
Graph Databases for Beginners: The Basics of Graph ETL

Blog Editor, Neo4j
6 min read

他每天下午都在学校踢球。
Oh, sorry, you didn’t catch that?
Unless you read Chinese, it’s perfectly normal to be a little confused. No one understands all 6,500 existing languages on earth. Let’s go ahead and translate the sentence into something English speakers can comprehend.
他 — He
每天 — every day
下午 — evening
都 — every
在 — at
学校 — school
踢 — kick
球 — ball
While we’re getting closer, this direct translation still doesn’t make much sense. That’s because Chinese and English have very little linguistic relation to one another. Unlike the different Indo-European counterparts of English (like German, French, Spanish, etc.), Chinese comes from the entirely different Sino-Tibetan language family.
A translation tool that treats them like similar languages results in a sub-par result. To get it right, the translation process requires an approach that takes into account their distinctive origins, vocabularies, grammar, syntax and semantics.
Keeping this in mind, we can properly translate our original sentence:
他每天下午都在学校踢球。
He plays soccer at school every evening.
It turns out, translating between database models works the same way.
In this Graph Databases for Beginners blog series, I’ll take you through the basics of graph technology assuming you have little (or no) background in the space.
In past weeks, we’ve tackled the definition of a graph, why graph technology is the future, why connected data matters, the basics (and pitfalls) of data modeling, why a database query language matters, the differences between imperative and declarative query languages, predictive modeling using graph theory, the basics of graph search algorithms, why we need NoSQL databases, the differences between ACID and BASE consistency models and a (brief) tour of aggregate stores.
This week, we’ll discuss how ETL – i.e., the database translation process – works and walk you through the fundamentals of translating the legacy relational database model into a forward-looking graph model.
What Is ETL?
ETL stands for extract, transform, load. It’s the process of extracting data from one or more data sources (such as databases, files or spreadsheets), transforming the data into a different format/structure, and then loading it into a different system.
Let’s return to our previous translation example. First, we had to extract the meaning of the individual Chinese words, next we had to transform the syntax and semantics between the two language families, and then we had to load the translated words into an English sentence.
As a concept, ETL has been around for a while. ETL tools became popular in the 1970s, when organizations started to use multiple database systems to store different types of information and the need for data integration emerged. Over time – with the tremendous expansion of the number of data formats, sources and systems – the demand for ways to integrate them also grew.
ETL Tools 101
If ETL is a translation process, then ETL tools are the translators that get the job done.
