


Graph Database vs. Relational Database: What’s The Difference?

Director of Corporate Storytelling & Content, Neo4j
15 min read

Selecting the right database remains one of the most critical decisions when building an application. While traditional database management systems like relational databases have dominated data storage for decades, the growing complexity and scale of modern application workloads—together with the need for flexible schemas, efficient handling of connected data, and seamless horizontal scaling—have driven innovation in database technology. Key-value stores like Redis, document databases like MongoDB, and wide-column stores like Cassandra each address specific needs in modern architectures. Among these alternatives, graph databases have proven particularly powerful for working with connected data, excelling in applications from supply chain management to recommendation systems.
More in this guide:
The Database Selection Challenge
Applications today need to deal with highly connected data more than ever. Social networks map user relationships, recommendation engines process behavior patterns, and fraud detection systems analyze transaction networks. Consider your e-commerce platform: You need to track product recommendations, user relationships, purchase histories, and category hierarchies while maintaining real-time performance. Traditional relational models require increasingly complex JOINs as these relationships deepen, while graph databases natively handle such interconnected data structures, at speed and at scale.
Why Database Architecture Matters
Your choice of database architecture directly impacts:
- Development velocity: How quickly can your team build and iterate on features?
- Query performance: Will your application maintain responsiveness as data grows?
- Scalability patterns: How will your system handle increasing load and data volume?
- Maintenance overhead: What operational costs will you incur in the long term?
Understanding how relational and graph databases fundamentally differ allows you to make better decisions for your applications. This guide is intended for developers and data professionals who want to understand the core differences between relational and graph databases. We’ll explore how these databases structure and manage data differently, helping you make informed decisions about which type best suits your needs.
How Graph Databases Are Reshaping Science and Society
Learn how graph databases help us explore space, cure rare diseases, increase crop yields, and much more.
Data Models: Understanding the Fundamentals
Relational and graph databases represent fundamentally different approaches to organizing and querying data. Understanding these differences can help you choose the right database for your application’s needs.
The Relational Model
The relational model is one of computing’s most successful and enduring innovations. Developed in an era when storage was scarce and expensive, it introduced a remarkably efficient approach to organizing and managing data that continues to prove its value today.
Table Structure
This time-tested model organizes data into tables with clearly defined structures. Each table consists of rows and columns, where rows represent individual records and columns define specific attributes. This approach elegantly handles many business scenarios, from financial transactions to inventory management, while minimizing data redundancy.
Schema Constraints and Flexibility
The relational model requires strict rules about data structure. Each table has a fixed schema that determines its columns and data types. This schema must be defined before storing any data because it defines what data can be stored and its format. This model does have its benefits; it ensures data integrity, and it served an important purpose in the early days of computing when storage was very expensive.
Relational databases have evolved significantly over the decades, and today’s computing environment offers cheap storage and powerful processing. However, the strict schema requirement persists. Any structural change—like adding a new attribute or modifying an existing one—requires changing the underlying table definition. This is particularly challenging for modern development practices where applications need to integrate diverse data sources, adapt to rapid requirement changes, and handle evolving data needs.
Primary/Foreign Key Concepts
In the relational model, keys are used to uniquely identify rows in tables (primary keys) and to document how data can be joined (foreign keys). A primary key identifies each record in a table, ensuring no two records are the same—like a social security number identifies a person or an order number identifies a specific purchase. As a best practice, every table typically has a primary key, which ensures each record stays unique and identifiable.
Foreign keys establish connections between tables by indicating how columns in one table reference the primary key in another table. For example, when an order table includes a customer ID that references the primary key in a customer table, that customer ID serves as a foreign key, indicating that the order table can be joined to the customer table using the customer ID. This ensures that each order always has a corresponding customer.
While this key-based system effectively maintains data consistency, it introduces complexity when modeling many-to-many relationships. These relationships require additional tables that store the primary keys from each related table, connecting records from two different tables. As data models grow more complex and interconnected, the number of these junction tables—and the JOINs needed to query them—can grow significantly.

