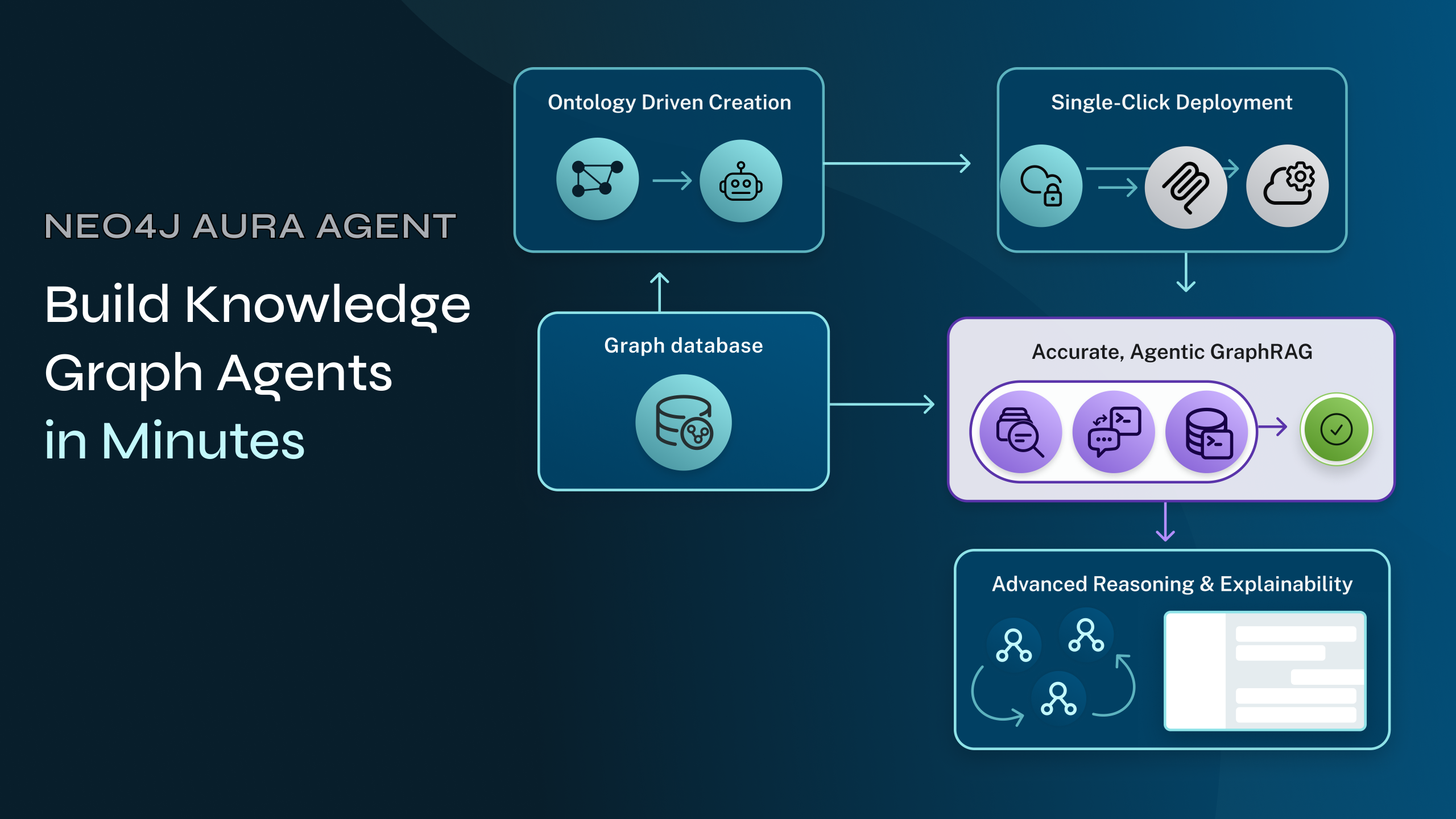
Building AI systems that don’t just make decisions, but remember and use the “why”.
