Knowledge graphs: The path to enterprise AI


34 min read

Editor’s Note: This presentation was given by Michael Moore and Omar Azhar at GraphConnect New York in October 2017.
Presentation summary
Once your data is connected in a graph, it’s easy to leverage it as a knowledge graph. To create a knowledge graph, you take a data graph and begin to apply machine learning to that data, and then write those results back to the graph. You can use natural language processing (NLP) to capture topics and sentiment from unstructured text and add it into the graph.
Knowledge graphs can be used anywhere information needs to flow, and data needs to be linked, whether it’s building customer 360 views, doing anomaly detection, cyber security, or working with a massive network of advanced statistical models for proactive risk management.
This presentation includes a range of how-to information for building an enterprise knowledge graph, including how to recognize graph problems.
Full presentation: Knowledge graphs: The path to enterprise AI
This blog shows you how to leverage knowledge graphs, which are data graphs combined with iterative machine learning, to solve many enterprise challenges:
Graph technology is transformative
Michael Moore: I’ve been working in graph technology for four years. I think it is the most exciting, transformative technology that’s come around since the advent of
SQL. I firmly believe that within 10 years, probably 50% of the SQL workloads will be all running on graphs.
Ernst & Young is a services organization. We work closely with emerging technologies. We have the ability to help organizations around the world be successful with those technologies and solve real business problems. And we offer a number of different services, just like any other consulting firm.
But I think what we like to differentiate ourselves on is that we work on really hard problems. We tend to have small teams working on hard problems and trying to drive high-value outcomes.

Our data and analytics practice globally is deployed in over 150 countries. We have well over 6,000 analysts and developers working across a whole number of capabilities from strategy to analytics to transformation, implementations, and also running business operations as managed services.
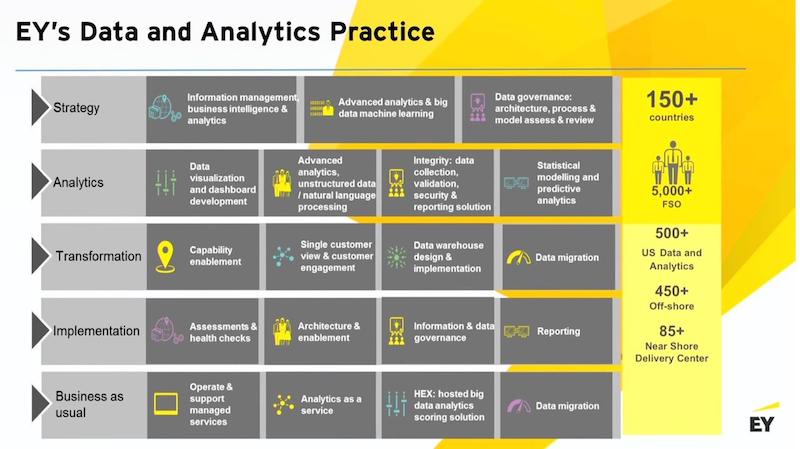
We do things all the way from designing data warehouses to moving data to building BI and visualizations to things like robotic process automation, where we apply machine learning to documents to make sure that they’re being processed more accurately and efficiently.
Here are some of the tools that we’re using.
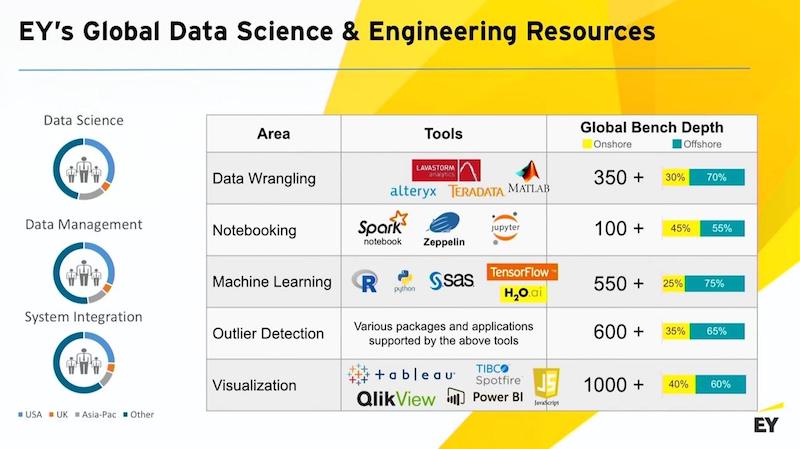
We do a lot of work with large systems. I’ll show you in just a second some of our alliance partners. But we’re fully stood up around using all the best practices, around notebooking. We do a lot of work. We have many R developers and Python developers. Omar’s group makes extensive use of TensorFlow. I make a lot of use of H2O.ai. And then, of course, a lot of capability around all the common BI tools.
Our whole goal around our data knowledge practice is to quickly find value out of data and then push that higher up into the organization. Our mix of onshore versus offshore, we tend to be about 30% onshore or nearshore, and then we also have some global delivery centers that we use for some of our managed services or more straightforward migrations.
