to do anything without touching an application.”
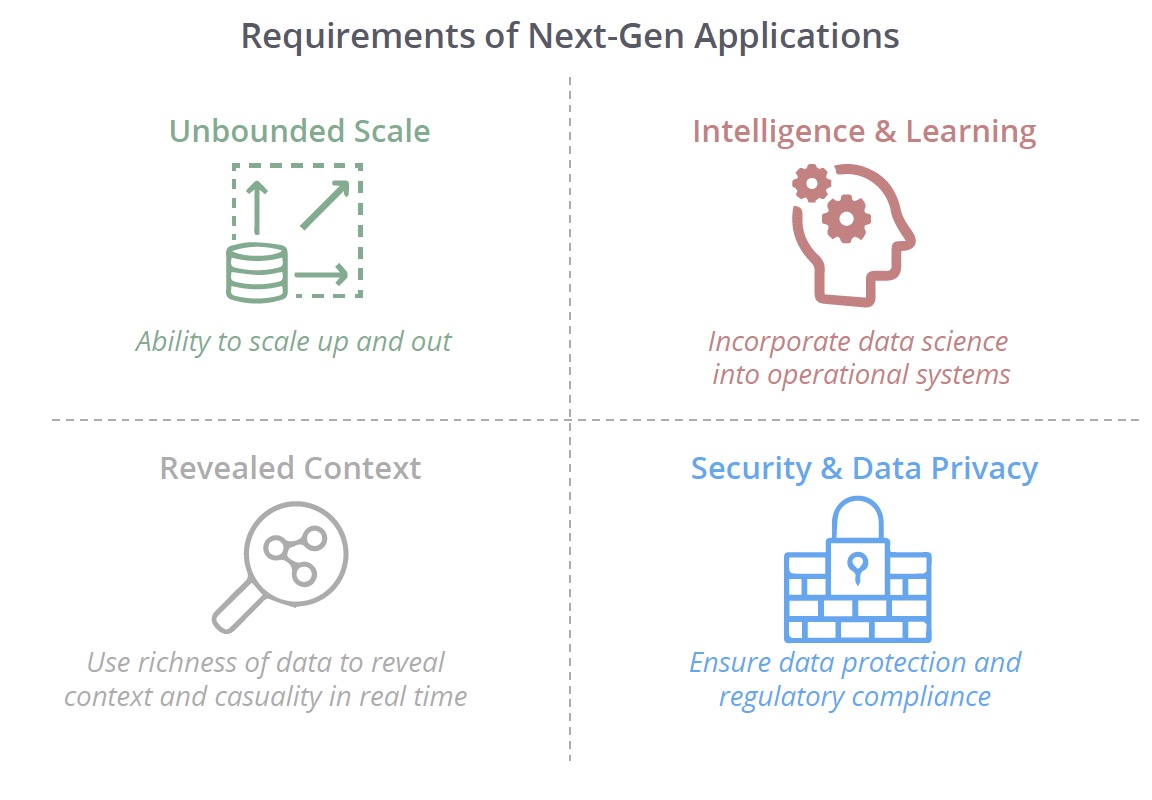
Modern applications come with new requirements. Such applications incorporate intelligence and learning. They require full context to support smart decision-making in real time. These applications must be able to scale without limits to meet unexpected demand. Furthermore, next-generation applications demand straightforward, robust security and flexible architecture to comply with ever-increasing regulations.
In blog one of this four-part series on the future of the intelligent application, we examine emerging requirements for intelligent applications, why graph databases will power intelligent applications and give an overview of graph data science.
Emerging Requirements for Intelligent Applications
Unlimited scalability: Data grows relentlessly and performant applications can’t be constrained by data volumes. Applications need to scale up – and out – to handle higher volumes while maintaining performance across a growing diversity of on-premises, hybrid and cloud architectures.
Dynamic, revealed context: Applications increasingly need databases that adapt to the myriad complexities, dynamics and unpredictability of real-world data. Effective applications use the richness of all available data to reveal context and causality in real time.
Security and data privacy: As regulations continue to evolve, individuals and governments are more conscious than ever about how and where consumer and citizen data is used. Developers need to build applications that meet these needs securely and rapidly.
Intelligence and learning: Operational applications are increasingly components of complex systems that incorporate machine learning and artificial intelligence. For actionable AI, applications need to bridge data science across operational systems and leverage context in real time.
Why Graph Databases Will Power Intelligent Applications
Just as computing has changed significantly over time, so have databases evolved to support next-generation software applications.
When relational databases were designed, a primary usage pattern was to store and retrieve information that mirrored paper forms. Tables are great for this. The database infrastructures that evolved to support the tabular model grouped data together into fixed tabular buckets. This was a good match for paper forms, and suited the slower pace of data (and business) at the time. It also optimized performance for reading from slow disk rather than fast memory, given the high cost of memory in that era.
