


What Is Pattern Matching?


11 min read

Pattern matching is the practice of detecting specific structures, sequences, or connections within data. You may have encountered pattern matching in the context of strings or sequences, but its applications go far beyond that. At its core, pattern matching is about searching for meaningful patterns — whether shapes, trends, or recurring relationships — within raw or semi-structured data.
Typically, pattern matching requires you to know the patterns in advance. In contrast to pattern recognition, the match usually has to be exact: either it will or will not be a match.
Pattern matching helps us make sense of data by identifying recurring structures. Also, the technique isn’t limited to simple or known patterns — with the right tools you can explore unknown or emergent patterns to uncover insights you didn’t know to look for.
More in this guide:
Pattern Matching Explained
On a technical level, pattern matching means finding every instance of a certain data sequence that you defined in your query. For example, you might want to find similar products bought by customers in the same region within a short time window — revealing local trends or uncovering emerging demand. Once you define the pattern, a pattern-matching query will surface every instance that appears in your data.
You can use pattern matching to find answers in data that address business problems:
| Business Problem | Query the Data |
|---|---|
| How do I optimize my supply chain? | Can I find the most efficient route from source to delivery in my network |
| Which customers are likely to churn? | Do churned customers share any common product combinations or interactions? |
| Are there any fraudulent activities in my transaction network? | Are there unusually frequent or high-volume transfers between the same accounts? |
| Which raw materials pose a risk due to single-supplier dependency? | What happens if the vendor goes offline — who is impacted? |
Ultimately, pattern matching should be considered not only a technique but also a powerful strategic tool for filling a business gap with actionable data insights.
Why Pattern Matching?
Technical practitioners rely on pattern matching because it’s often the most straightforward and effective technique for solving real-world data problems, like:
- Anomaly detection
- Real-time fraud detection
- Supply chain optimization and bottleneck analysis
- Recommendation engines
- IT & network security
- Blast radius & impact analysis
- Drug discovery
- Customer behavior analysis
A single data entity doesn’t mean much in isolation. Data becomes valuable to an organization once it’s aggregated so that larger trends start to appear. However, large data volumes bring the concomitant problem of massive scale: too much data to sort through to be actionable in the moment. Since pattern matching involves quickly finding the patterns you’re most interested in, it cuts through the scale problem. It might seem overly simple, but Occam’s razor prevails here: what if one technique could help you solve all manner of business problems?
Use Cases for Pattern Matching
These use cases show pattern matching in a graph database, which doubles as an operational and analytics database. In traditional systems, analytics are typically offloaded to separate warehouses to avoid performance hits.
In a graph database, you can run real-time analytics directly on live operational data with minimal performance impact. For example, you could reroute a product in-flight through the supply chain as soon as a delay is detected.
Part of the reason pattern matching is so fast is that the Neo4j Graph Database offers native processing capabilities using index-free adjacency. Each node directly references adjacent (neighboring) nodes, making native graph processing time proportional to the amount of data processed. In other words, latency does not increase exponentially with the number of relationships traversed.
Since pattern-matching queries run across both operational and analytical data, you can spot emerging patterns and respond to incidents in real time. Let’s look at a few practical use cases where graph pattern matching makes a big difference.
1. Personalize Product Recommendations
When applied to transactional data, pattern matching helps you predict a user’s preferences or behaviors based on patterns of interaction between users and products. This use case focuses on questions related to purchasing patterns, such as frequently bought items and similar customer preferences.