We have a number of global alliance partners. We have a global alliance with Adobe and a number of consultants that are very well-versed in the entire Adobe stack. We also have a big practice around SAP. We’re a global alliance partner with Microsoft, and we are involved in some co-development work with them.
We have a number of other alliances including an alliance with IBM, for example, which opens up some interesting possibilities about large server on-prem deployments of graphs.

What is a graph?
When we talk to business leaders, we always start with the basics: What is a graph? A graph is a visual representation of how data is connected and how things are connected.
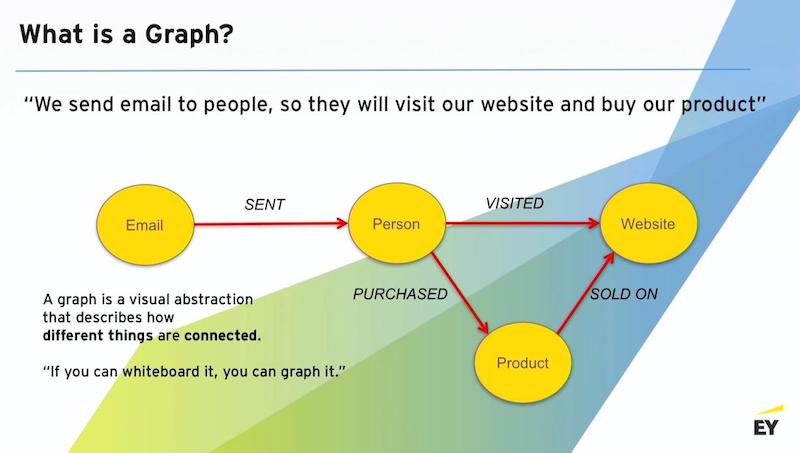
Graphs are very useful for describing processes. You know this because anytime you give somebody a dry erase marker and ask them, “Tell me how your business works, or how the system works,” within minutes somebody is drawing bubbles with arrows to more bubbles, and boxes and so forth. They begin to use a graph as a construct to explain how a complex process works.
With graphs, there is an interesting dichotomy between nodes and relationships. Sometimes nodes are called vertices. Sometimes relationships are called edges.
From a design perspective, you can leverage this in a couple of different ways. I take my graph representation, and put it in a graph database like Neo4j, and the schema of that database can be an almost exact replica of what was originally described.
One of the most important features driving graph adoption in businesses is that graphs have a very high degree of semantic fidelity.
As a data developer, you are able to have a very informed discussion with your business counterparts. You can say, “Here’s how I understand your business works. Here’s the schema I’ve built. May I show it to you?”
In the SQL world, that would be horrifying. But in the graph world, it’s actually kind of fun. And you can sit right down with the business leads and say, “This is how I understand it.” And the business leader can say, “No, no. It doesn’t work that way. There’s an arrow missing.” And you say, “Great, we’ll create another relationship.”
There’s a very nice agile flow around graph development.
The example graph below is a simple ecommerce scenario where we’re trying to drive somebody to a website. In that scenario, I’m sending email to people. I’m trying to get that person to visit the website. And when they get to the website, I want them to buy a product that’s sold on that website.
That’s what this little graph shows. In this schema, we’ve implemented a graph database that does exactly that. And in the graph database, I have my nodes for my emails.
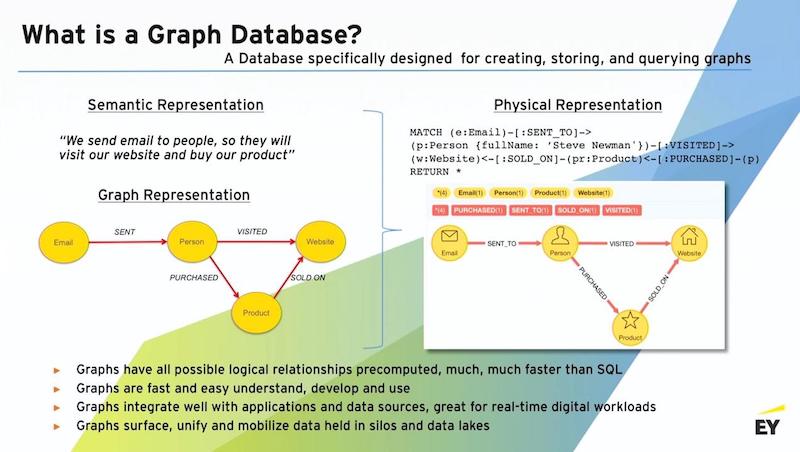
Think of many individual emails. Each will be labeled as an email, but the contents of that node might be the specifics of what that message was.
I have numerous customers, so this is my person node. And I would have a many person nodes, and every one of those nodes would carry the details for that individual. I would also have a website node, and that node would have pages associated with it and carry all the details of the pages. I’d have my product nodes, and I’d have all my product records.