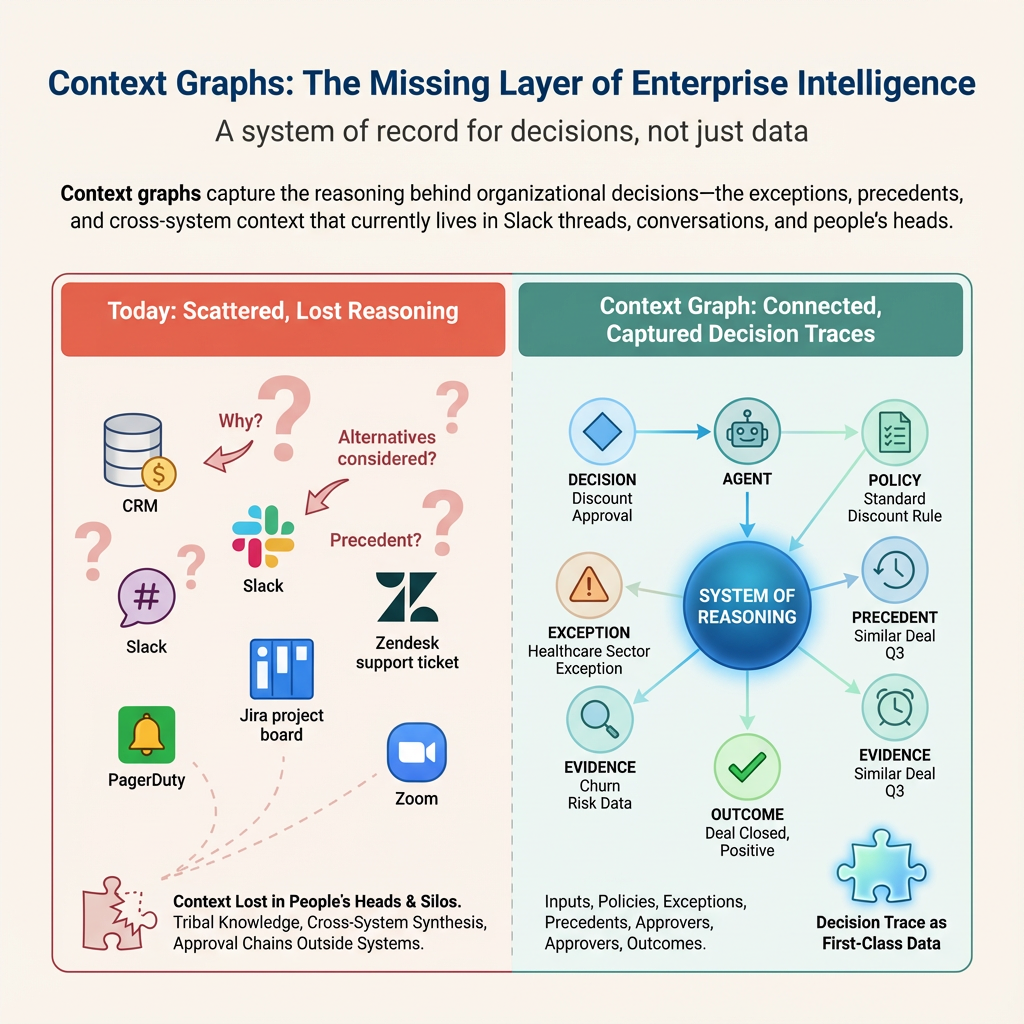
The Problem: The missing “why”
Traditional databases are designed around a fundamental assumption: what matters is what’s true right now. Your Postgres database can tell you a customer’s current credit limit is $50,000 — but it can’t tell you why it was set to that amount, what factors were considered, or what similar decisions were made in the past.
The State Clock vs. Event Clock
This is what is known as the State Clock: a snapshot of current reality. And for decades, it was enough.
But AI agents are changing everything. When an AI-powered assistant recommends approving a $100K credit line increase, the question isn’t just “is this the right answer?” Instead we want to understand :
- What past decisions was this based on?
- What policies were applied?
- If this goes wrong, what caused it?
- How do we learn from this for future decisions?
This requires a different kind of data structure — one that captures the Event Clock: what happened, when it happened, and why.
Enter The Context Graph
Using Jaya Gupta’s description, a Context Graph is a knowledge graph specifically designed to capture decision traces — the full context, reasoning, and causal relationships behind every significant decision in an organization.
Unlike a traditional audit log (which just records actions), a context graph captures:
- The reasoning: Why was this decision made?