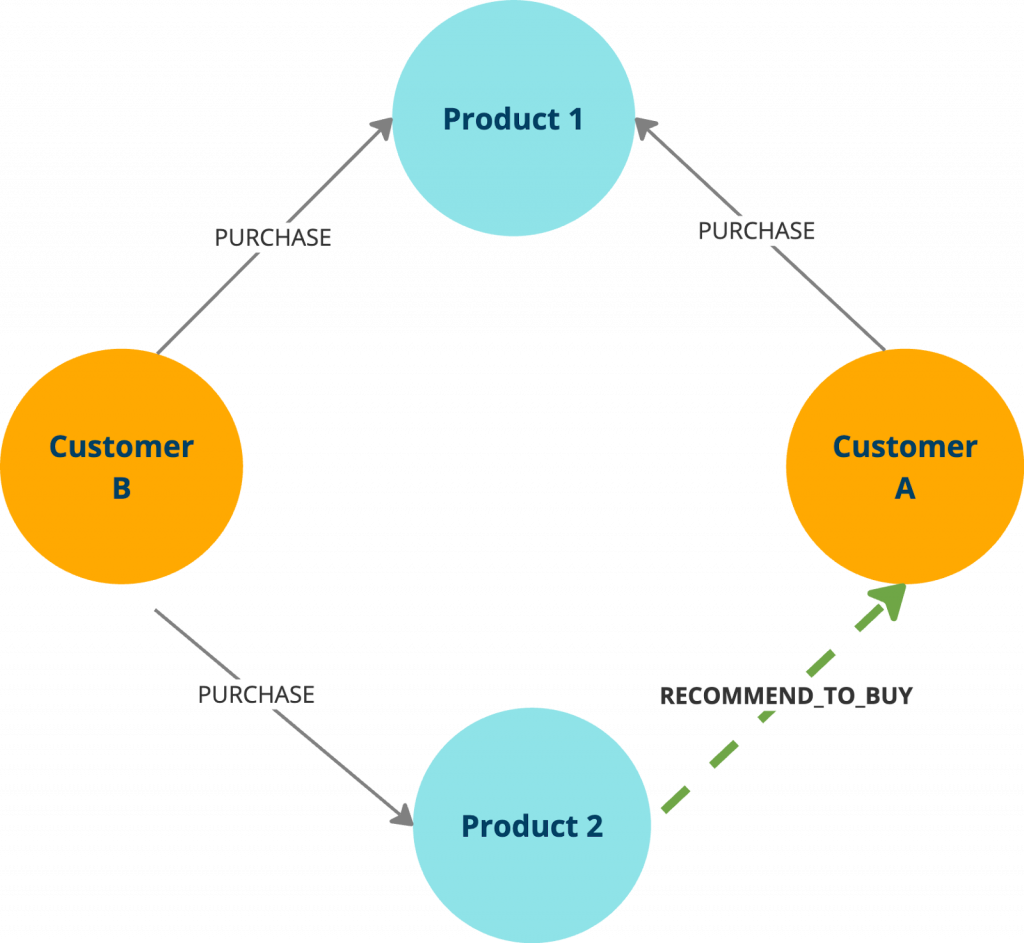
Collaborative Filtering Pattern
Use collaborative filtering to identify customers with similar purchase behavior to generate personalized recommendations. For example, if a customer bought product p1, you can find other customers who also purchased p1, and then surface additional products (p2) they’ve bought. The result: a list of frequently bought-together items, perfect for potential upsell and cross-sell opportunities.
MATCH (customer:Person)-[:PURCHASED]->(p1:Product)<-[:PURCHASED]-(other:Person)-[:PURCHASED]->(p2:Product) WHERE p1 <> p2 RETURN p1.name AS Product, collect(DISTINCT p2.name) AS RecommendedProducts, count(*) AS Frequency ORDER BY Frequency DESC;
Explore case studies from customers like What if Media and FSMB, who used Neo4j to power their recommendation engines and streamline operations.
2. Optimize Supply Chains
Modern supply chains aren’t linear — they’re dynamic networks of suppliers, manufacturers, warehouses, distributors, and retailers. The relationships between the diverse entities in a supply chain represent the flow of products through the supply chain. You can look for certain patterns in supply chain data to surface critical dependencies and remove bottlenecks.
Dependency Chain
The dependency chain pattern captures how entities connect in a multi-hop sequence — such as from a supplier to a manufacturer to a distributor. You can trace upstream and downstream relationships to understand how disruptions ripple through a system.
Whether you’re digging into cascading failures, troubleshooting messy workflows, or mapping out service chains, this pattern returns all downstream dependencies in the supply chain network that are connected. This helps you surface any bottlenecks, keeping your systems resilient.