Whenever we do one of these steps, I have the opportunity to set a relationship. We sent an email to this person, so I can set that relationship. Now I have a concrete connection between a group of emails that were sent to a discrete individual.
Did that individual take action? Did we see them on the website? If so, I can set another relationship. Did they buy something? And what was it that they bought?
Then I can actually connect the product node, so I know what my inventory on the website is because I can see that it sold on the website.
If you were to write an SQL query, and you wanted to actually find out how many individuals went through this pattern, you’d have to touch at least four different tables. You’d have to do a lot of recursive querying to figure out how many paths existed across those relationships.
In a graph world, instead of figuring out what tables you’re trying to put together and what keys you want to use to join those tables, you declare a traversal path. This may sound simplistic to those of you who have already used graphs, but it’s important to remember that the biggest shift around thinking about graphs is to begin to imagine how you traverse the graph.
In the picture above, we see some example code. And in that code block, you see how simple it is to query this graph and come back with this pattern. We’re basically saying we’re going to send “this email” to “this person.”
Because Neo4j is a property graph, we’re going to filter for the emails that were sent to a guy named Steve Newman. And we’re also going to apply a constraint that Steve visited the website.
Then we’re going to apply another constraint that he bought a product that’s been sold on that website. And now, given this complex cyclic query, which is a correlated sub-query represented in a single line of code, it will then return all the records that satisfy that traversal pattern.
Graphs are very good for doing these kind of complex traversals across large landscapes of data.
One of the interesting things about graphs is that all of the logical possible relationships that would exist between two data entities would’ve been precomputed and stored in the storage structure. This makes them very fast at query time. Graphs are a little slower to write to, but they’re very fast to query – much faster than SQL.
The other thing that’s very important about graphs is that you can query through traversals many different entities and still get a very linear consistent response. You’ll never have the graph database just simply fall over, throw up its hands and say, “I’m out of memory,” which happens all the time in SQL.
Anybody who’s a SQL practitioner does a lot of work with query optimizer, and hinting and ordering of the tables so that you don’t run out of memory. That’s not a concern in a graph.
Graph use cases
The below graphic nice view of some of the use cases around graphs.

The most common use case requests we get from customers are Customer 360, real-time recommendation engine, marketing attribution, enterprise search and a host of others. We’ll touch on some of those in a second.
Why we are excited about graphs
We are excited about graphs for several reasons:
Fast. Graphs are super fast on query time, which means that you use a graph to run a really high-performance digital experience directly off your graph, with millisecond response times for deep traversals across many entities.
Easy. They are schema-less for rapid, iterative development. They’re iterative and they’re forgiving. You can load your nodes, set a bunch of relationships, and scratch your head, and say, “You know what? I don’t like the way those relationships look.” So you just blow away the relationships and redo them.
Impactful.There are several ways of thinking about graphs. Neo4j is an OLTP optimized in-memory graph. It’s wonderful for real-time applications. You can use graphs for doing machine learning. And you can do that, actually, inside the graph. You can do it using other OLAP graph structures. All of that is a really great ecosystem for driving impactful use of your data.
Transformative. Graphs provide an extensible platform for actionable, end-to-end customer, process and business analytics. We see people start off with proof of concepts in a single data domain, but they very quickly realize the power of this construct and want to add additional domains. Doing so really becomes a matter of rolling in and designing additional new edges and nodes for the graph and bringing them together. It’s well within the realm of possibility.
Strategic. Graphs surface, unify and mobilize data from data lakes and bringing it out to frontline experiences. Data work is great, but unless you can mobilize that data and bring it out to the customer experience, you haven’t been as successful as you could be.
Graphs and data lakes
Let’s talk a little bit about data lakes.
Data lakes are so beautiful and clean; it’s a great vision, having all your data in one place. But then you start to very quickly hear what’s probably the most common corporate lie in the data world, which is, “We’ll have the data lake done by next year.” I hear this every year. The fact is, a data lake is never going to be done.
As the business evolves and grows, more and more data sources come in. There’s lots of unstructured data now being held in data lakes. You have whole topic areas where no one’s even gotten around to thinking about it. They take a snapshot of an Oracle database or a Teradata EDW, and then dump it into the data lake and say, “We have an S3 bucket that has all of the data from our Oracle system.” If you ask them if they’ve looked at it, they say, “No, we can’t get around to it this year.”
And then, of course, there’s often a lot of attention on specific data domains. They tend to be highly conformed and curated, and that’s great place to start working.
And then, of course, there’s streams. You have streaming technologies that are being stood up all the time around core processes. The publish/subscribe model is a great architectural model.

Graphs mobilize data
Graphs are a terrific accelerator for mobilizing data. Here is a functional architecture.
