
We’ve also recently added Northwind organizational data for those developers who are more business minded. Nonetheless, these datasets don’t capture the interest of all developers who work with a variety of types of data.
We wanted a dataset that everyone could feel a personal attachment to, so we decided to enable you to analyze your personal Twitter data in Neo4j!
In order to let the masses explore their Twitter data in an isolated environment, we decided to take advantage of the new Neo4j Docker image.
We set up a Neo4j Docker container for each user, running on Amazon’s Elastic Container Service (ECS).
Architecture

When a new user visits network.graphdemos.com, they are directed from one of the neo4j-twitter-head instances to login with their Twitter account.
This completes an OAuth 1.0a dance, enabling the Graph Your Network application to access the user’s Twitter data on their behalf. While most of the data being accessed is already public, acting on behalf of the user gives additional Twitter API quota and an ability to authenticate the user.
We then spin up a new instance, which runs the neo4j-twitter docker image, using the official Neo4j Docker image as the base.
This instance starts up Neo4j and then runs a Python script to import the user’s Twitter data into Neo4j. The credentials needed to do the import are passed into the Docker container using environment variables.
After Neo4j is started, the credentials are reset and the URL, username and password are provided to the user on a webpage. We also run some canned queries that are executed by the neo4j-twitter-head instances using py2neo calling your personal Neo4j instance.
Resource allotment
Each instance is allocated 1/4th of a CPU core and 768MB of memory. While this is only a small amount, it is adequate for the Twitter graphs of most users.
Since the number of EC2 servers needed to host these containers can depend upon the load, we have a cron job running regularly on the head instances which increases the auto-scaling group size appropriately or terminates instances.
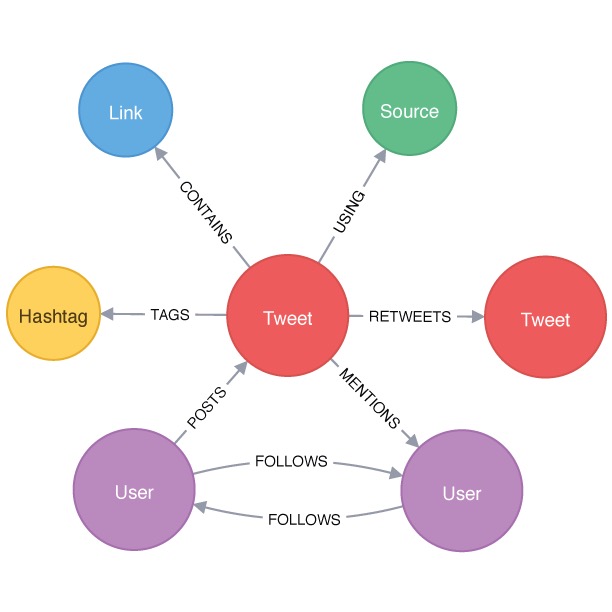
Imported data & data model

We import the following data:
- Your followers
- People you follow
- Your tweets
- Your mentions
- Recent tweets using your top 5 hashtags
- Recent tweets with #GraphConnect
- Recent tweets mentioning Neo4j
There are three separate threads running to call the Twitter API. When the threads hit Twitter API quotas, they sleep for 15 minutes. Your new tweets are imported every 30 minutes, and other data is updated every 90 minutes.
Example queries
We provide a set of example queries on the web app and in the tutorial built in the Neo4j browser, including:
- Who’s mentioning you on Twitter?
- Who are your most influential followers?
- What tags do you use frequently?
- How many people you follow also follow you back?
- Who are the people tweeting about you, but who you don’t follow?
- What are the links from interesting retweets?
- Who are other people tweeting with some of your top hashtags?
Browser guide
Some folks have wondered how we accomplished the built-in browser guide (shown below), invoked by :play twitter. This custom guide was added to a build of the Neo4j browser, which we then replaced in the neo4j-twitter docker image.
cd $NEO4J/community/browser vim app/content/guides/twitter.jade mvn package cp target/neo4j-browser-2.x.x-SNAPSHOT.jar $DOCKER_REPO/neo4j-browser-2.x.x.jar vim $DOCKER_REPO/Dockerfile add: ADD neo4j-browser-2.x.x.jar /var/lib/neo4j/system/lib/neo4j-browser-2.x.x.jar

What are your favorite queries?
Let us know if you discover some great queries! Share them with me on Twitter, on Slack or on the issue tracker.
Start exploring now!
Visit https://network.graphdemos.com/
Want to build projects like the Graph Your Network app? Click below to get your free copy of the Learning Neo4j ebook and learn to master the world’s leading graph database.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