The Graph Data Model
Graph databases take a fundamentally different approach, modeling data as a network of interconnected entities. This aligns naturally with many real-world data structures, from social networks to supply chains.
Nodes, Relationships, and Properties
Instead of tables, graph databases use nodes to represent entities. In place of foreign keys, graph databases use relationships to connect nodes. Both nodes and relationships can hold properties—key-value pairs that describe their attributes. This creates a rich, interconnected data structure that mirrors how we naturally think about connected information.
Flexible Schema Design
Most graph databases offer a fundamentally different approach to data structure. They allow flexibility across the entire range—from schemaless to fully typed data models with defined constraints.
This flexibility enables an evolutionary approach to data modeling. You can continue expanding your structure as your application’s needs grow and quickly adapt to changing requirements.
Adding new nodes, relationships, or properties doesn’t require changing existing data or rewriting application code. When changing the data model, you can add new types of nodes, new properties, and new relationships while leaving existing data untouched. Graph databases offer this flexibility while also providing tools to control data quality.
You can implement property constraints, enforce uniqueness rules, and validate data integrity—balancing agile development with reliable data management.
Native Relationship Handling
Unlike relational databases, which infer relationships through foreign keys, graph databases treat relationships as an integral part of the data model. These connections exist as first-class elements stored directly alongside the data points they connect.
This architectural difference fundamentally changes how systems handle connected data. Where relational databases must reconstruct relationships with JOIN tables, graph databases can traverse connections across highly connected with consistent performance regardless of the pattern’s complexity.
Architectural Differences
Data Representation
Relational databases optimize for storage efficiency through normalized tables, while graph databases optimize for relationship traversal through direct connections. This fundamental difference affects everything from query performance to scaling strategies.
Query Processing
The relational model processes queries through table scans and joins, combining data from different tables as needed. Indexes can help improve the performance of joins, but as the number of joins increases, query performance can degrade exponentially. Graph databases traverse relationships directly, following paths through connected data without needing the overhead of index lookups, hash joins, or other techniques for joining data.
Query Languages and Data Access
The way we query data reflects the fundamental differences between relational and graph databases. Each model provides query capabilities optimized for its underlying structure and data access patterns.
SQL: The Language of Relational Data
Relational databases use SQL (Structured Query Language), a declarative language designed for working with tabular data. SQL lets you express what data you want rather than how to retrieve it. This approach works well for:
- Filtering and aggregating data across tables
- Complex calculations and grouping operations
- Managing transactions and data modifications
However, SQL’s table-centric nature means that relationship-heavy queries require multiple JOIN operations, which can become complex and impact performance as the number of connections increases.
Graph Query Languages
Graph databases offer specialized languages for traversing relationships and finding patterns in connected data. These languages prioritize relationship navigation and pattern matching, making them natural fits for connected data problems.
Cypher: Created by Neo4j and now an open standard (openCypher), Cypher introduced an intuitive, visual way to describe graph patterns. Its ASCII-art-like syntax makes queries readable and maintainable:
- Nodes appear in parentheses:
() - Relationships appear as arrows:
--> - Patterns combine these to express the pattern that the query is looking for
GQL (Graph Query Language): As the first new database language to be standardized by ISO since SQL in 1987, GQL represents a significant milestone in database technology. This emerging standard reflects the industry’s move toward a unified graph query language, building on SQL and Cypher’s foundations while adding powerful new capabilities for graph operations.