// Traverse the dependency chain from Supplier A
MATCH path = (s:Supplier {name: "Supplier A"})-[:SUPPLIES_TO*]->(e)
RETURN nodes(path) AS dependencyChain, relationships(path) AS connections
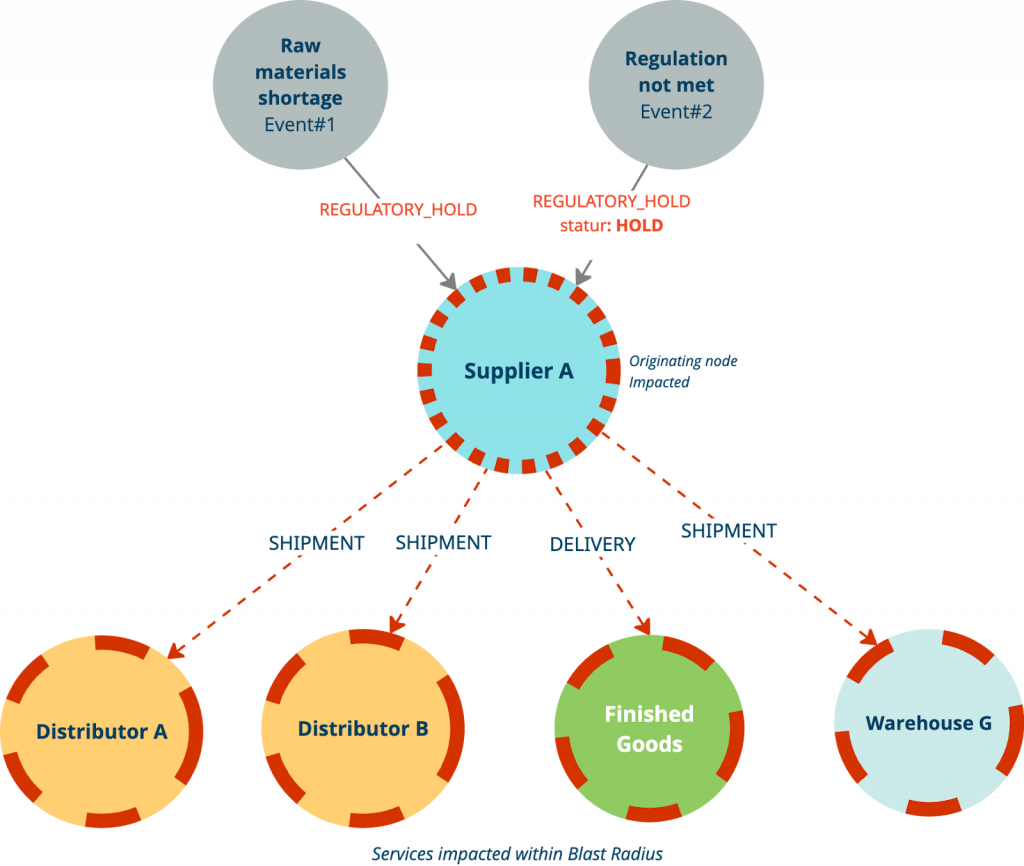
Blast Radius
Blast radius helps teams trace disruptions — like a delayed supplier or failed distributor — and understand how their impact ripples through interconnected systems. You can quickly identify affected downstream components and prioritize response. For example, the following Cypher query finds all entities impacted by a disruption — such as a supplier on hold — by traversing outbound relationships like SHIPMENT or DELIVERY. The query uses a variable-length path to go up to five hops deep and returns every entity along the way using `nodes(path)`.
This pattern is especially useful in domains like supply chain, logistics, and manufacturing, where a single failure can cascade across critical operations.
// Traverse up to 5 hops from the impacted supplier to find all
// downstream impacted entities
MATCH (s:Supplier {name: "Supplier A", status: "HOLD"})
MATCH path = (s)-[:SHIPMENT|DELIVERY*1..5]->(e)
RETURN nodes(path) AS impacted, relationships(path) AS connections
Note: This Cypher query uses “Variable-length paths — [*1..5]”, which is explained here
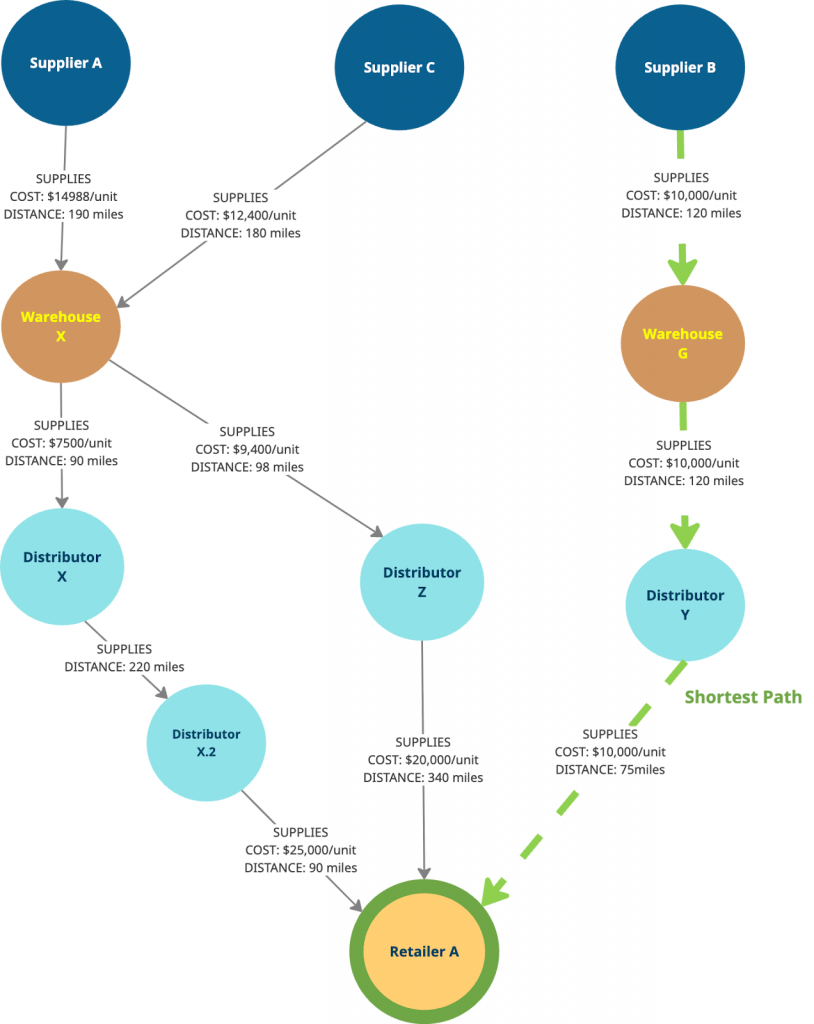
Shortest Path
The shortest path pattern finds the most efficient route between entities — for example, from a supplier to a retailer — based on distance, cost, or time.
When you query for the shortest path from “Supplier B” to “Retailer A” (as in the example below), the graph database traverses all intermediate entities, including warehouses and distributors. You can use the shortest path to optimize delivery routes, reroute around delays, or calculate cost-effective alternatives. The best part is that you can do this with just a few lines in Cypher.
Note: You can explore different variations of the shortest path pattern in the Cypher manual
MATCH path = shortestPath((supplier:Supplier)-[:SUPPLIES*]-(retailer:Retailer {name: "Retailer A"}))
