Graph compute with Neo4j: Built-in algorithms, Spark & extensions

Director of Developer Relations @ Neo4j
12 min read
Editor’s Note: Last October at GraphConnect San Francisco, Ryan Boyd – Developer Relations at Neo Technology – delivered this presentation on how to perform various graph compute functions within the Neo4j ecosystem.
For more videos from GraphConnect SF and to register for GraphConnect Europe, check out graphconnect.com..
We’re going to go over graph compute and the various ways you can use this with Neo4j. The following is mostly a survey of the different available technologies along with some demos of how those technologies work.
Neo4j is optimized for online transaction processing (OLTP) and is intended to be used as your primary database. While it wasn’t built specifically with the intention of being used for graph compute or analytics, a lot of customers and open-source users are using Neo4j for those purposes.
Two types of graph compute
There are a number of different ways to do graph compute, the first of which is through subgraphs. You do this by traversing the graph from an anchor node through which you only touch a certain subset of the graph. Neo4j is optimized for subgraph traversals and includes algorithms to perform that function.

You can also perform a global traversal using algorithms such as PageRank, which touches every node in the database. Neo4j isn’t optimized for this type of graph compute, but there are some techniques you can use that allow you to perform this type of search.
Let’s consider the following example subgraph queries: a Cypher analysis and a REST call that requires a Dijkstra algorithm, both of which will return ShortestPaths.
Subgraph queries with Cypher
Mapping shortest paths in Twitter
In this first demo, I’m going to map my Twitter network; you can map your own network through the same tool here. I plug my dataset into the graph network application by logging in with my Twitter handle. It then uses OAuth to load your tweets, other users’ tweets, etc. into a Neo4j Docker instance for you to run.

The first queries we’re going to run are ShortestPath queries:

I have a number of Neo4j servers running in the background, and to make the queries a bit more interesting, I’ve uploaded a bunch of other users in addition to my and other neighboring Tweets.
With the below query, I’m requesting that Neo4j return allShortestPaths. If you only do ShortestPath, it will only return only one of the shortest paths rather than all of them:

Below is the shortest path between me and a particular tweet. I’m represented by the node at the top right (@ryguyrg), while the blue node at the bottom left is the Tweet. This tweet was actually a retweet by @BestNoSQL (bottom right), which mentioned both @maxdemarzi (top left) and @BestNoSQL.

The shortest paths through which I can get to the tweet are either through my FOLLOWS relationship with @BestNoSQL, or through my FOLLOWS relationship with @maxdemarzi.
Finding the relationship between two users is a bit more interesting. For the next example, I’m going to try and find the shortest path between a randomly-picked Twitter user — Kevin — and me.