The most common ETL tools convert a relational data model to another type of relational data model – naturally, since RDBMS has been prevalent since the 70s.
Most backend developers think of data stored in columns and rows, like in the relational model pictured below.
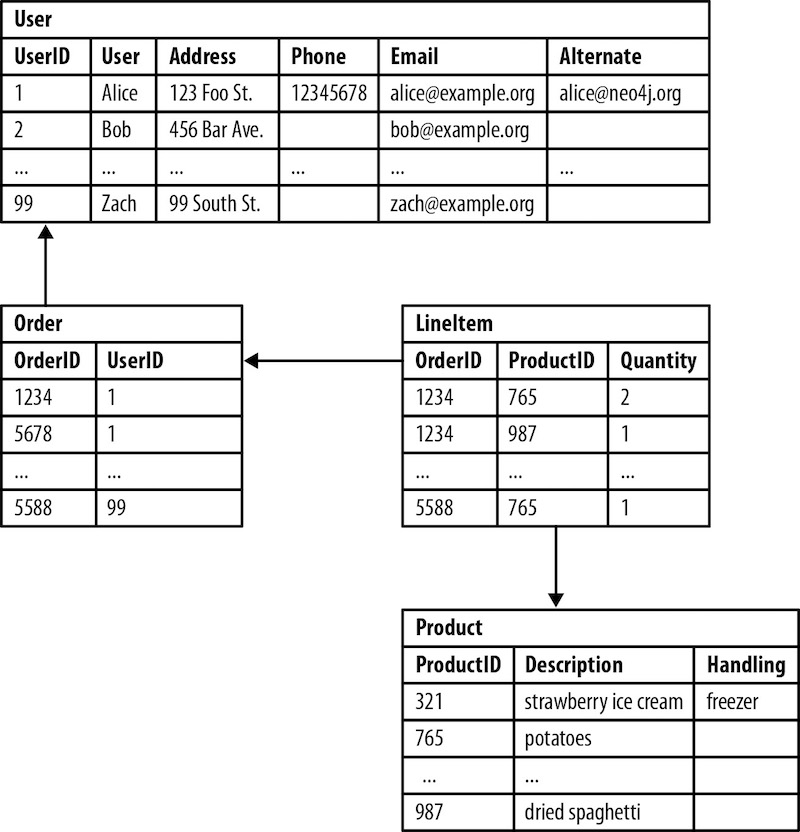
Relational databases like this one were initially designed to codify paper forms and tabular structures, and they do that exceedingly well. For the right use case and the right architecture, they are one of the best tools for storing and organizing data.
But data doesn’t exist in the form of columns and rows in the real world. In fact, it’s quite the opposite. Real-world data is increasingly connected and contextual. Just think about the data required to power use cases like these:
- Complex, international supply chains that take into account tariffs, regulations and changing legal environments as goods cross hundreds of different borders
- Sophisticated music recommendation engines that navigate similarities (and key differences) in genres, moods, artists, user feedback and hundreds of other vectors
- AI-powered chatbots that process and output data in natural language across a range of customer experiences, each with unique contexts
- GDPR compliance tools that have to track every byte of user data from first entry through every time it’s used across multiple applications
- Anti-money laundering efforts that have to work in real-time across a global financial system of heterogeneous data
But use cases like these – where data connections matter almost as much as the data itself – are beyond the capabilities of a relational database. As applications require more hops, more data types, more agility and more speed, RDBMS can’t – and won’t – keep up pace.
Under the hegemony of relational databases, it was natural for ETL tools to only need to convert between different types of RDBMS. But, with the advent of graph technology and other NoSQL databases, the ETL process now requires a new approach. Let’s take a closer look at how ETL works for RDBMS to Graph DBMS.
How Graph ETL Works
For an ETL tool that translates between two different types of RDBMS – like MySQL and PostgreSQL – it’s as simple as translating a sentence in British English into American English. It all comes down to basic tweaks, such as removing the “u” from “colour” or replacing a “flat” with an “apartment.”
On the contrary, translation between languages of distinct origins requires a little extra work. Likewise, converting the usual relational database model into the more efficient graph database model involves similar challenges. But that doesn’t mean it has to be difficult.
With powerful graph ETL tools, the whole process – extracting tables and foreign keys, transforming them into nodes and relationships, and loading those elements into a graph database – is much more straightforward than it sounds.
Let’s dive into a few examples. (Or take a deeper dive in our Developer Guide here.)
First, let’s take a look at a table with a foreign key. This scenario is treated as a JOIN and imported into the graph model as a node with a relationship, as you can see in the image example below.