- The precedents: What similar decisions came before?
- The causal chain: What led to this decision, and what did it cause
- The context: What was the state of the world when this decision was made?
- The policies: What rules were applied or overridden?
This is the tribal knowledge that traditionally lives only in human experts’ heads — now captured in a queryable, analyzable structure.
Why Neo4j is the Perfect Fit
Here’s where Neo4j’s property graph model shines. Let’s look at a financial services context graph:
The Data Model
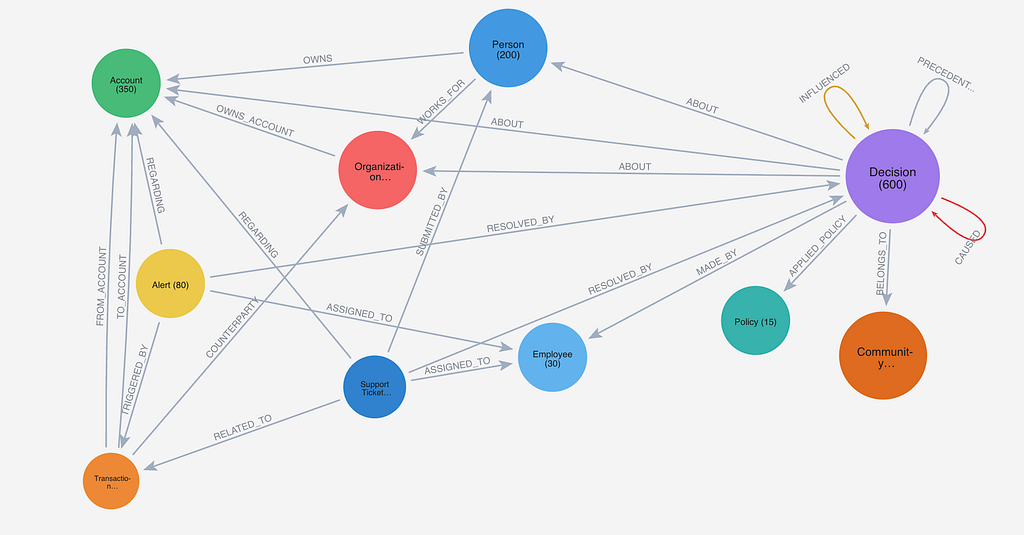
ENTITIES (What exists)
├── Person (customers, employees)
├── Account (checking, savings, trading, margin)
├── Transaction (deposits, withdrawals, transfers)
├── Organization (banks, vendors, counterparties)
└── Policy (business rules and thresholds)
DECISION TRACES (What happened and why)
├── Decision (the core event with full reasoning)
├── DecisionContext (state snapshot at decision time)
├── Exception (policy overrides with justification)
├── Escalation (when decisions need higher authority)
└── Community (clusters of related decisions)
The Relationships (The Magic of Graphs)
This is where relational databases struggle a bit, while graphs shine:
// Causal relationships - natural in a graph, nightmare in SQL
(:Decision)-[:CAUSED]->(:Decision)
(:Decision)-[:INFLUENCED]->(:Decision)
(:Decision)-[:PRECEDENT_FOR]->(:Decision)
// Context relationships
(:Decision)-[:ABOUT]->(:Person|:Account|:Transaction)
(:Decision)-[:APPLIED_POLICY]->(:Policy)
(:Decision)-[:GRANTED_EXCEPTION]->(:Exception)
(:Decision)-[:TRIGGERED]->(:Escalation)
// Entity relationships
(:Person)-[:OWNS]->(:Account)
(:Transaction)-[:FROM_ACCOUNT]->(:Account)
(:Transaction)-[:TO_ACCOUNT]->(:Account)
In a relational database, tracing a causal chain like “what decisions led to this account freeze?” requires:
- Multiple recursive CTEs
- Complex self-joins on decision tables
- Performance that degrades exponentially with chain depth
In Neo4j, it’s a two lines of code:
MATCH path = (freeze:Decision {id: $freeze_id})<-[:CAUSED*1..5]-(upstream)
RETURN path
Context Graph Demo: AI-Powered Decision Tracing
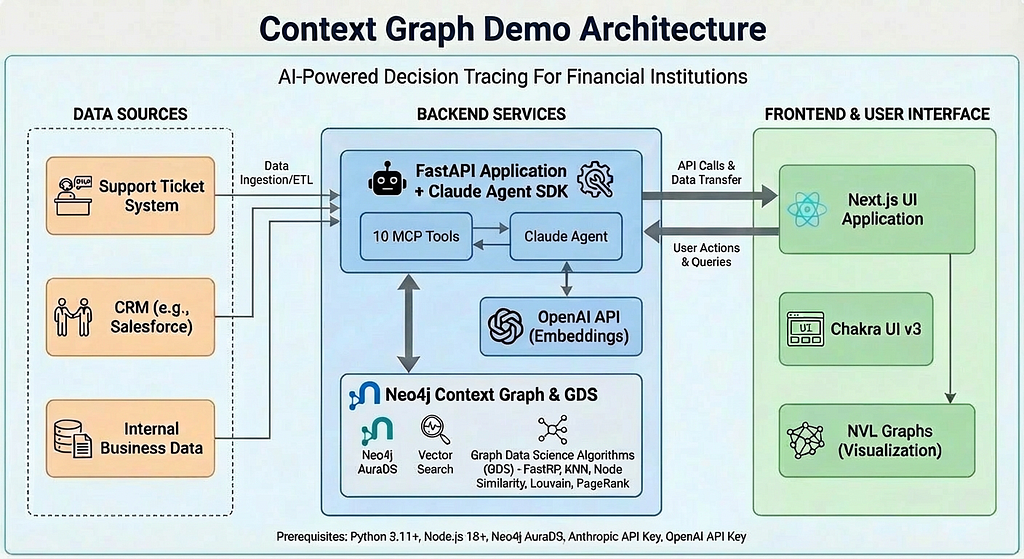
The Context Graph Demo is a complete working application that demonstrates these concepts. It’s built with:
- Backend: FastAPI with the Claude Agent SDK
- Database: Neo4j (ideally AuraDS for GDS algorithms)
- Frontend: Next.js with Chakra UI and NVL for graph visualization
- AI: Claude Sonnet using Claude Agent SDK with 11 specialized MCP tools for graph operations
The AI Agent Tools
The agent has access to purpose-built tools that leverage the context graph:
| Tool | Purpose |
| --------------------------| ---------------------------------------------------------------|
| `search_customer` | Find customers and their related entities |
| `get_customer_decisions` | All decisions made about a specific customer |
| `find_precedents` | Hybrid semantic + structural search for similar past decisions |
| `find_similar_decisions` | FastRP-based structural similarity search |
| `get_causal_chain` | Trace what caused a decision and what it led to |
| `record_decision` | Create new decisions with full context and embeddings |
| `detect_fraud_patterns` | Find accounts with transaction patterns similar to known fraud |
| `find_decision_community` | Louvain-based clustering of related decisions |
| `get_policy` | Retrieve applicable business rules |
A Real Workflow: Credit Line Increase
Here’s what happens when a user asks:
”Should we approve a credit limit increase for Jessica Norris? She’s requesting a $25,000 limit increase.”