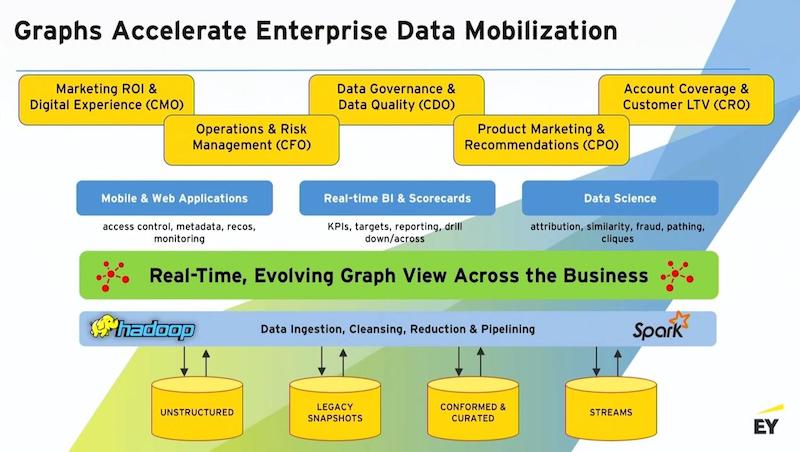
What we’re really talking about is putting a graph layer over your data warehouse or your data lake. That puts you very quickly into the world of real-time queries. You’re out of batch mode. It puts you into the world of being able to iteratively, and in an agile fashion, evolve your data presentation with how the business is changing.
Typical consumers of graphs are mobile and web applications, real-time BI and scorecards – your data science teams.
Another truism is that CIOs don’t necessarily care about the data itself; they’re more concerned about the containers.
The people who really care about the data – the quality of the data, what the data means and the implications of the analytics – are all of the end users across the business. This includes your marketing departments, your ops departments, the folks that are involved in privacy and data governance, product recommendations and development, and your sales teams.
These are the people who need to see accurate data, and they need to be able to leverage all of the other things that graphs can do in terms of providing wider scope for their queries, machine learning and so on.
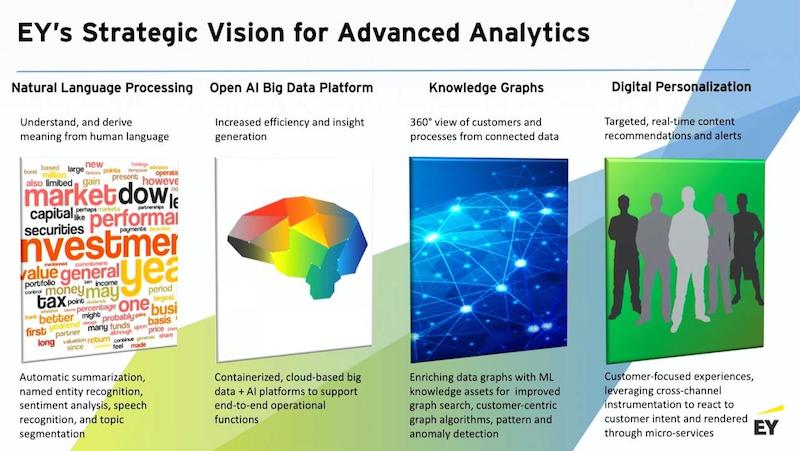
Vision for advanced analytics
Our vision for advanced analytics rests on four pillars:
Natural language processing (NLP). We’ve done a lot of work in this area and we believe that it’s a really important area of focus because it’s where you understand intent. It’s where you understand sentiment. It’s where you understand the nuances of how humans are interacting with each other, which you can’t typically get out of structured data. The usefulness of machine learning is dramatically improved when you can expose it to some NLP-sourced information.
Open platforms. We’ve done a lot of work around open platforms. We’ve built fully containerized platforms in Azure that have the entire Apache stack from top to bottom. We use those kinds of environments to do large models, and we also use them as test beds for customers to come and try out new ideas without getting into a lot of technology risk.
Knowledge graphs. We’re big fans of knowledge graphs. We believe that, ultimately, this provides the best path for a full 360 view of your customers, whether you’re involved in B2B or B2C, if your customers are external or they’re internal customers. And furthermore, what really constitutes a knowledge graph is when you take a data graph, which might be just a graph-based representation of your SQL environment, and then you begin to apply machine learning to that data, and then you write those results back to that graph.
Digital personalization. You have to get the data out of the data environment and out to the front edge. And so, we’ve placed a lot of bets around technologies like Node.js, microservices and streaming because we want to be able to set up very low-weight microservices so that we can actually produce things like a very intelligent recommendation in a widget that might be rendered in a relatively unintelligent web experience. So rather than doing a broad IT transformation, we’re looking for narrow pipelines, where we can push smart analytics right out to the front edge.
Natural language processing (NLP) for better insights
Omar Azhar: Within advanced analytics, we help our clients create, build and implement practical AI and big-data strategies. And that revolves around three key pillars.
The first is understanding the customer to drive the growth agenda and customer experience, taking out a process end to end and applying the right robotic processing automation (RPA) and machine learning frameworks for intelligent process automation, and then get better signals.