Considerable software engineering has gone into generalizing relational databases, and they continue to serve as the dominant database model for information systems.
But relational databases have inherent limitations when it comes to connecting data. JOINing relational tables negatively impacts performance. Despite their name, relational
databases are not designed to understand and reveal real-world relationships. The need to define what the data will look like before it shows up is another challenge, particularly as the speed and diversity of data sources accelerates.
Today’s applications connect people, companies, assets, devices and even genomes. Mathematically speaking, these connections form a graph. Graph data structures provide a flexible, scalable foundation for these connection-oriented applications.
Graphs are composed of nodes and relationships (or vertices and edges, in traditional mathematics terminology). Nodes are individual data points connected by relationships. Properties can be associated with both nodes and relationships.
Graph data models are intuitive, easily sketched on a white board to share with both business and technical stakeholders. But a native graph database means that the graph, its relationships and their properties do not simply represent a nice model of the data; they represent the way the data is stored.
Neo4j is a native graph database; thus, its internal structures to store and retrieve data are optimized to understand and reveal graph database should support the strict requirements of ACID transactions while also flexibly powering applications at scale. It also enables queries that, in the relational world, might take hours to run because of their complexity, but in a native graph context might run in fractions of a second. Graph databases like Neo4j further open the door to the emerging field of graph data science, with graph algorithms as a cornerstone. Graph algorithms enable individual pieces of data to be understood in the context of emergent characteristics of the network, providing a level of intelligence not otherwise available.
The reason why Neo4j supports both graph transactions and graph data science so well is that it has a native graph format specifically for graph storage and local queries and a format specifically for graph analytics. Neo4j automates data transformations between graph storage and graph analytics computation – so you benefit from maximum compute performance for analytics and native graph storage for persistence. This means that there’s no duplication or ETL required to run analytics on existing graph data, and that your applications capitalize on a unique virtuous cycle between transactions and data science, within a single database.
Transaction integrity is just as important in graph databases as relational databases. And it’s more important in a graph database than in NoSQL databases, which are fundamentally architected to handle data but not relationships between individual points of data. Break one relationship and you have corrupted the database with a relationship that points nowhere. There are countless ways to go wrong in connecting, copying or updating portions of a graph dataset.
In a graph database where everything is connected, ACID transactions are paramount. An atomic transaction must be fully executed or connections could be broken, which results in the graph storing the wrong information. And when a graph database at scale is formed by billions – if not trillions – of connections, even a single broken relationship spells disaster.
What Is Graph Data Science?
Graph data science unlocks insights from connected data. Neo4j provides the first enterprise-grade graph data science platform to harness the natural power of network structures to infer behavior. The Neo4j Graph Data Science Library includes production-ready, validated graph algorithms to help answer previously intractable questions using the connections in your data. These algorithms fall into five categories.
- Pathfinding and Search: Pathfinding algorithms build on top of graph search algorithms and explore routes between nodes, starting at one node and traversing through relationships until the destination has been reached.
- Centrality (Importance): Centrality algorithms determine the importance of distinct nodes in a network
- Community Detection: Community Detection algorithms evaluate how a group is clustered or partitioned, as well as its tendency to strengthen or break apart
- Heuristic Link Prediction: Heuristic Link Prediction algorithms help determine the closeness of a pair of nodes
- Similarity: Similarity algorithms can help calculate the similarity of nodes
Beyond exploration by domain experts using ad hoc queries, data scientists use graph algorithms for more global analysis and understanding the structure of relationships. Common uses include deep path analytics, influencer identification, community and neighbors detection, fraud detection, link prediction, structural pattern matching and disambiguation.
Furthermore, data scientists use graph feature engineering to improve their predictive accuracy. For example, graph algorithms can produce an influence score for nodes (e.g., PageRank) or label nodes in tightly knit communities and then those scores and labels can be extracted for use in machine learning models. Adding these types of connected features to existing machine learning models improves their accuracy without disrupting the current machine learning pipeline.
Conclusion
As we have shown in this first blog of our four-part series on the future of the intelligent application, graph data structures provide a flexible foundation for today’s connection-oriented applications.
Next week we will focus on scalability, including sharding and federated graphs.
Today’s applications need a flexible, secure and scalable foundation – with prototypes in days, not months. Click below to get your copy of The Future of the Intelligent Application and learn why startups and enterprises alike build on Neo4j.
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling

What Are the Different Types of Graph Algorithms & When to Use Them?



Neo4j Expands AWS Collaboration With New Competencies in Finance, Automotive, GenAI, and ML
