
You Want Some Join Context? Neo4j Has You Covered

Senior Pre-Sales Consultant, Neo4j
4 min read

Joining data in databases is a long-standing way of linking data together. A join in a database is a link between two relations that is materialized at run-time on data access. Many approaches have been taken by vendors over the years to optimize joins, some very innovative.
The Problem with Joins
What none of these solutions do is provide context to a join. It’s not within the ambit of SQL to do so either. The closest you will get is some comments or a description of a foreign key constraint.
In order to get context, it requires some modeling within your data and more effort on your part. Sometimes you may infer from the table names some context about the join. For example, linking a customer table to a products_owned table returns products owned by customers.
select t1.name, t2.name from person t1, products_owned t2 where t1.customerId=t2.customerId
The Solution
Native graph database Neo4j stores these relationships as first-class citizens because they provide mission-critical context. And we do more than that; we give it a name and call it a relationship type. Like this:

This looks like a conceptual diagram. Well, in Neo4j the concept is the data.
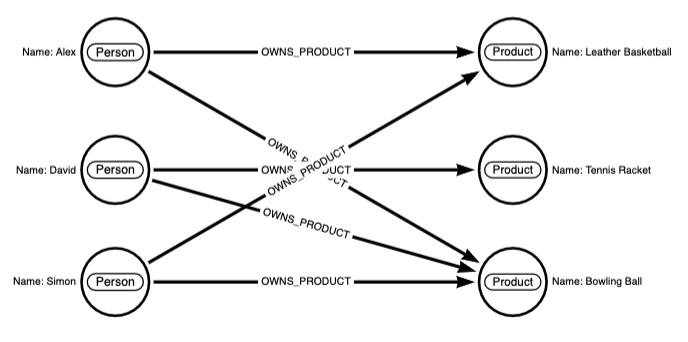
The data is stored the way you think about it. Ruminate on that for a moment. It’s quite a departure from traditional methods. Neo4j databases have no concept of tables and rows, rather they’re stored as graphs, which are composed of the following:
- Nodes represent an entity or a thing. In the example above, there are six nodes.
- Labels are used to classify nodes. A node may have one or many labels. In the example above there are
PersonandProductnodes. - Relationship types describe links between nodes.
OWNS_PRODUCTis a relationship type in the above example. - Properties are attributes associated with nodes and relationships. In the example above, Name is a node property. Indexes can be created on properties.
Now let’s look at a different example.