With machine learning, AI, big data – all the big buzzwords – every executive wants to know, “How do I use this? How do I leverage this to get an edge and create process efficiencies or gain better insights?” A key driver is natural language processing.
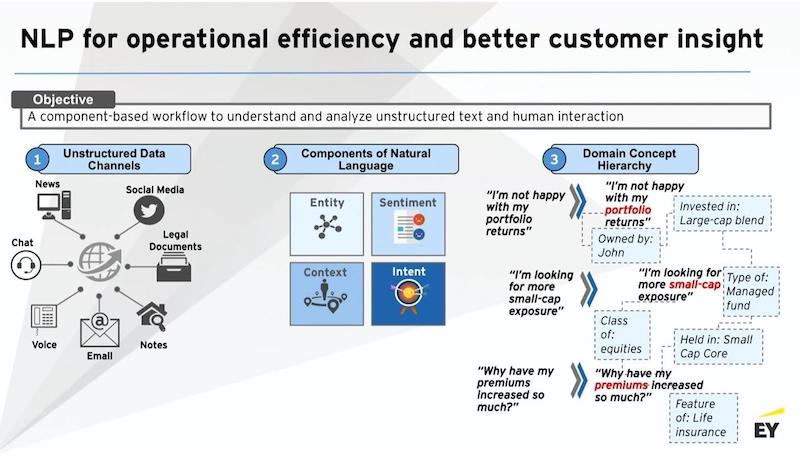
Every day, a whole slew of unstructured text is created from all of the various communication channels that exist, especially in financial services.
You could have a call center. If you’re getting thousands of calls from clients every single day, you want to know what products they are talking about, the topic of conversation and their sentiment. Is my agent handling that call properly or do I need to give them additional training?
In wealth management, you want to know how your financial advisors are talking to their clients. How are their clients related to one another?
In sales and trading, you could be getting thousands of emails a day from institutional clients. These could be anything from collateral margin obligations, or price verifications, or just a sales guy yelling at you.
Natural language processing has immense use cases within just the financial services industry, from back-office to front-office, no matter where you are. Using natural language processing, we can extract a lot of the features from the conversation.
What are people talking about in terms of context or topic, the entities being mentioned? Is it an Apple stock, McDonald’s, the USA or Russia, the sentiment and the intent?
And when you pair up these features that you’re extracting with your domain ontologies and your domain hierarchies, you actually get very good practical use cases. Companies are now starting to build very targeted NLP pipelines across their businesses. Those are great tactical use cases for NLP.
Building a communication graph
How do you actually create those features that you’re extracting and the use cases you have and make that into a strategic asset?
Once you’ve got your NLP pipeline, start pushing those communications into the graph. Now you’re actually building that communication channel as an asset. You’re now building a network of communications that all your clients are having. You’re able to now relate your clients just based on the topics that they’re conversing on because the graph makes that linkage natural.

As you keep expanding on this, and add more and more domains, you start getting into very intrinsic natural language about your own enterprise – all the different communications that you’re having within your business. You’re starting to build a conversation intelligence platform.
And now all those NLP pipelines that you had – that are recording, going through your call centers, going through your emails, going through financial analyst (FA) to client conversations – you’re actually starting to build that up as a strategic asset that you can use going forward to better understand what’s happening in your business and what your clients and your customers are talking about.
You’re starting to build a communication graph. And you’re trying to understand how your customers are related to one another, just based on what they talk about. But then you can start adding in additional things.
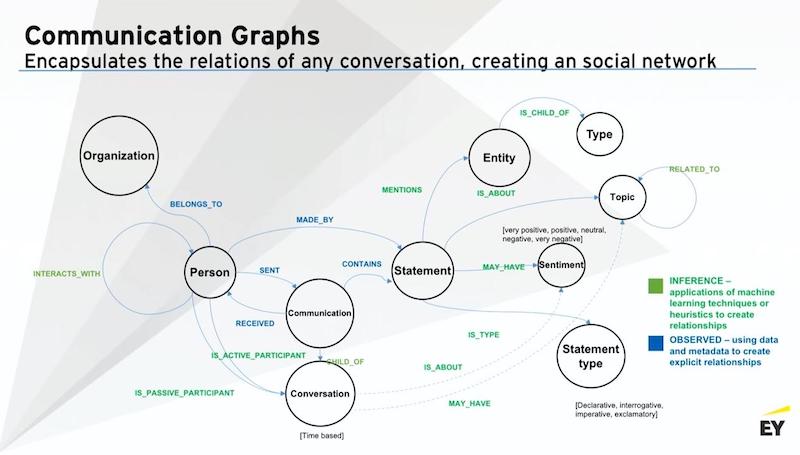
In this particular example, if you’re a wealth management business, you’ve already started building your communication network.
You know how your FAs are talking to their clients. You know exactly what the points of conversations have been, what products they’re talking about, what are the different trends. But then you start bringing in additional data sets, transaction data, account-level data, and FA data. Bring in the different career aspects that you know about your clients. Start building this Customer 360 view.
