
Ingesting Data into Neo4j for Master Data Management

Director of Evangelism, StreamSets
7 min read
Editor’s Note: This presentation was given by Pat Patterson at GraphConnect New York in September 2018.
Presentation Summary
In the following presentation, we’ll review how the company StreamSets ingests data into Neo4j for master data management. Streamsets was founded in 2014 to address the growing need for a data integration tool that could handle streaming and big data, and today have more than two million downloads worldwide.
The core problem most enterprises face is that data is spread out across a number of systems. Master data management, the practice of building a single point of reference from which insights can be drawn, helps tackle this issue.
In the following blog post, Pat walks us through a product support use case to demonstrate how StreamSets uses Neo4j to integrate and explore disparate data to uncover important connections.
Full Presentation: Ingesting Data into Neo4j for Master Data Management
What we’re going to be talking about today is how StreamSets uses Neo4j for master data management (MDM):
I’m a technical director at StreamSets, where I help companies unlock the value of big data. In the following presentation, I’m going to start by providing a bit of context surrounding master data management, and walk through a product support use case.
In this example, we’ll analyze customer support tickets and join data from different sources through the open source StreamSets Data Collector toolm and then move the data into Neo4j. I’ll focus on how to join and unify our data using Cypher, and how to derive insights from our data once it’s all together.
About Streamsets
The StreamSets founders have extensive experience in data integration and big data through their previous roles at Informatica and Cloudera. Through this work, they realized that the already-existing data integration tools failed to adequately address the world of streaming data, big data or NoSQL, and were instead still oriented towards a static schema in a relational database world.
This resulted in the creation of StreamSets. Today we have dozens of customers, half of which are from the Global 8000 and half which are comprised of smaller companies. Over 2,000 different companies have downloaded the StreamSets Data Collector, and we’ve seen over one million downloads worldwide:

Our tool’s broad connectivity is really what sets us apart, and we can connect to over 50 different data stores and streaming systems. The innovation in our engineering team goes right back to the dawn of Hadoop, and includes experts in Spark, Sqoop and Flume.
Master Data Management
The core problem in any enterprise is the fact that data is spread out across a number of systems according to its purpose, either on-premise or in the cloud.
Data also often overlaps, which can be a good thing if we want to correlate between data in different places using common identifiers. But too much data overlap is a pain point, because it obscures the “source of truth” for any given piece of data. It’s also difficult to draw insights from data scattered across multiple systems.
Master data management is the practice of building a single point of reference from which insights can be drawn. Traditional master data management required copying data into a relational database – but what if we use Neo4j or another graph database?
The rest of the presentation focuses on how we build systems that synchronize data into a single location with Neo4j.
The Use Case: Product Support
In this use case, we’re going to explore a customer service platform (SaaS) that holds support tickets statuses and assigns tickets to support engineers. Data points includes features like the status priority, the date the ticket was opened and the subject. In addition to our support engineers, our managers can also log in to view the ticket status.
Our on-premise, relational HR database system serves as the source of truth for our organization’s reporting hierarchy, so if there’s any discrepancy between the SaaS customer service platform and the HR system, the HR system wins.
Finally, we have a simple device monitoring system that provides fault data in the form of a flat, delimited files.
The question is: How can we bring all of this together to obtain a holistic view that allows us to run queries, from faults all the way through to the reporting hierarchy?
This is where StreamSets comes in. It’s a highly-flexible platform for DataOps that operationalizes the flow of data around enterprises:
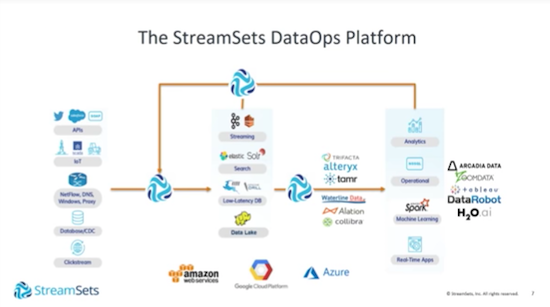
There are about 50 different systems we can connect to, including APIs, IT platforms, firewall, web server logs and databases. We partner with Cloudera, MapR and Databricks, and we can write data into Hadoop, Amazon S3, Google Cloud and so on.
Together, all of these tools enable analytics. We typically read operational data stores and write into analytical big data stores for the purpose of drawing important insights.
But in short, we think of ourselves as a Swiss Army knife for data. We can build data pipelines that source data from dozens of possible sources, transform it and write it to a similar number of destinations.
Incorporating Neo4j
About 18 months ago, one of our financial institution customers was interested in writing data into Neo4j for analysis. After some exploration, it became clear that working with Neo4j from the StreamSets standard tools was very straightforward. The below pipeline shows how we read data from delimited disk files, the four different transformations we perform, to then finally write that data to Neo4j:

Through this exercise, I discovered that the Neo4j JDBC driver is a high-quality and performant tool for these purposes. We can then use Cypher to efficiently create nodes and relationships.
The Neo4j JDBC Connector is not a part of the Neo4j product per se, but is the official JDBC driver developed by an Italian company called Larus BA. I’ve worked with a lot of JDBC drivers, and quality can be highly variable – but this driver works really nicely, and I haven’t had any problems with it.
This JDBC Connector can use either Bolt or HTTP/HTTPS. Bolt is the protocol used by the .Net, Java, JavaScript and Python Neo4j drivers, and is a binary/TCP protocol that the Neo4j drivers use to communicate with the server.
Bolt sends about 1/10 the number of bytes over the wire when compared to JSON/HTTP protocol, so we recommend using Binary/TCP. And happily, Bolt is the main, default method of integration in Neo4j.
When you set up JDBC, you’ll need a URL in this form: jdbc:neo4j:bolt://hostname. Neo4j selects the JDBC driver, and then Bolt selects that protocol and then the host name.
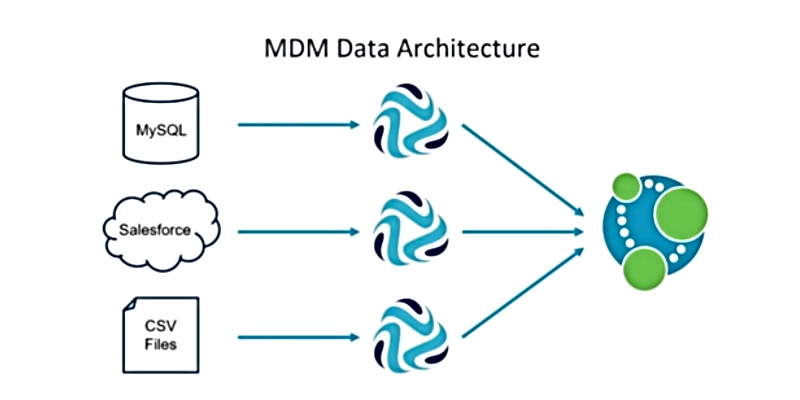
The MDM Architecture
I built a very simple MDM data architecture that reads data from MySQL, support tickets from Salesforce (although you could use any support ticket system) and flat .CSV files. I do some transformation in the third pipeline and unify them in Neo4j:
The goal is to create a graph of this data:
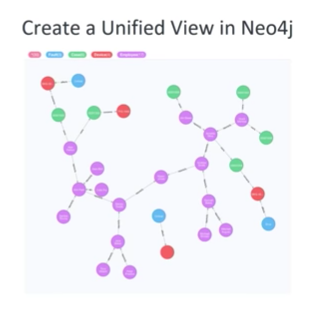
The purple nodes represent employee data, and if you were to pull on the right place in the graph, you would see the nodes settle out into a reporting hierarchy: the employee data comes from our HR employee database, the green nodes are support tickets coming in from Salesforce, and the red nodes are devices, which connect the tickets to the blue device fault nodes coming in from our IoT system.
Watch the below video clip for a live demo of how we ingest all of this data into Neo4j:
Watch the following demo to learn how we write data into Neo4j:
The below demo shows powerful of Cypher queries in action, which perform searches that cannot be done in a relational database:
Watch the following demo to see how we apply ticket priorities to our Salesforce cases:
The last demo shows how to transform device fault data:
Other Common StreamSets Use Cases
Writing data into Neo4j isn’t the only use case this tool can be used for:
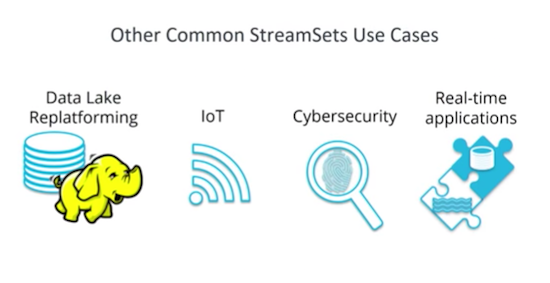
We do a lot of work on data lake replatforming. We build data lates in Hadoop and partner with big data products created by Cloudera and MapR. In the IoT world, there’s a lot of data to be read in devices in the IoT platforms.
We also bringing data together for cyber security use cases, where we parse continuous streams of real-time data in the form of log files from firewalls, web servers and other equipment. We also integrate with Kafka and other message systems.
We also have some great customers:

The major pharmaceutical company GlaxoSmithKline uses StreamSets to bring data together from all of their drug discovery systems, such as drug trial data, into a single data lake so that their scientists can make more effective use of that data.
Cox Automotive built a group-wide data lake with data from all of their subsidiary companies, and the healthcare company Availity found that StreamSets allowed them to more efficiently move data between different systems.
Why Neo4j?
Neo4j can provide insights into master data that are simply not available when data is spread across silos or collected in a relational model.
We also learned that Neo4j’s JDBC driver is an excellent tool for bringing together standard applications that use the JDBC interface with Neo4j. And StreamSets Data Collector can read data from a wide variety of sources, and write to Neo4j via Cypher and the JDBC driver.
Below are some references for additional learning:
Share Article



Explore
Related Articles

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English




Integrating Neo4j With Symfony: Profiling Queries and Centralized Logging
