Neo4j blog
Welcome, GraphAware
Neo4j is acquiring GraphAware, our longtime partner and a leading provider of intelligence analysis software for government agencies.
5 min read

Featured voices



Most recent
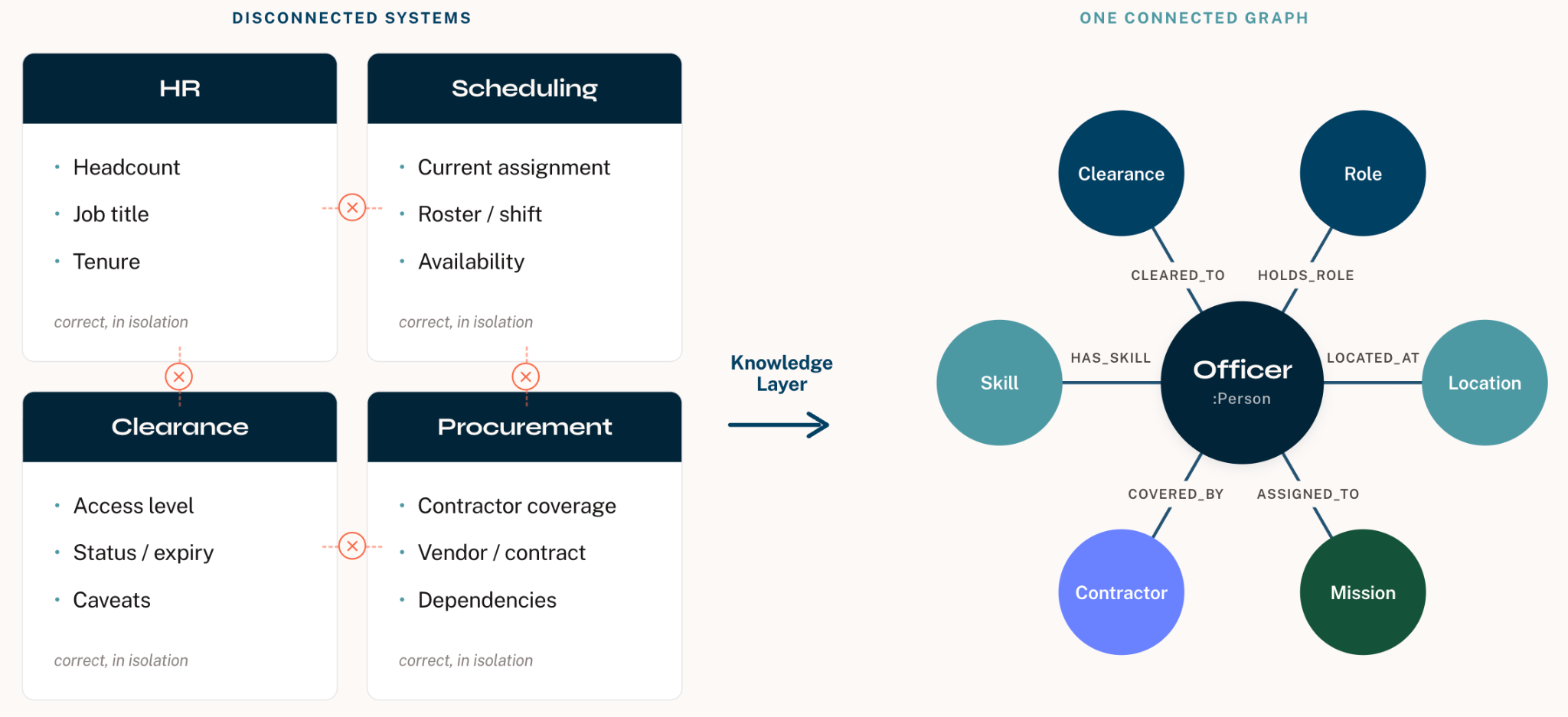

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks
9 min read

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher
7 min read




A workbench for teams to query, explore, and visualize graph data
3 min readNeo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report
3 min read