Different Approaches, Different Strengths
These query languages reflect their underlying data models:
- SQL excels at set operations and aggregations across structured data
- Graph languages excel at pattern matching and relationship traversal
- Each optimizes for its primary use case while maintaining broad query capabilities
Understanding these query approaches helps developers choose the right tool for their specific data access patterns. For a deeper dive into graph query languages, take our free course on Cypher fundamentals and read more about GQL’s emerging capabilities.
Performance Characteristics
The performance profiles of relational and graph databases differ fundamentally based on their data models and query patterns.
Query Performance
Relational databases excel at operations within a single table but face increasing complexity with JOINs. Each additional JOIN increases the computational work required, particularly as data volumes grow. While indexing strategies can help, JOINs remain a compute-intensive operation regardless of optimization strategies
Graph databases take a different approach. By storing relationships directly, they maintain consistent performance even when traversing multiple levels of connections. Whether finding immediate neighbors or exploring complex relationship patterns, the performance depends primarily on the number of relevant relationships rather than the total data size.
Scalability Approaches
Both database types support scaling but with different performance characteristics. Relational databases traditionally scale vertically by adding more resources to a single machine. While horizontal scaling is possible through sharding, it often requires careful planning and can complicate queries that span multiple shards.
The scalability considerations for graph databases are different. For most applications, the performance bottleneck isn’t data size but query complexity. While relational databases slow down predictably as you add more JOINs—with queries becoming notably slower at 3+ JOINs—graph databases maintain consistent performance even when traversing multiple levels of relationships. Only the largest applications, processing billions of nodes and relationships, need to consider distributed graph scaling.
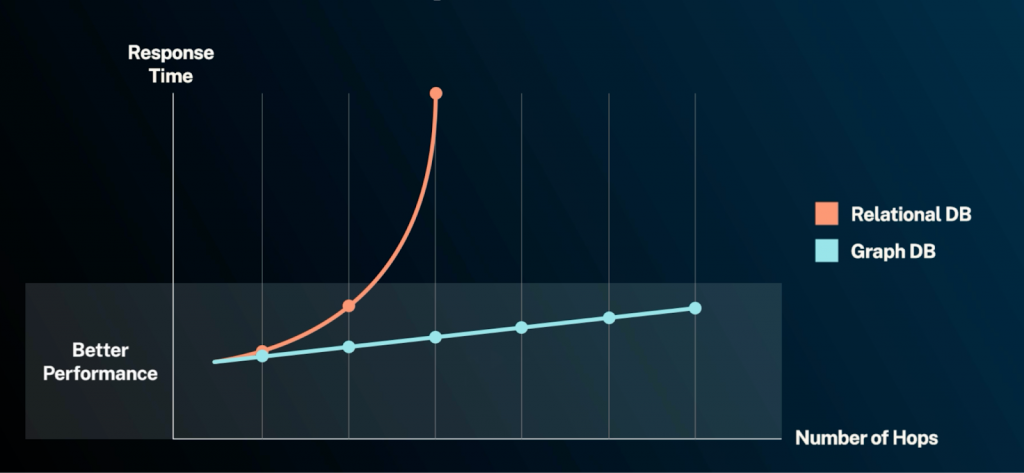
Real-world Performance Characteristics
The performance difference between relational and graph databases becomes most apparent when working with connected data. While both databases have optimized their core operations over decades of development, their fundamental architectures lead to different performance characteristics.
Operations with Simple Relationships
Both database types perform similarly for basic operations involving one or two joins. Relational databases handle these scenarios efficiently with mature optimization techniques and sophisticated query planners. Modern relational databases use advanced indexing strategies and caching mechanisms that make simple relationship queries like “find all orders for a customer” perform well. Graph databases, while architected differently, match this performance for simple relationship traversals.
Operations with Complex Relationships
Performance differences become more apparent as relationship queries grow in complexity. The root cause lies in how each database type traverses connected data. Here are typical examples:
- Finding friends-of-friends (3+ levels deep)
- Identifying patterns in transaction networks
- Computing recommendation paths through purchase history
In relational databases, each level of relationship requires an additional JOIN operation, with each JOIN multiplying execution time. The query planner must consider an exponentially growing number of possible execution paths. Because graph databases store relationships as native connections and traverse those connections using fast pointer lookups, traversal performance scales predictably linearly regardless of depth, unlike the computational overhead of constructing relationships through JOINs, which typically degrades exponentially with depth
Data Volume vs. Connection Depth
Understanding the performance characteristics requires considering two distinct factors:
- Relational database performance primarily depends on table size and JOIN complexity because they must construct relationships by matching keys across tables
- Graph database performance depends more on how much of the graph you need to traverse because relationships are pre-materialized as physical connections in the database
For example, in a social network with millions of users, finding a user’s immediate connections performs similarly in both databases. However, finding all users within three degrees of connection becomes significantly more efficient in a graph database because it follows existing paths rather than computing new JOIN combinations.
When to Choose Each Type
When choosing between relational and graph databases, consider your data’s structure and application’s needs. Each type excels in different scenarios – relational databases excel at structured data operations, and graph databases excel at handling connected data.
Relational Database Strengths
Relational databases remain the best choice for applications with structured, tabular data where relationships are relatively simple. With decades of development and optimization, they excel at handling traditional business operations that require strict data consistency and well-defined structures. Their ubiquity in computer science education and early development experiences means most developers understand how to effectively model and query relational data.
These databases particularly shine in:
Traditional Business Operations: Relational databases handle financial systems, inventory management, and order processing effectively because of their strict ACID compliance and mature transaction handling. Their consistency checks keep your business data accurate and reliable.
Structured Reporting: When your application needs complex aggregations and calculations across well-defined data sets, relational databases provide powerful tools for analysis and reporting. Their SQL-based querying makes it straightforward to generate business insights from structured data.
Fixed Schema Requirements: Use relational databases when you need stable data structures. Their rigid schemas maintain data quality and consistency across all your applications.
Graph Database Strengths
Graph databases excel when working with highly connected data where relationship patterns drive application functionality. Their architecture fundamentally changes how we can work with complex relationships in data. As businesses seek deeper insights from their data, understanding and analyzing relationships and patterns becomes increasingly critical.
They become the clear choice for:
Connected Data Exploration: Graph databases excel at traversing multiple relationship levels in applications like social networks, supply chains, identity access management, logistics networks, recommendation engines, and fraud detection systems. They explore connection patterns efficiently at any depth without requiring complex JOIN operations.
Knowledge Graphs: Graph databases power knowledge graphs – systems that connect and contextualize enterprise data and domain knowledge. Organizations increasingly use knowledge graphs to enhance search results, enable question-answering systems, and create 360-degree views of their data. Major tech companies like Google, Amazon, and Microsoft also use knowledge graphs to understand relationships between entities and provide more intelligent services.

