
Extending the Graph Database with Data Federation

Principal Software Engineer, Pitney Bowes
5 min read
Editor’s Note: Pitney Bowes is a Bronze sponsor of GraphConnect San Francisco. Register for GraphConnect to meet Paul and other sponsors in person.
One of the exciting applications for graph is master data management (MDM). By incorporating a graph database we extend MDM beyond the mastering of separate domains such as customer and product, enabling a rich, multi-dimensional view that provides insight into how these various entities relate across domains and business units.
The insight that is possible with a graph increases as more sources of data are integrated, but this doesn’t necessarily mean everything should be pulled into the graph.
Even if only a small portion of the graph is actively mastered and managed, there are costs in terms of storage and synchronization with external systems, so some balance must be found between maintaining data in the graph and leaving it solely in the enterprise systems. Ideally, if we embrace agility, we ought to allow this balancing point to shift as our organization continues to learn and grow.
Some sources of data may have qualities that can influence the choice of architecture used to store it. Data of massive size may force a distributed architecture while data that changes too rapidly may drive the adoption of an eventually consistent design.
The CAP theorem suggests that we are faced with three competing design goals: consistency, availability and partition tolerance.
If you can avoid integrating Big Data into your graph you can retain consistency and availability, and conversely, taking on Big Data leads to the potential for partitions leaving a choice between availability and consistency. Data federation can offer some additional flexibility in this area.
Spectrum Data Federation
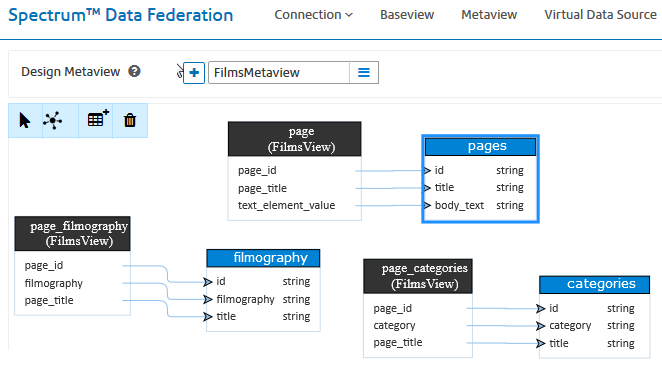
Spectrum Data Federation, part of the Pitney Bowes Spectrum Technology Platform suite of products, is a solution that allows a business analyst to define logical, business-oriented views of data, map these logical views to one or more connections to physical sources and publish these virtual data sources for use throughout the system.

Figure 1: Mapping metaviews to baseviews for Wikipedia pages.
Having this layer of abstraction between the logical and physical views is one way we enable agility.
If data is moved to new systems or data formats are changed, the published logical views can stay intact while the mappings and transforms to the physical views can be reworked in one central place, minimizing the cascading disruption that occurs when a system is changed in an integrated environment.
Graphs and data federation can be a powerful combination. By storing a reference to the federated data in the graph, one can achieve hybrid-style MDM, a blending of transaction style and registry style, where the graph is the authoritative source of truth for some data but for other data the source systems remain in control.
What’s Next in MDM Data Federation
While this hybrid style of master data management can be achieved with our currently available release of Spectrum MDM, we are actively pursuing an initiative to make the integration between the graph and federated data more seamless. The idea is to make federated data directly accessible from the graph.
With this goal in mind, we have created a tool that allows an analyst to designing the metadata for a graph and define the various entity types and the relationships between them.
They can indicate that an entity is “virtual,” meaning that it is persisted in one of the logical views of the federated data store. Each row of data in that logical view will be represented as a unique virtual entity.
In turn, Virtual relationships are created between graph-persisted “physical” entities and federated virtual entities by mapping a property of the physical entity to a column in the view that represents the virtual entity.

Figure 2: Editing the metadata for a relationship between a physical and a virtual entity
At run time, when a virtual relationship is traversed, a query is created that selects all target rows where the column matches the source entity’s property. These rows are presented as graph entities in the same manner they would if they came from the graph database itself.

Figure 3: Results from a query starting with a physical entity and traversing to two virtual entity types
Having federated data integrated with the graph database in this seamless manner is powerful. All the facilities that work with the graph – queries, security, discovery and visualization – can take immediate advantage of the federated data.
Consider the challenges associated with getting a project off the ground.
Sometimes what you need is a proof of concept to help validate the idea. You might start by building a model consisting solely of virtual entities from federated sources. Once buy-in is achieved the project can proceed with the creation of a physical copy of that data in the graph.
This level of agility goes beyond the separating of the physical and logical views mentioned earlier. Now we can hide from the rest of the data ecosystem the details of whether data is being fetched from federated systems or is mastered directly in the master data management graph.
Lastly, there is the flexibility to design a hybrid system from the perspective of the CAP theorem. Perhaps you have a large source of data, such as transactional data, Internet of Things feeds or data streamed from social media.
You can store this Big Data in a distributed store such as Cassandra and access it as needed from the graph. Only that portion of the model that resides outside the graph is subject to the potential latency issues associated with distributed architectures while the rest of the MDM graph performs as a consistent and available data store.
Finding the Right Balance
So what should be brought into the graph and what should be linked virtually to federated data?
One driving factor is that when linking to federated data you lose the index-free adjacency that graph databases provide. However, you pay that performance penalty only when accessing the federated data.
This option is ideal for cases where the federated data is very large, changes very rapidly, or is needed only in a subset of cases or situations where only a small portion of the data is needed at a time and the additional latency can be tolerated.
In cases such as these, a marriage of graph and federated data can be a compelling solution.
Come to GraphConnect San Francisco and visit our table to ask me about our work on federated data and graph databases.
Register below to meet and network with Paul Jackson of Pitney Bowes – and many other graph database leaders – at GraphConnect San Francisco on October 21st.
Share Article



Explore
Related Articles

Top 10 Graph Database Use Cases (With Real-World Case Studies)

Connecting Data Across the Enterprise: The 5-Minute Interview With Simone Novali


Neo4j as an Embedded Database: The Key Use Cases of Graph Databases

Neo4j as an Embedded Database: When Does Embedding a Graph DB Make Sense?