Andrew is employed by David, who is his uncle. They sometimes play golf together and David is the guarantor for a loan that Andrew took out. It’s value is $10,000. (What an uncle!) Think about what sort of structure you would need to support this and how to query it.
The SQL Way
The SQL aficionados among you will already be forming an opinion on how to model this.
Here’s a quick mockup I did in Postgres. Probably not perfect, but not too far off the mark.
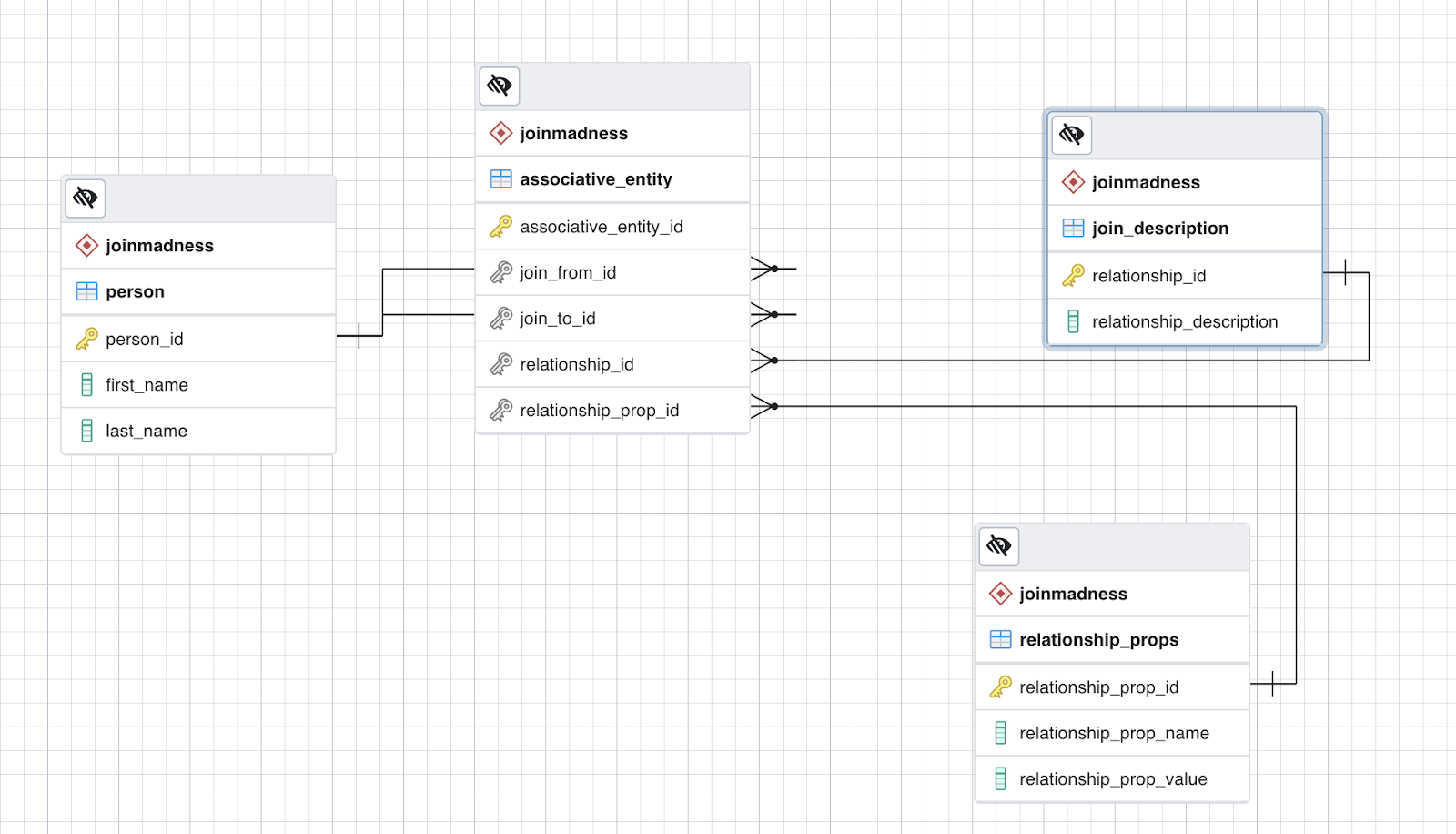
Here’s your key:
- person: basic information about an individual.
- associative_entity: I used modeling parlance to name this table. It pulls together two people and the relationship/s they have.
- join_description: a reference table that houses context for any join.
- relationship_props: a reference table that houses properties for relationships.
Without join_description you do not get an understanding of what the link between people is, and without relationship_props you don’t get further information about the relationship.
To query this structure, we need to issue a complex query with a number of joins.
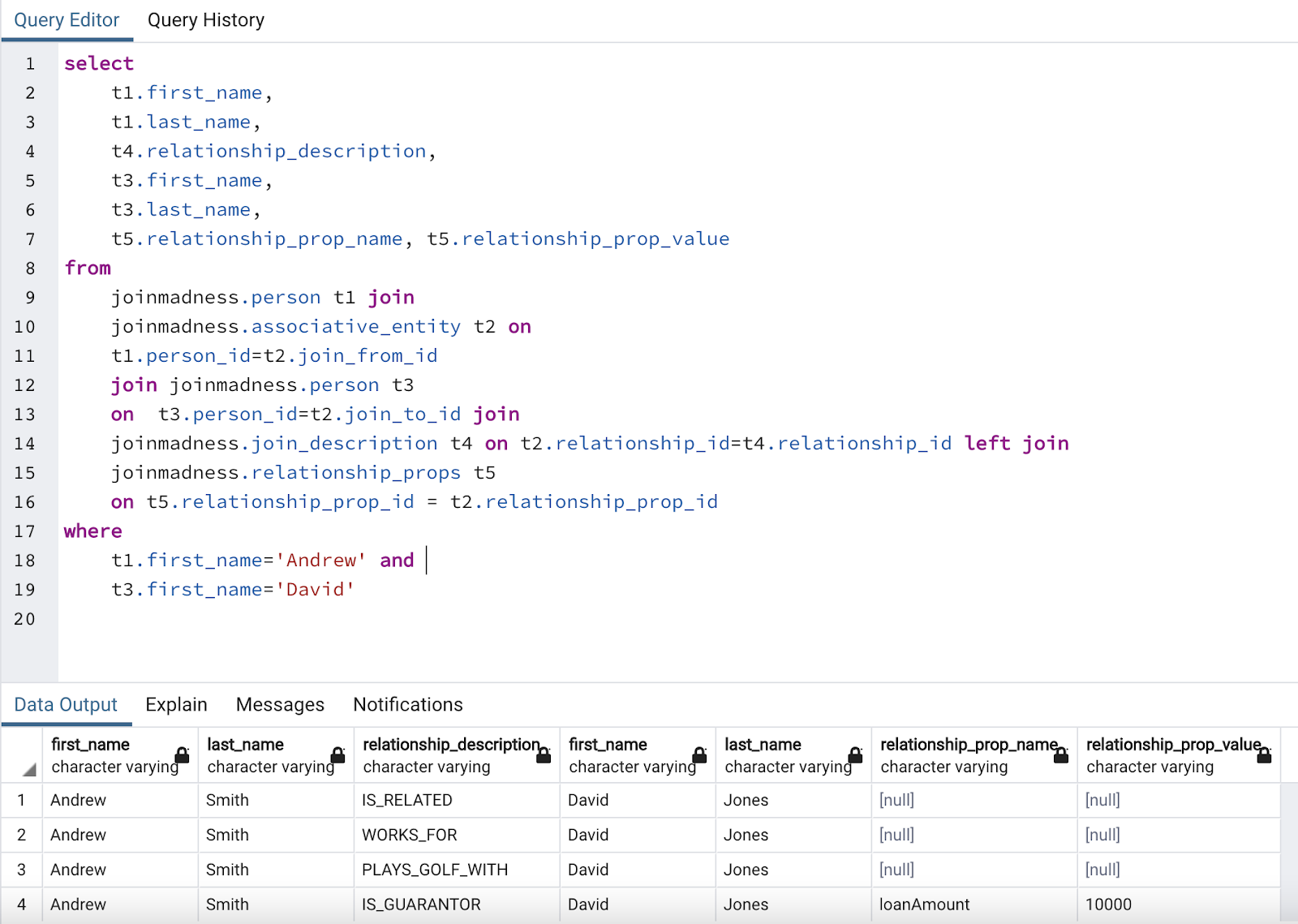
Well, I get the answer, but at significant effort and complexity. There’s a left join in there too, because there may not always be a property on a relationship, and I have to mention the person table twice. It may be modified to use a “connect by” clause in some databases, but it’s still complex.
The Graph Way
Let’s take a look at how it would be done using Neo4j Graph Database. In the example below, two nodes with the label person exist. One for Andrew, one for David. The relationship types are there in plain view.
In Neo4j we store relationships as first-class citizens in the data, which means these can be specified in our queries. These relationships are not materialized at run time as in a SQL query. The performance benefits over traditional data stores can be incredible (millisecond execution), as join processing is a very onerous step in a relational query.