Next, a table with two foreign keys is treated as a JOIN table and imported as a relationship.

Finally, a table with more than two foreign keys is treated as an intermediate node and imported as a node with multiple relationships. These multi-way JOIN tables often hide important concepts or entities in the domain.
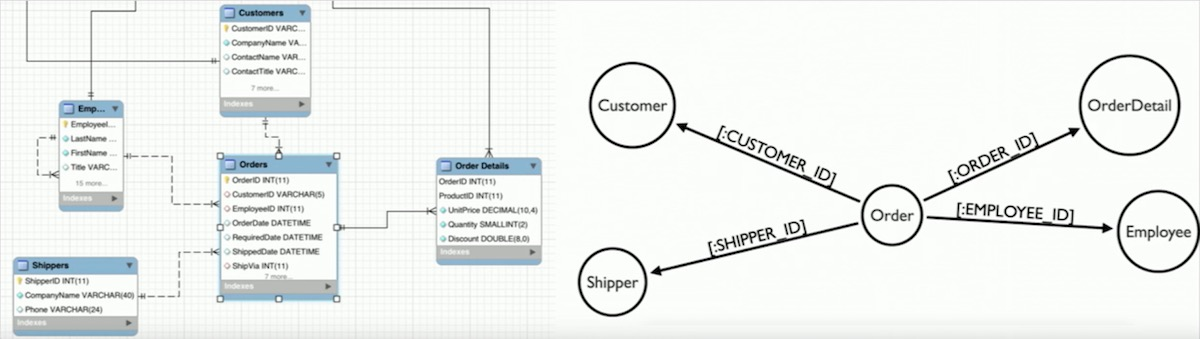
The final result?
Your new graph database model looks like the one below.
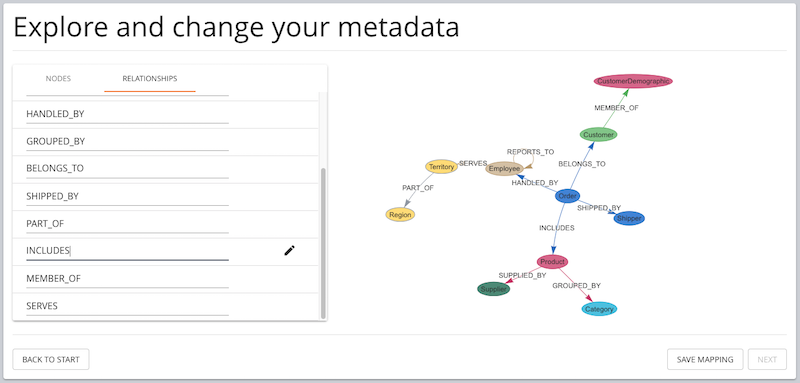
It’s worth pointing out that this is obviously a simplified example. A proper relational-to-graph translation starts by modeling your use case and then mapping each piece of information from the RDBMS model to the right place in the graph model. This approach helps you determine the most fitting graph data model to use for your domain.
Conclusion
While the conventional relational data model still dominates the world of databases, the importance of connections is becoming clearer every day. There is little doubt that graph data models are the future.
But, in order to translate those out-of-date tables into more true-to-life graphs, you need the right tools to ensure an accurate translation. Many teams try to do the job of RDBMS-to-graph ETL all on their own – but they don’t have to.
The Neo4j ETL tool is the easiest way to make it happen. The tool extracts the schema from any RDBMS – including MySQL, Postgres, Oracle, Cassandra, DB2, SQL Server, Derby and others – and converts it into a graph schema, without requiring any expert-level knowledge.
Check out our How-To User Guide to learn the whole graph ETL process from top to bottom: starting with an RDBMS and converting it to a graph data model.
Catch up with the rest of the Graph Databases for Beginners series:
- What Is a Graph?
- Why Graph Technology Is the Future
- Why Connected Data Matters
- The Basics of Data Modeling
- Data Modeling Pitfalls to Avoid
- Why a Database Query Language Matters
- Imperative vs. Declarative Query Languages: What’s the Difference?
- Graph Theory & Predictive Modeling
- Graph Search Algorithm Basics
- Why We Need NoSQL Databases
- ACID vs. BASE Explained
- A Tour of Aggregate Stores
- Other Graph Data Technologies
- Native vs. Non-Native Graph Technology
Share Article



Explore
Related Articles

What Are the Different Types of Graph Algorithms & When to Use Them?



Turning Your Tabular Data Into a Graph Using Cypher

Mix and Batch: A Technique for Fast, Parallel Relationship Loading in Neo4j