Building a customer 360 view

With the knowledge graph, a Customer 360 view is very natural and innate. Everything you want to know about that one customer is right there on that node, a few traversals away. And then from that, you’re connecting how that customer’s related to the other customer as well – if they own the same stock, they’re automatically related – just for a few traversals in the graph.
Building a Trader 360 view
But this 360 view that a graph provides is more than just for Customer 360 and is trying to build a better understanding of your customer-building next best action frameworks and recommendation engines. You can also use it for the other two pillars we’re talking about.
A big one would be conduct surveillance of collusion or conduct in sales and trading. Even in sales, you want to know if sales reps are pushing something they shouldn’t be pushing or talking in ways that they shouldn’t be talking to clients. How do you detect anomalous behavior among your traders?
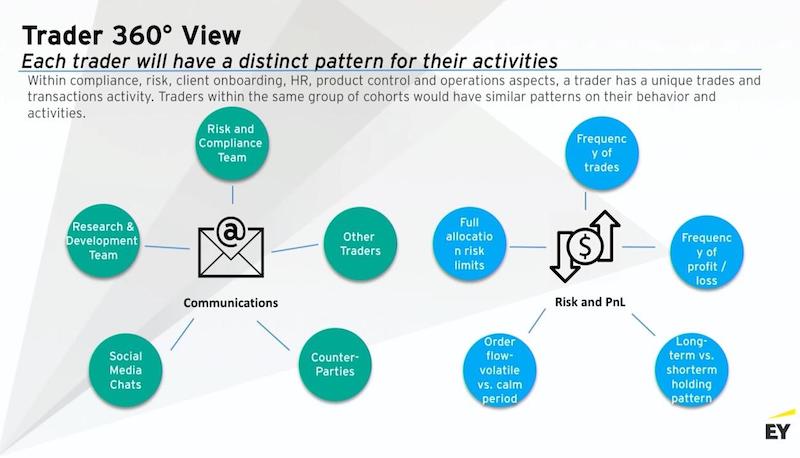
If you start using this 360 view of the knowledge graph in your sales and trading as well, you start putting all the different communication channels they have. Who your traders are talking to? What were they talking about? What are the different actions that they’ve taken?
You’re now starting to build a sub-graph of each trader. And using anomaly detection, you can see, “I have a group of equity blue-chip stock traders. I would expect their sub-graph to be relatively the same.”
You can start doing some anomaly-based graph detection to start detecting maybe collusion behavior, insider trading, or any sort of abnormal conduct that you should maybe look into. And that 360 view the graph provides makes that very natural for you to look at in terms of your data.
Proactive risk management
Let’s go back to the wealth management example.
You’ve started adding in all these different datasets. You’re adding in all these different domains. You’re building an enterprise knowledge graph, which includes all your Customer 360 views, the various products you have, all the customers and conversations. And then, how do you make it smarter now? It’s already pretty intelligent. It knows everything it knows about your business. All the information you want to know is at your fingertips. You can build search engines.
You can make it even smarter and more proactive by bringing in external data like external news data sources. You can start appending that to your own internal graph. In this example, your own internal business knowledge graph might end up at Apple as the furthest in terms of your product domain.
You know every single customer that owns an Apple stock and all the FAs that are related to them. But that’s only your internal business data. Once you start bringing in external data sources, you can start knowing, “Okay, what are the external events happening around Apple? And then, how does that impact my customers’ portfolios?” “Is there some sort of action I need to take?”
Knowledge graphs make that traversal information very easy and completely natural.
If we start appending external news that’s happening and start putting them into the relevant products that I own within my business, I can start using natural language processing or other machine learning frameworks to detect significant events.
If a significant event happens in one location on my graph, I can add in business rules and domain logic to automatically tell the graph, “Hey, here’s a specific type of event. I want this information to be passed over to this particular node and this particular domain of my knowledge graph.”
In the example below, an event happens on Apple stock. You can make your knowledge graph intelligent and actually take actions on its own by putting in the business rule, “Significant event on this stock. I want you to send information to all the FAs who have clients that have positions in this stock.” And that FA gets a notification and that says, “Here’s an event. Maybe you want to look into it. Here’s a news article.”

You’re starting to make this graph intelligent and your business proactive.
You can start off with simple rules. This information needs to be sent here whenever something like this happens. You don’t even need to go into complex machine learning, AI, or deep-learning frameworks because every piece of your business is now connected in the way it should be. All you need to do is say, “Hey, this information seems like it needs to go here.”
Building a risk driver graph
You can do more than just information retrieval for, say, customer and actions. You can also build a knowledge graph as a massive calculation engine.
In banking, we have what we call a comprehensive capital analysis and review (CCAR),where every single bank has to build this massive number of models to stress-test across a variety of scenarios that the Fed gives them. This is generally a months-long process.