RETURN nodes(path) as Path, reduce(totalDist = 0, rel IN relationships(path) | totalDist + rel.distance) AS Distance,
reduce(totalCost = 0, rel IN relationships(path) | totalCost + rel.cost) as TotalCost;
3. Detect Fraud
Detecting fraudulent activity involves uncovering deceptive behavior intended to result in financial or personal gain. Fraud can include tactics like identity theft, fake transactions, money laundering, or coordinated account manipulation. These behavioral patterns remain hidden in the data when you’re working in a relational database since they require numerous joins and other workarounds.
Circular Payments
A circular payment pattern is a common sign of financial fraud or money laundering. In this pattern, money flows through a loop of accounts and ends up back where it started. These loops can involve just a few entities or evolve into complex, layered fraud rings designed to obscure the origin of funds.
For instance, a circular transaction between three accounts might simulate legitimate transfers or be used to launder money. These patterns are hard to catch with traditional tools but become much easier to identify in a connected data model.
MATCH (a:Account)-[:TRANSFERRED]->(b:Account)-[:TRANSFERRED]->(c:Account)-[:TRANSFERRED]->(a) WHERE a <> b AND b <> c AND a <> c RETURN a.name AS AccountA, b.name AS AccountB, c.name AS AccountC;
Fraud Rings
Fraud rings are more sophisticated versions of circular payments. Instead of a simple loop between a few accounts, they form a web of transactions involving multiple users and shared intermediaries. The goal? To obscure where the money comes from and where it ends up. When you’re trying to detect these patterns, they often appear as long, tangled paths that loop or fan out.
In the example below, we’re looking for a fraud ring involving 3 to 10 transactions — a common range for these kinds of coordinated schemes. You can certainly increase the number of transactions in a query to look for more than 10 hops of transactions.