I follow @Datachick (bottom left) who follows @Kevin (upper left), and I follow @dmcg (upper right) who follows @Kevin.
Those are the two different paths through which I can get to @Kevin. If I had chosen to do ShortestPath instead of allShortestPaths, it would have shown only one of those relationships.
These both represent basic subgraph queries because we started at one node and traversed a certain segment of the graph to arrive at another node or set of nodes.
Mapping shortest paths on Legis-Graph
The next set of example queries will be through legis-graph, which was developed by William Lyon and includes all congressional activity related to bills across congressional sessions.
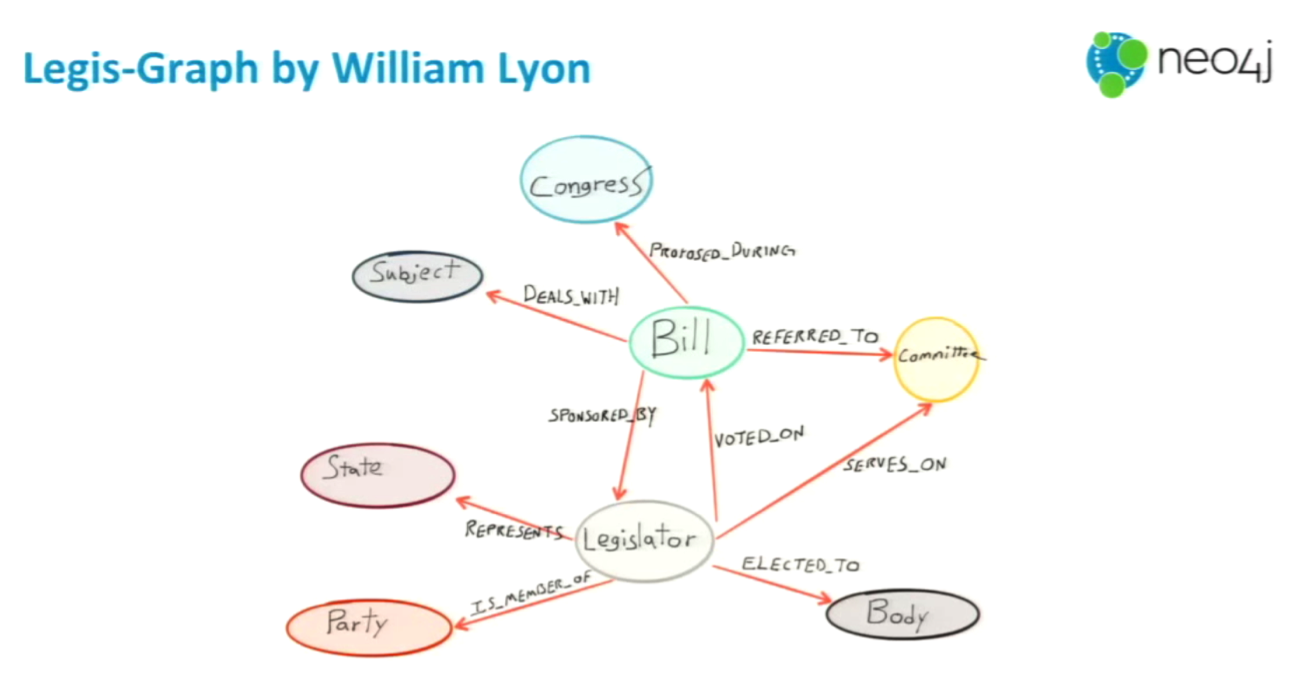
I loaded the data into my Neo4j instance using a tool called Load Cypher Script — also developed by Will — and allows you to load multi-line Cypher scripts into any Neo4j instance. Using this new dataset, we’ll go through another shortest path query between legislators.
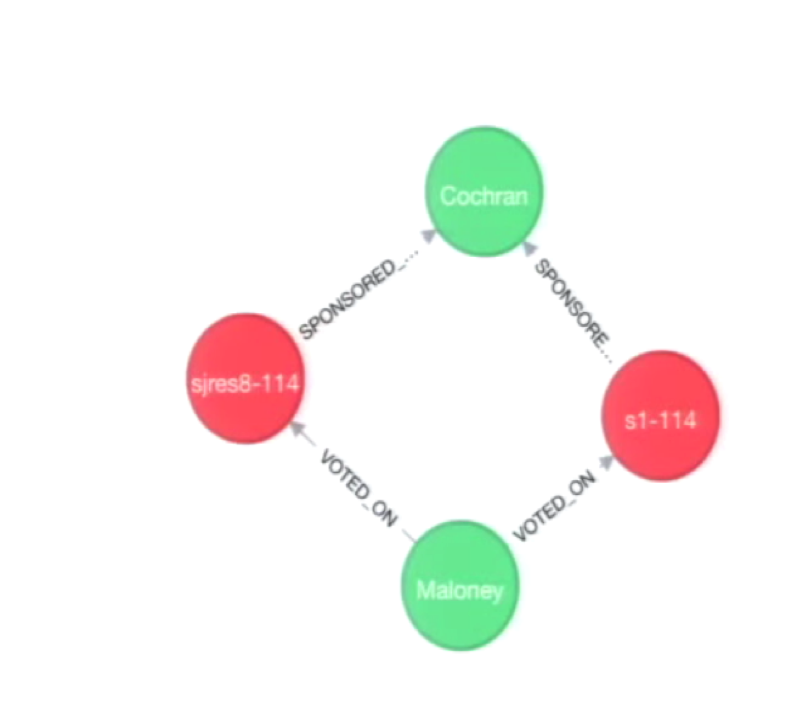
The dataset includes information about which legislators sponsored or co-sponsored certain bills. We are going to run a query to find allShortestPaths between congresswoman Carolyn Maloney and another legislator with the last name Cochran, up to three degrees of separation:

The results show us that Maloney voted on two bills that were sponsored by Cochran:
Subgraph queries with the Dijkstra algorithm
Shortest paths between airports
Another example comes from a database that contains all the airports and the distances between them. To find the shortest path between the San Francisco and Missoula airports, I wrote the following query:

You can’t fly directly from San Francisco to Missoula, so you have to connect through one other airport. But finding the shortest path doesn’t give you any indication of how much time the trip will take or how many miles it is. To find both of those answers you need to use the Dijkstra algorithm.
In the below example we have two airports, each of which has a distance property on the TRAVELS relationship, which we will use to calculate the ShortestPath based on distance. The Dijkstra algorithm is not currently built into Cypher, but you can call it directly through a REST API.

Below is the REST API call. The number 197909 towards the end of the URL is the node identifier, and we are trying to find the shortest path between this node and another node, which will be specified shortly. The REST API also contains our content type, the username and password and the machine:

Below are the contents of Dijkstra.json. I have the node that I’m going to, I specified the "cost_property" as distance, the "relationships" as travels and then perform an outbound traversal:

The REST API result, which can be parsed, looks like the following:
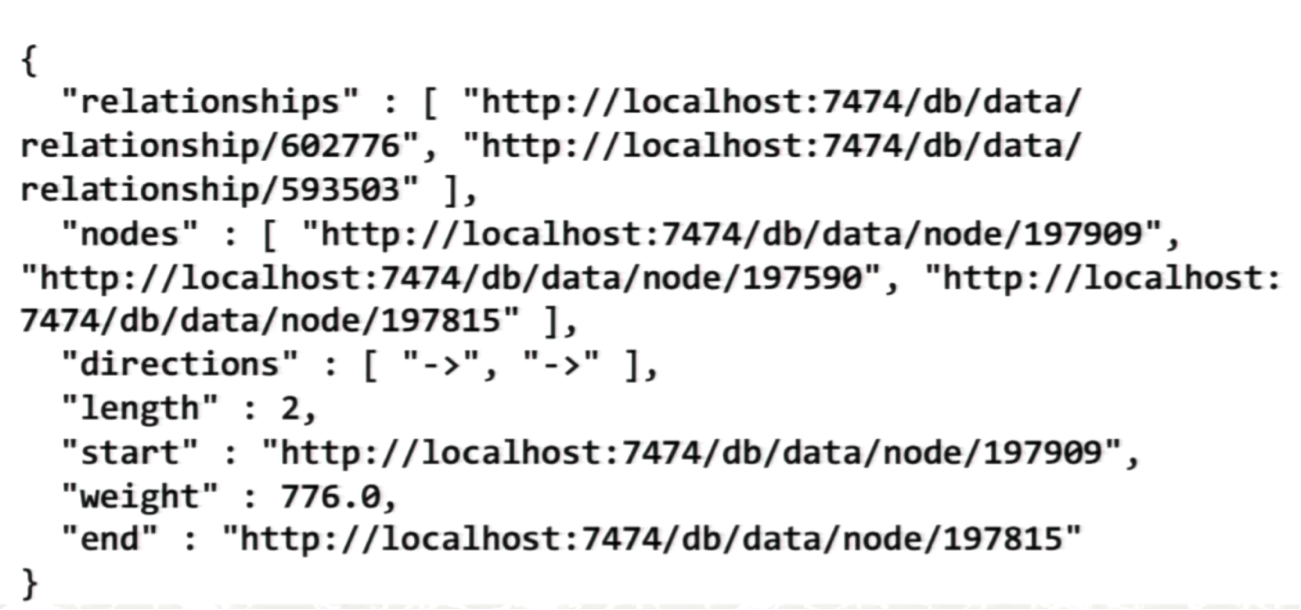
The first thing the results show are the ID numbers of all the different relationships and nodes. This is much easier to work with in the Java library than when you’re trying to bounce back and forth to the browser.
If I run the query in the Neo4j browser, it looks like the following:

That will return the following graph, which shows that the shortest paths between San Francisco and Missoula airports is through RNO, or Reno, Nevada.
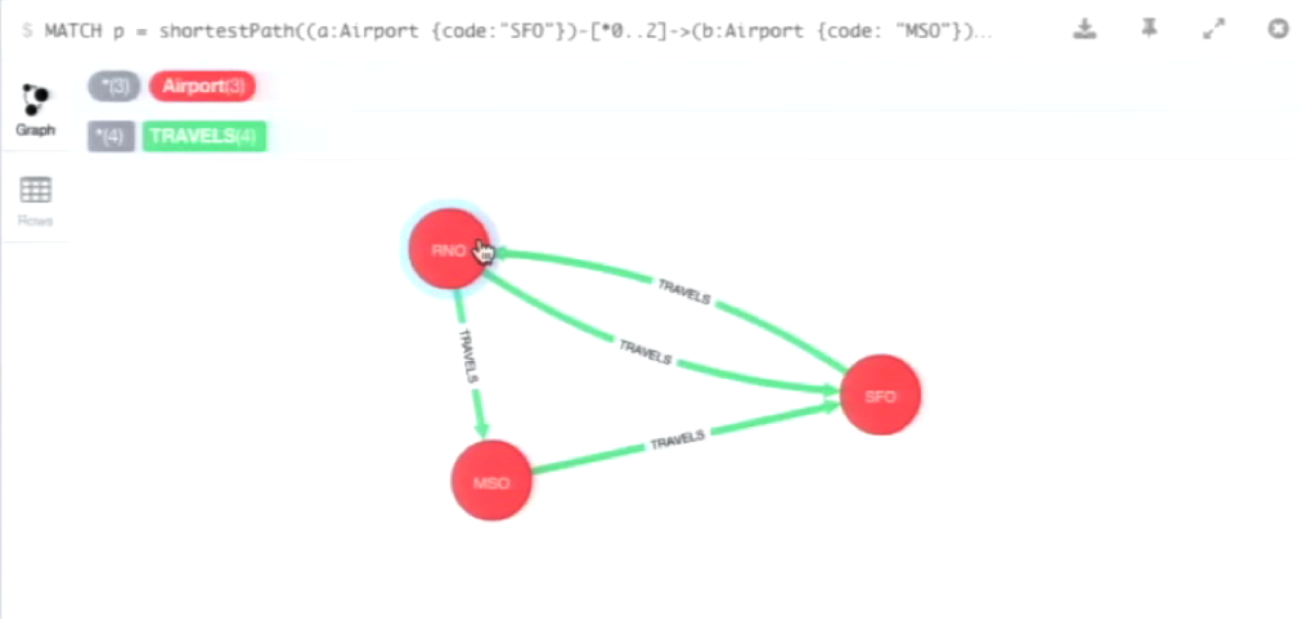
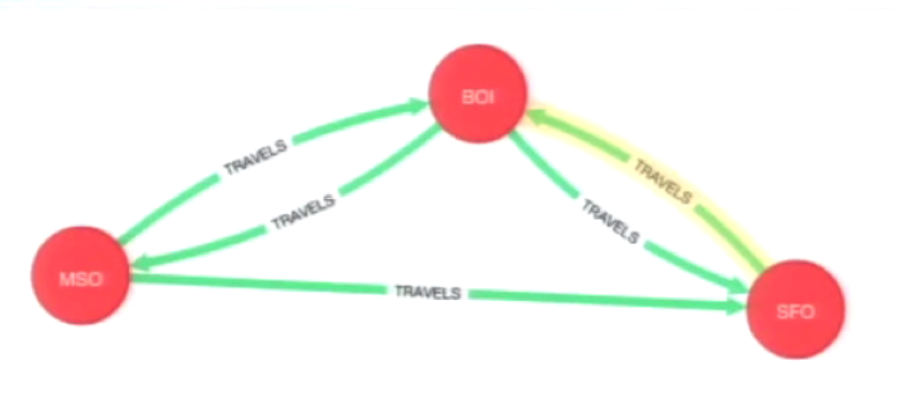
I also hand-parsed the earlier results from the Dijkstra algorithm, which tells us that flying through Boise is the shortest trip:
Global algorithms
You can also perform global algorithms through Neo4j by using extensions such as a Graph Processing — built by Max De Marzi and Michael Hunger — and a GraphAware NodeRank algorithm that performs PageRank.
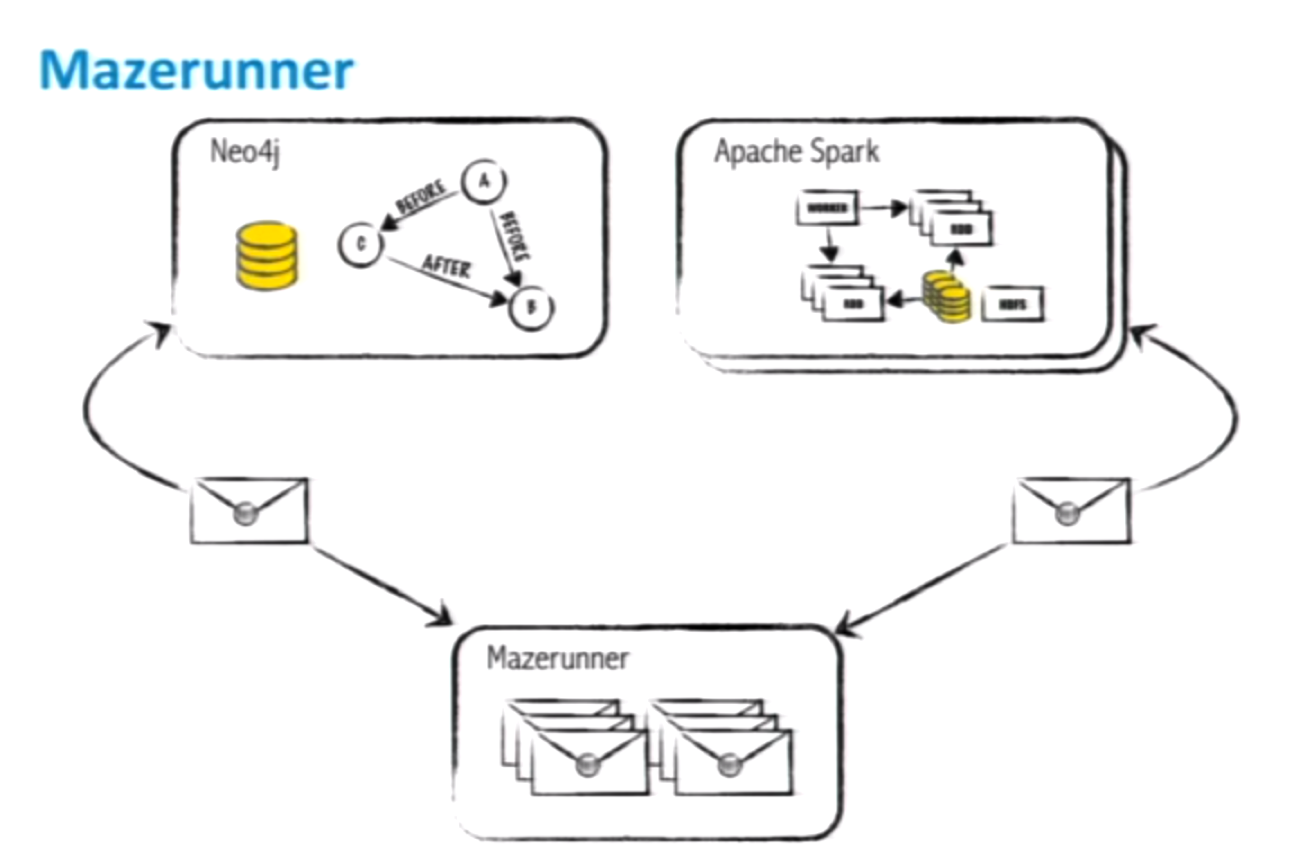
Global algorithms can also be performed using Spark integration through Mazerunner — built by Kenny Bastani — which allows you to run both Spark and GraphX jobs on top of your Neo4j data. Mazerunner is implemented in part as an extension and is the point at which all these tools fit together.
There are some concerns about using these extensions to run global algorithms.
The first issue is that most of these are batch jobs because they are too computationally heavy, so they won’t have the real-time results that you’ve come to expect from Neo4j. However, we can write the results from these algorithms back to our Neo4j datastore to allow for real-time queries. So you compute your results off of the data, put those results back into Neo4j and then use the graph to make real-time decisions.
There is also a computation performance challenge here: You don’t want to interrupt the real-time processing of your database. There are a couple different ways to prevent this.
Some people create a node in their cluster specifically for analytics which they sync with the original node, which allows them to run analytics queries on that node either through extensions or over to something like Mazerunner. You can also use an extension like GraphAware, which only runs when you don’t have many transactions occurring in your database.
Although there are certain limitations, there is a great benefit to using these integrations. In particular, Spark has a great community of people building different algorithms with GraphX on top of graphs that you can use.
Let’s go through a quick tour of Mazerunner, which as I mentioned was developed by Kenny Bastani but was officially turned over to Neo4j to manage moving forward. It’s an open application on Github, and we are always looking for feedback.
Global algorithms with Mazerunner
Mazerunner is based off of Spark — which is all about in-memory, large-scale data processing — and uses GraphX as the API for graph processing. Below is its general architecture:
To run this, you perform a query in Neo4j and call the Spark extension, which takes data out of Neo4j through Mazerunner and copies the data into HDFS, Spark and Mazerunner. It then reads that data out of HDFS, does memory processing, writes the results back to HDFS which are then picked up by Neo4j through the extension. It’s essentially a combination of a few different messaging queues.
We are going to use what I call the vanilla installation of Mazerunner using Docker Compose which combines a couple different Docker images: an HDFS node, the Mazerunner image and a Neo4j database:

You can also see the ports that the Neo4j database is mapped to. Volumes points to the actual volume where the Neo4j data is stored, which isn’t in the container because the container doesn’t persist. Then we specify links from Neo4j to Mazerunner and HDFS which allows network communication to occur between the two.
Next I type in docker-compose up, which starts each of the containers — HDFS, Mazerunner and Neo4j — and shows us the combined console output. At the end, it starts up Neo4j.

In Neo4j, we start on the same port and IP and enter our query. We want to find the legislators that have a strong PageRank, match those who are in the Senate and then return their names:

The query won’t return any rows right now because we don’t currently have any PageRanks.
Next I go to Mazerunner to get a URL issuing an HTTP GET from within the browser, which is an algorithm to run PageRank and includes the INFLUENCED_BY relationship to indicate sponsor and co-sponsor relationships:

The call was made, and you can see at the top that it exported the records 20000, 40000, and 60000 out of Neo4j:

You can also see next to Mazerunner Export Status that 100 percent of the requested data has been exported. Next, Mazerunner and Spark output their logs, which includes a lot of log data.
It’s important to note that PageRank isn’t computationally heavy. For those algorithms that are computationally heavy, it’s better to use a tool like Spark because you can distribute the processing across many different nodes, combine the results in a distributed file system — such as HDFS — and then load the data back into Neo4j. But it’s much faster to do algorithms like PageRank directly in Neo4j.
Below we can see that our job was completed, and that the data was written back to HDFS and loaded back into Neo4j.

If we run the MATCH statement again, all the senators with PageRanks are returned in order by most viewed:

We can see that Orrin Hatch is the senator with the highest PageRank.
If we remove the senate restriction and return the results for all legislators, you can see that the PageRanks for members of the House of Representatives are much higher:

Now we’re going to shut down Spark, which is really easy to do:

Global algorithms with Neo4j graph analysis
I’m then going to start up the instance with the Neo4j Graph Analysis extension:

This extension has the same mechanism for calling the URL as Mazerunner, but in this case I’m going to do it as a curl. In this case, the results come up much, much faster than they did with Mazerunner. This points to the fact that sometimes there are advantages to doing searches like this directly in Neo4j rather than through Spark.
However, when I tried to do a betweenness centrality algorithm earlier today on Spark, for which I gave only one single CPU of one machine, it took several hours. So if you have more computationally heavy algorithms, using Spark makes more sense because you can parallelize out the query to many machines.
You can also run a closeness centrality algorithm, which returns how close a node is to all other nodes in the graph and can be easily performed by these extensions. So there are a lot of different algorithms you can use within Mazerunner and the Graph Processing extension has a similar set of algorithms. If you use Spark, you get the added resource of the Spark community, but if you’re using Neo4j directly it may be faster for smaller, less computationally-intensive datasets.
Inspired by Ryan’s talk? Register for GraphConnect Europe on April 26, 2016 at for more industry-leading presentations and workshops on the evolving world of graph database technology.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3




Why machines need embeddings: Turning graph structure into features