Here’s the Cypher script to create the graph. The two person nodes are built using the create command, and merges are used to create the relationship. There are a number of different ways this could be coded, but writing Cypher code is a topic for another time.
create (p:Person {personId:1})
set p.name='David'
create (p2:Person {personId:2})
set p2.name='Andrew'
merge (p)-[:IS_RELATED]->(p2)
merge (p)<-[:PLAYS_GOLF_WITH]-(p2)
merge (p)-[:WORKS_FOR]->(p2)
merge (p)<-[:IS_GUARANTOR {loanValue:10000}]-(p2);
Here is one example of how to query the database.
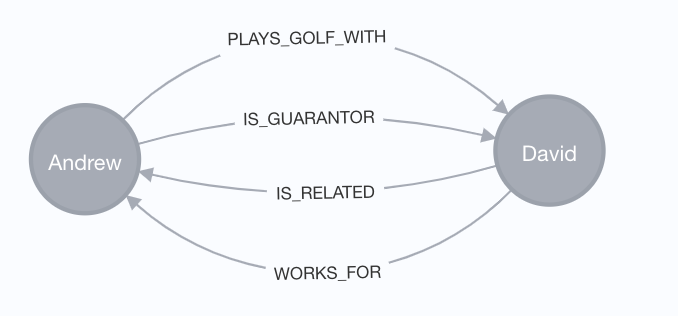
Using Neo4j Desktop, I can issue the following Cypher Match commands specifying the person nodes observing all relationship types.
match (p:Person)-[r]-(p2:Person) Where p.person='Andrew' and p2.person='David' return p, p2
We generate a nice visual of the query results.
To return a tabular result the Cypher may look like this:
match (p:Person)-[r]-(p2:Person) where p.name='Andrew' and p2.name='David' return p.name as Person1, type(r) as RelationshipType, r as RelationshipProps, p2.name as Person2

Note that referencing relationships like this [r] will return ALL relationships. If I am interested in a specific relationship, IS_GURANTOR for example, the query could look like this:
match (p:Person)-[r:IS_GUARANTOR]-(p2:Person) where p.name='Andrew' and p2.name='David' return p.name as Person1, type(r) as RelationshipType, r.loanValue as LoanValue, p2.name as Person2

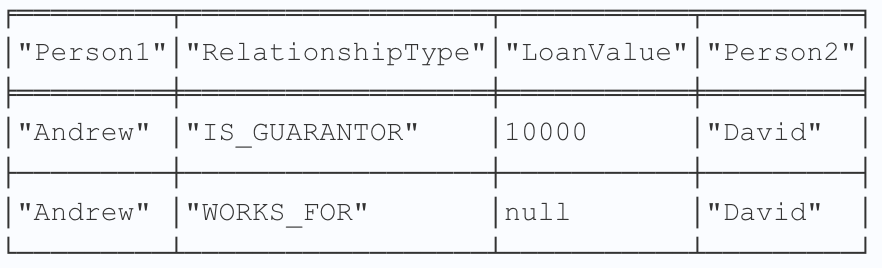
You are also able to specify multiple relationships such as IS_GUARANTOR and WORKS_FOR:
match (p:Person)-[r:IS_GUARANTOR|WORKS_FOR]-(p2:Person) where p.name='Andrew' and p2.name='David' return p.name as Person1, type(r) as RelationshipType, r.loanValue as LoanValue, p2.name as Person2
Conclusion
In this article, I’ve demonstrated how Neo4j implicitly brings context to the relationships in your data, whereas using other platforms brings considerable toil in modeling, data preparation, and querying.
Neo4j has so much more to offer, and we have many blogs out there detailing our products and use cases. I hope you enjoyed this one.
Share Article



Explore
Related Articles



Text2Cypher Across Languages: Evaluating Foundational Models Beyond English