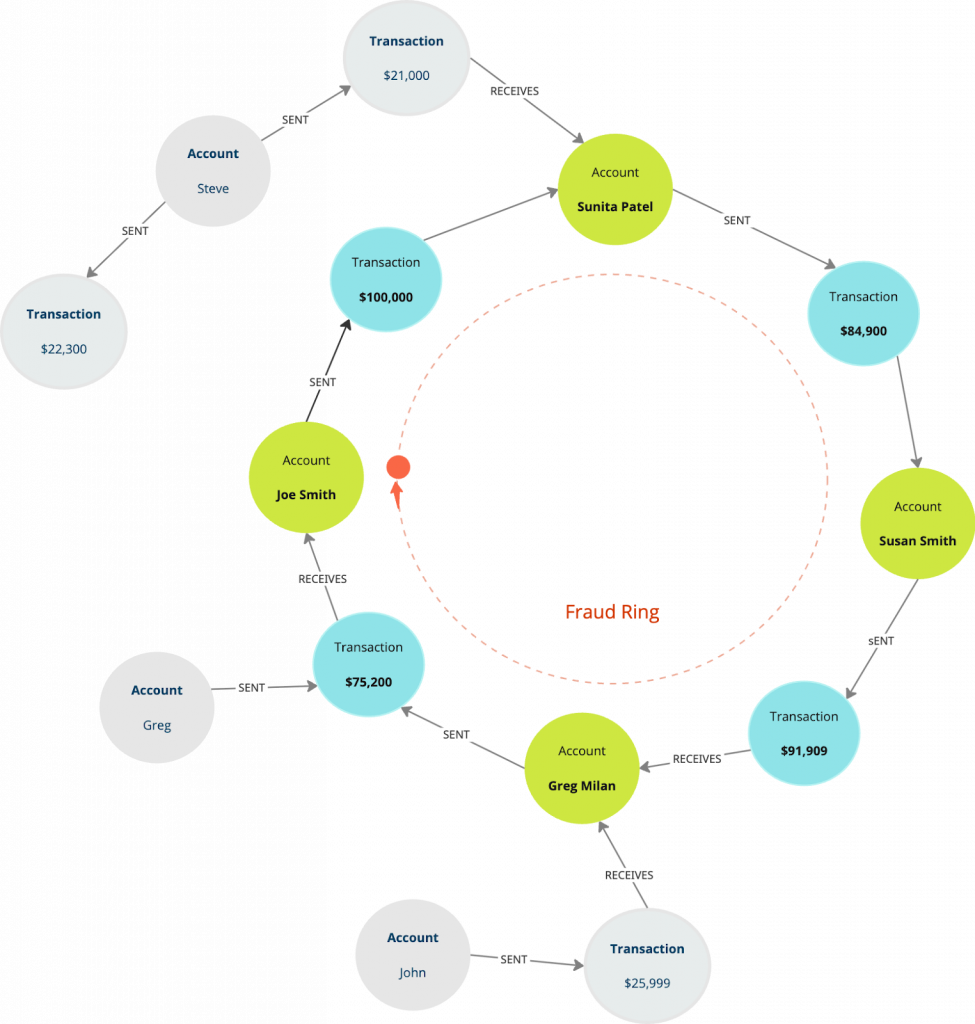
//Find a fraud ring with 3-to-10 transactions
MATCH ring=(a:Account)
(()-[:PERFORMS]->()- [:BENEFITS_TO]-()){3,10}(a)
RETURN ring;
Learn more details about transaction fraud rings and fraud detection strategies and solutions
Comparing SQL Query for Fraud Ring Pattern
If you wanted to find the fraud ring pattern above in SQL, it would require 80x-100x as much code, as you’ll see in the code example below:

This SQL query, which would take a long time to write, looks for fraud rings by chaining multiple account-to-account money transfers — up to 10 hops — and checking if the final recipient loops back to the original account. Each UNION adds another level of transaction depth (e.g., 3 hops, 4 hops, up to 10)!
Layered Transactions
Fraudsters often use layered transactions to obscure the origin of illicit funds. By moving money through multiple accounts, assets, or financial instruments, they can create layers of transactions that make it that much more difficult for you to trace the money back to its illegal source.
Graph pattern matching is very effective in tracking these complex and deep money trails. The Cypher query below looks for patterns where multiple customers make small withdrawals and deposits into a single account through several intermediary layers, which is a classic signal of layered activity:
MATCH path = (a:Account)-[:HAS_ACCOUNT]->(aDeposit:DepositAccount) -[:WITHDRAWALS]->(transactionA)-[:DEBITS]->(acctB) -[:CREDITS]->(transactionB)-[:DEPOSITS]->(bDeposit:DepositAccount)<-[:HAS_ACCOUNT]-(b:Account) RETURN p
Cypher vs. SQL: Which Is Better for Pattern Matching?
What Is Cypher?
Cypher is a declarative query language designed specifically for graph databases. Its syntax uses arrows (->, <-) to represent relationships. It represents patterns with a syntax similar to ASCII art:
MATCH path=(node)-[:IS_CONNECTED_TO]->(otherNodes) return path
By using arrows (->, <-) to represent relationships and directionality, Cypher makes it easier to express patterns that span multiple hops (or involve optional paths).
Cypher for Pattern Matching
Cypher is built for querying highly connected data. You can write flexible, recursive patterns (e.g., *1..5) to uncover deeply nested relationships. It eliminates the need for multiple JOINs by traversing relationships directly, which improves both readability and performance — especially in use cases like fraud detection or network analysis. Built-in functions like shortestPath, unwind, reduce, and collect make it easy to analyze paths and flows.
Variable-length paths in Cypher let you traverse an unknown number of relationships. With syntax like [*1..5], you can set minimum and maximum hops to explore paths in flexible data structures. In this example, the query finds up to five previous orders linked to the last order from customer ‘245253’.
MATCH path = (c:Customer {customerID: "245253"})-[:LAST_ORDER]->(o:Order)<-[:NEXT_CUST_ORDER*1..5]-(:Order)
RETURN path
Quantified path patterns in Cypher help to match repeated sub-patterns with precision. Let’s say you’re building a system for a bank that needs to enforce a strict separation of duties in its loan approval process. You want to ensure that no employee who submits a loan application — or anyone within their direct reporting chain — is allowed to review that same application. Using Cypher’s quantified path patterns, you can express this rule clearly and precisely.
For example, the pattern (:Employee|Manager)<-[:MANAGED_BY]-(:Employee)){1,4} is a repeated subpattern — not just a relationship — repeated 1 to 4 times, allowing you to capture chains of authority without needing to model each level separately. This makes it easy to detect and prevent conflicts of interest.
//Expresses a full sub pattern (a managerial chain), repeated up to 4 hops
MATCH (l:LoanApplication)<-[:SUBMITS]-(c:Customer)
((:Employee|Manager)<-[:MANAGED_BY]-(:Employee)){1,4}
(:Reviewer)-[:REVIEWS]-(l)
Learn more about Cypher.
Cypher vs. SQL for Pattern Matching
While SQL can perform pattern matching using joins and subqueries, it becomes increasingly complex and harder to maintain as relationships grow. SQL’s nested structure and need for temporary tables make multi-hop or recursive queries verbose and less readable.
Cypher, by contrast, is a dataflow language designed for working with connected data. It allows you to express multi-step, multi-hop patterns in a clear, top-down flow — passing data between clauses without temp tables. With Cypher, you write less code, manage greater complexity, and gain better performance for relationship-heavy queries.
Using Cypher With Other Languages
Languages like C# or Python can be used to execute Cypher queries via database drivers. But for pattern matching, learning the Cypher syntax directly is often more efficient.
Why Pattern Matching Matters
Pattern matching is a foundational technique for working with structured and semi-structured data. Many real-world data problems are inherently structural, reliant on joining multiple data entities to surface insights. Data alone won’t solve your business problems—it’s how the data is connected that reveals value.
The use cases outlined in this article are driven by the ways the data is connected and the data sequences you use to uncover patterns. Depending on your industry, you’ll find that the connections between your data take different shapes. Pattern matching allows you to define and detect these structures directly, whether as a loop pattern in financial transactions, the shortest path through a logistics network, or shared behavioral patterns among customers. With just a few lines of code, you can quickly find the solution to complex business questions.
Want to learn more about pattern matching from a use case? Read this free guide on how to find fraud patterns with Cypher.
Pattern Matching for Fraud Detection
Combine pattern matching, pathfinding, and machine learning for a faster, more precise fraud detection solution.
Share Article



Explore
Related Articles

Why Machines Need Embeddings: Turning Graph Structure into Features

A Complete Guide to Production-Grade PrivateLink Setup for Neo4j Enterprise Edition

Capgemini Turns Data and AI Into Connected Intelligence With Neo4j and Databricks

Neo4j Community Edition Advances for Graph-Powered AI and Intelligent Applications

Power Connected Intelligence for AI and Analytics with Neo4j and Databricks