Banks can take anywhere from 8 to 12 months to complete these stress tests, going all the way from identifying their risks, building the scenarios that they think are going to actually stress their institution, build the models that accurately capture their business, and then also, then, aggregating those model results into different line items that they have then sent to the Fed, or the SEC, or to the shareholders, in terms of their revenues, their balance sheets, and whatnot. That’s just an information flow.
A graph can actually capture all that as well. If you start graphing all your risk inventory that you identify, then connect it to the identified macro variables or market variables that you said drive those risks, then those variables are also the drivers in your models and non-models. And then those models also didn’t have—the results of those models also aggregate up to financial statements.
That’s an information flow that you can start putting in as a network of models using a graph database. And now, you’ve built yourself an enterprise calculation engine.
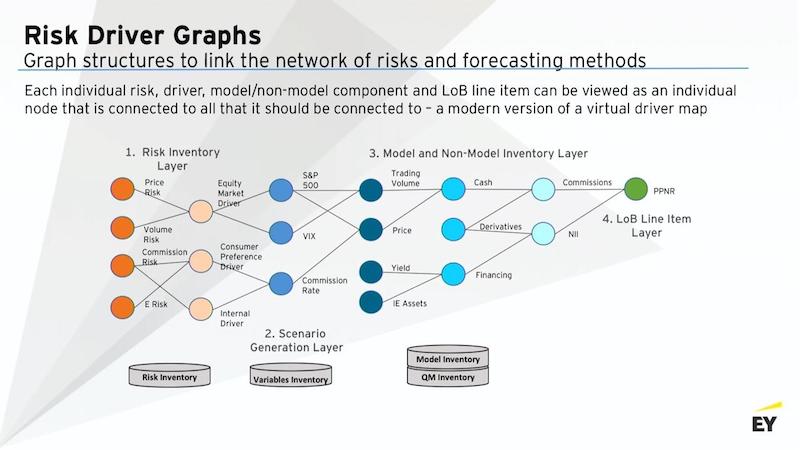
If you’re a CEO, if you put all your models and non-models in and you link it up into a knowledge graph, you can say, “Hey, let’s see if VIX goes up five bits tomorrow morning. In an adverse scenario, what’s the impact to my balance sheet?”
Right now, if you ask someone that, it’s about a three-to-four-month process. But if you put all of your models and use the graph as a natural information flow, and it’s a calculation engine where one model’s input goes into the other, as it should, and then they all get aggregated.
It’s a relatively quick calculation. You just put that into whatever app you built for it. And if you change one node, all the downstream nodes will be impacted. And I could then just look at the pre-provision net revenue or PPR and see the net revenue line item and say, ” This is the impact from that change in nodes.”
Knowledge graphs can also be used anywhere where information needs to flow, and data needs to be linked, whether it’s building customer 360 views, whether it’s doing anomaly detection, cybersecurity, or even linking in a massive network of models.
For some of these banks, there are like 800 to 1,000 different models that can range from anywhere from regression, to ratio-based, to complex Monte Carlo and stochastic calculus models.
Knowledge graphs for smart searches
Once you’ve built your entire business in a knowledge graph – you’ve built this layer that sits on top of your data systems – you can start building very intelligent enterprise search engines.
One of our large private wealth-management clients came to us recently and asked, “I’m just a business guy. I’ve got my data spread across multiple different data systems. I get my weekly reports from the tech teams, and I give that to my clients. But every now and then, I want to just retrieve information and make ad hoc reports, but I can’t do it because A, I have to go talk to the tech team, give them the variables that I want, and then they pull it for me. It’s cumbersome. I just want my data when I want it, how I want it.”
And we said, this seems like a classic knowledge graph plus natural language processing problem. You’ve got your structured data across a dozen or so systems. If we just put a graph database on top of that, using natural language processing, we can give you a search bar. You just type in what you want.”
Here’s screenshots of the proof of concept that we built for them. They just type in what they want and it’ll give them an Excel file that they can then go and put into Tableau or Spotfire and create their ad hoc reports when they want.
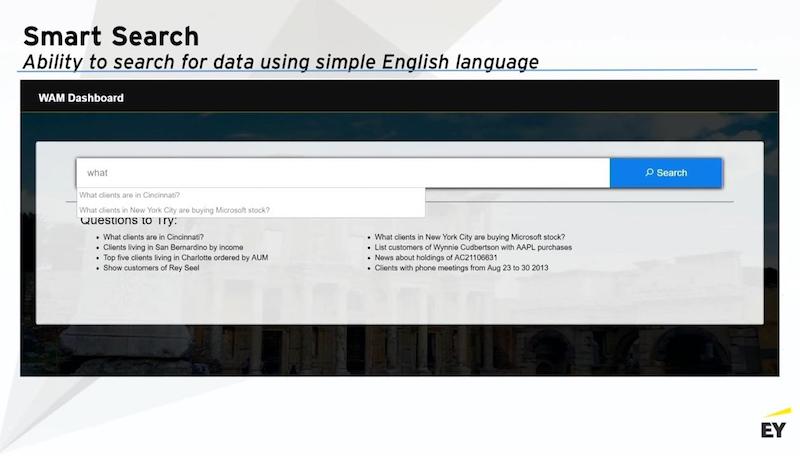
Using natural language, it interprets the intent, the named entities that you’re talking about and the time stamps, converts it into a Cypher query, and pulls the relevant information from a graph.