Variable Data Structures: Most (but not all) graph databases adapt quickly when adding new types of data and relationships. Neo4j Graph Database allows you to add new attributes and connections without disrupting your existing operations or performing complex migrations.
Pattern-Based Queries: When your application needs to identify patterns within connected data —like finding influence networks, detecting fraud rings, or generating recommendations—graph databases provide both the performance and the intuitive query methods to make these operations practical. These capabilities are becoming increasingly important as organizations seek to extract more sophisticated insights from their interconnected data.
Choosing the Right Database
| Requirement | Relational Databases | Graph Databases |
| Data Structure | Fixed, tabular data | Flexible, connected data |
| Schema Changes | Requires formal migrations | Can evolve dynamically |
| Relationship Complexity | Best for simple relationships | Excels at complex relationships |
| Query Types | Set operations, aggregations | Pattern matching, patch finding |
| Performance Sweet Spot | Single-table operations | Multi-level relationship traversal |
| Development Speed | Slower with schema changes | Faster with evolving requirements |
Beyond the Basics
We’ve only scratched the surface in this comparison between relational and graph databases. While we’ve covered the key differences and typical use cases, there’s much more to consider when choosing and implementing your database solution.
If you’re interested in going deeper with graph databases, here are some resources to help you on your journey:
- Neo4j Docs: Graph Database Concepts
- GraphAcademy: Neo4j Fundamentals
- Tutorial: Getting Started with Cypher
- Migration: Relational Database to Graph
- Case studies: How Companies use Graph Databases
Read a Complimentary Gartner® Report on Knowledge Graphs for AI
Share Article



Explore
Related Articles

Neo4j Community Edition Advances for Graph-Powered AI and Intelligent Applications

Power Connected Intelligence for AI and Analytics with Neo4j and Databricks

Neo4j Brings High Speed Identity Resolution to the Snowflake AI Data Cloud

The Data Strategy That Makes Truly Personalized Customer Experiences Possible

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths