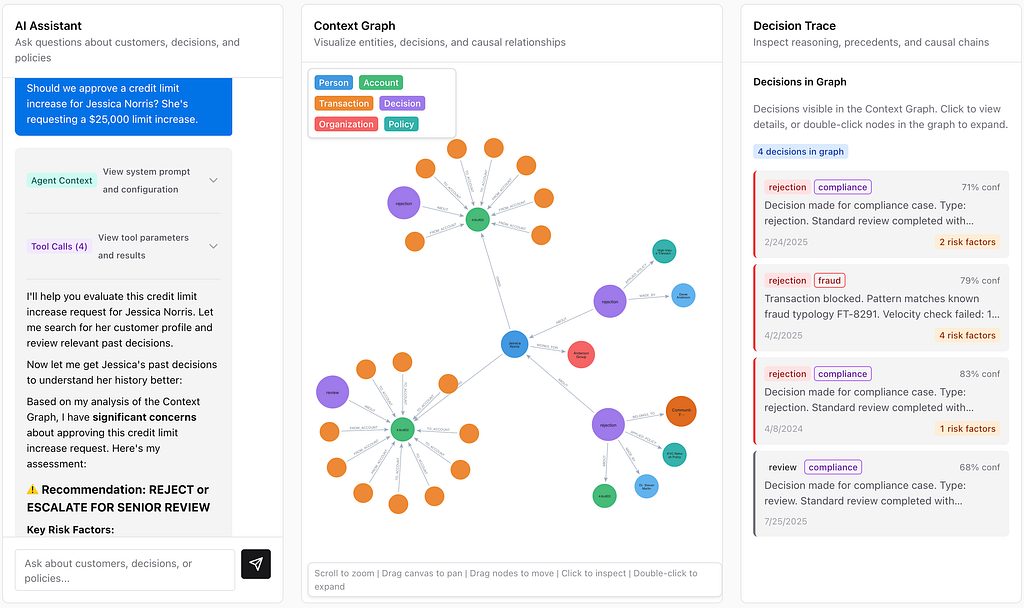
The AI agent immediately begins querying the context graph:
Step 1: Customer Search (search_customer)
The agent finds Jessica Norris and populates the graph visualization with her complete profile:
- Risk Score: 0.419 (moderate-high)
- Accounts: 2 accounts — a trading account ($258,695, medium risk tier) and a margin account ($17,756, high risk tier)
- Employer: Anderson Group (risk rating “C”, based in Yemen)
- Recent Transactions: 20+ transactions including several pending wire transfers
Step 2: Decision History (get_customer_decisions)
The context graph reveals critical past decisions:
- April 2025 Fraud Rejection: Transaction blocked. Pattern matches known fraud typology FT-8291. Velocity check failed: 14 transactions in 29 minutes. Geographic anomaly: IP location inconsistent with account address.
- Risk factors: new_device, round_amount, high_amount, after_hours
- Confidence score: 78.8%
- February 2025 Compliance Rejection: Standard review completed with risk factors including after_hours and round_amount
- April 2024 Compliance Rejection: Another rejection with round_amount flag
Step 3: Precedent Search (find_precedents)
The agent searches for similar credit limit decisions using hybrid vector search — combining semantic similarity (text embeddings) with structural similarity (FastRP graph embeddings).
Step 4: Policy Lookup (get_policy)
Retrieves applicable policies like “High-Value Transaction Review” and “KYC Refresh Policy.”
The Agent’s Recommendation:
Based on the context graph analysis, the agent returns:
⚠️ **Recommendation: REJECT or ESCALATE FOR SENIOR REVIEW**
**Key Risk Factors:**
Past fraud flag (April 2025) with velocity check failure
Multiple compliance rejections on record
High-risk tier margin account
Employer associated with elevated country riskGiven the documented fraud incident and compliance pattern, I recommend either REJECT or ESCALATE with additional due diligence requirements.
The graph visualization shows 31 nodes and 30 relationships — Jessica’s complete context including her accounts, transactions, past decisions, the employees who made those decisions, and the policies that were applied.
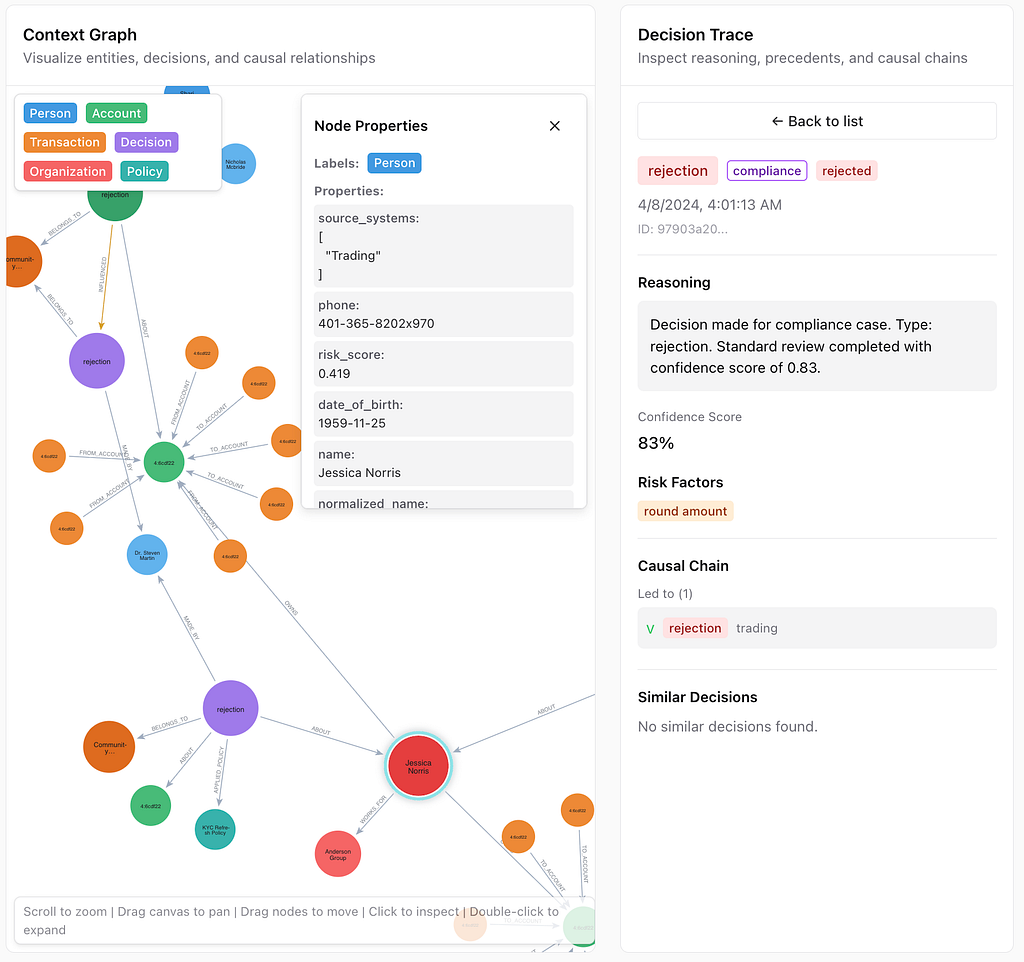
This is the power of context graphs: The agent didn’t just check a credit score. It traced the full decision history, understood the causal relationships between past events, and made a recommendation grounded in institutional knowledge.
Graph Data Science: The Secret Weapon
Neo4j Graph Data Science (GDS) provides algorithms that are fundamentally impossible in relational databases:
Node Embeddings With FastRP
Node embedding algorithms compute low-dimensional vector representations of nodes in a graph. FastRP is a node embedding algorithm that generates 128-dimensional embeddings that capture each node’s structural position in the graph — not based on properties, but on relationship patterns. It is much faster than node2vec with equivalent accuracy and is available in the GDS library.
CALL gds.fastRP.mutate('decision-graph', {
embeddingDimension: 128,
iterationWeights: [0.0, 1.0, 1.0, 0.8, 0.6],
mutateProperty: 'fastrp_embedding'
})
These embeddings enable questions like: “Find decisions that happened in similar contexts” — where “similar” means similar graph structure, not similar text.
Louvain Community Detection
Community detection algorithms are used to evaluate how groups of nodes are clustered or partitioned, as well as their tendency to strengthen or break apart. Louvain automatically clusters decisions that are densely connected through causal and influence relationships:
CALL gds.louvain.mutate('decision-graph', {
nodeLabels: ['Decision'],
relationshipTypes: ['CAUSED', 'INFLUENCED', 'PRECEDENT_FOR'],
mutateProperty: 'community_id'
})
This surfaces patterns like: “These 15 trading exceptions all trace back to the same policy gap.”
Node Similarity for Fraud Detection
Similarity algorithms compute the similarity of pairs of nodes based on their neighborhoods or their properties. By comparing the neighborhood structure of accounts, we can find accounts that behave like known fraud cases:
CALL gds.nodeSimilarity.stream('entity-graph', {
topK: 10,
similarityCutoff: 0.5
}) YIELD node1, node2, similarity
This detects patterns that would be invisible to rule-based systems.
Hybrid Vector Search: Semantic + Structural
The demo implements a dual embedding strategy, reasoning_embedding using OpenAI text embedding model and fastrp_embedding using Neo4j FastRP algorithm. The text embedding captures semantic similarity of decision reasoning text while the FastRP node embedding captures the structural similarity in graph topology.
When searching for precedents, both are combined:
def find_precedents_hybrid(scenario, category, limit=5):
# Generate semantic embedding for the query
query_embedding = openai.embeddings.create(
model="text-embedding-3-small",
input=scenario
)
# Vector search on reasoning embeddings
results = session.run("""
CALL db.index.vector.queryNodes(
'decision_reasoning_idx',
$limit,
$query_embedding
) YIELD node AS d, score AS semantic_score
WHERE d:Decision
RETURN d, semantic_score
""")
# Vector search on reasoning embeddings
results = session.run("""
CALL db.index.vector.queryNodes(
'decision_reasoning_idx',
$limit,
$query_embedding
) YIELD node AS d, score AS semantic_score
WHERE d:Decision
RETURN d, semantic_score
""")
This finds decisions that are both semantically similar (similar reasoning text) and structurally similar (similar position in the decision graph).
Try It Yourself
The Context Graph Demo is open source and available on GitHub. To run it locally you’ll need:
- Neo4j AuraDS (for GDS algorithms) or Neo4j Enterprise with GDS
- OpenAI API key (for embeddings)
- Anthropic API key (for Claude agent)
Quick Start Demo
Try this single prompt to see everything in action:
Valerie Howard has 6 flagged transactions on her account. Check for fraud
patterns, find similar cases, and recommend next steps based on our
policies and past decisions.
This will trigger customer search, fraud detection, precedent lookup, policy retrieval, and graph visualization — all in one conversational interaction.
Why Property Graphs Are A Natural Fit For Context Graphs
Property graphs are the natural substrate for context graphs. Causal chains, precedent links, and policy applications map directly to relationships — no recursive CTEs or complex self-joins required. And GDS algorithms like FastRP, Louvain, and Node Similarity power insights that are fundamentally impossible in relational databases.
For enterprise AI, this unlocks:
- Explainability: Every recommendation traces back to specific precedents and reasoning
- Consistency: Similar situations get similar treatment because the system surfaces relevant precedents
- Learning: The graph grows with every decision, becoming more valuable over time
- Compliance: Full audit trails with causal chains for regulatory requirements
The tribal knowledge that takes decades to accumulate in human experts’ heads can now be captured, queried, and leveraged by AI systems.
References & Further Reading
The concept of context graphs has been gaining significant attention in the enterprise AI space. Here are the key resources that informed this post:
The Original Thesis
- AI’s Trillion-Dollar Opportunity: Context Graphs — Foundation Capital (Jaya Gupta & Ashu Garg, December 2025)
The seminal piece arguing that enterprise value is shifting from “systems of record” (Salesforce, Workday, SAP) to “systems of agents.” The new crown jewel isn’t the data itself — it’s the context graph: a living record of decision traces stitched across entities and time, where precedent becomes searchable.
The Reality Check
- Context Graphs: Capturing The “Why” In The Age of AI— Dharmesh Shah, HubSpot CTO (January 2026)
Dharmesh calls the idea “elegant and intellectually compelling” but offers a reality check: most companies are nowhere near ready for context graphs. “We’re barely at the point where semi-autonomous agents are getting deployed for some key use cases.” While the theory is sound, the timeline may be optimistic — most companies are still struggling with basic data unification.
The Two Clocks Problem
– What Are Context Graphs, Really? — Subramanya N
A deep dive into the “state clock vs. event clock” distinction: “We’ve built trillion-dollar infrastructure for the state clock: what is true right now. But we have almost no infrastructure for the event clock: what happened, in what order, and with what reasoning.”
Tools Used in This Demo
- Neo4j Graph Database — The property graph database powering the context graph
- Neo4j Graph Data Science (GDS) — FastRP, Louvain, Node Similarity algorithms
- NVL Visualization Library — Interactive graph visualization
- Claude Agent SDK — AI agent framework with MCP tools
— –
Level Up with Graph Data Science
- Graph Data Science Fundamentals — a free GraphAcademy course covering the basics of GDS algorithms
- Applied Algorithms in GDS — solve actual challenges across manufacturing, fraud detection, logistics, research, and machine learning
*Context graphs aren’t just a better way to store data — they’re a better way to capture institutional knowledge. And in the age of AI agents, that knowledge is the key to reliable, explainable, enterprise-grade decisions.*
Hands On With Context Graphs And Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Beyond the Lakehouse: Why Your Microsoft Fabric Strategy Needs Neo4j Graph Intelligence