That’s just the beginning of how you would go about building an enterprise search.
How to start building an enterprise graph
Moore: How you can get started building an enterprise graph?
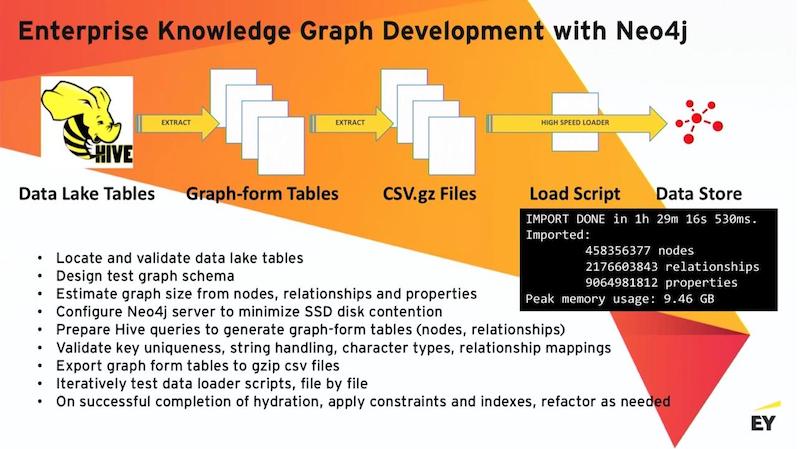
After we’ve done some locating of where the data is, the basic process is building a bunch of queries. Those queries result in what I call graph-form tables. So these would be deep tables of either nodes or relationship maps between nodes.
Next we do a simple SELECT * query from each one of those tables. We then create a compressed CSV file and load that into Neo4j. The Neo4j loader is a fast-loading tool that can directly consume zipped CSV files – it is highly efficient. And it is used for, essentially, your initial graph hydration.
The hardest part: everything before building the graph
The hardest part about building a new graph is everything that happens before the graph.
So when you’re starting to deal with really high volumes of data, and you’re trying to map relationships, you have to observe all of your key constraints. You have to make sure that all your string handling is done properly.
What we find is that we have to iterate a lot on the core tables that are going to form the graph. We’ll spend weeks working on those first two major steps, but then when it all comes together.
The below graphic depicts a real output from a graph that I built about a year ago on Azure. All of it is being validated as it’s being loaded. And being a database, Neo4j, properly, will complain very loudly if it can’t find a key to create a relationship between nodes or if you violate a uniqueness constraint.
Choosing your data
As you’re talking with teams around your company, pick some data that’s already been worked on a little bit. That way, you’re basically in the business of creating node and relationship tables. This a good accelerant for your projects. Typically, that data will already be clean.
Another common scenario that we see is clients with legacy databases. This is a little bit slower; you’ll have to do a individual extraction from every one of these databases. The slowest part of it is just negotiating access to that specific system.
Streams are very easy to bring into a graph. We typically start thinking about streams after we have done our initial graph hydrations and we’re talking about updates.
There’s a variety of ways to update graphs. You can use Incremental, CSV loads. You can have applications updating graphs through the various drivers that Neo4j supports. But streams are a great way to go and very scalable.
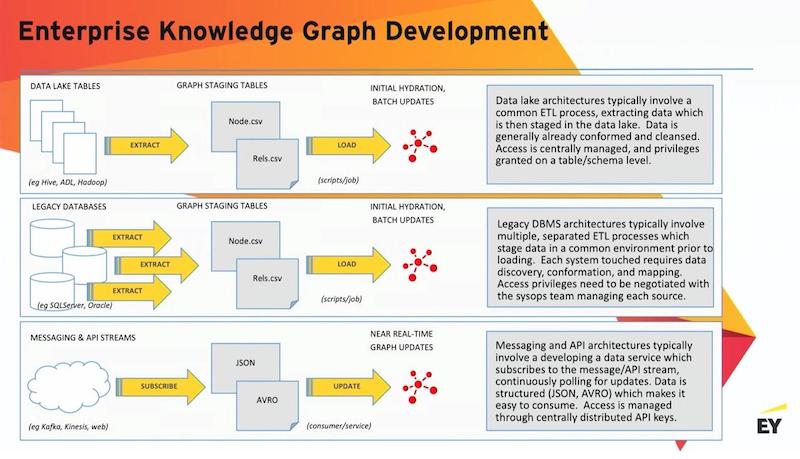
From data graph to knowledge graph
Now, let’s talk about how you go from a data graph to a knowledge graph. There are several patterns.
Pattern 1: GPU accelerated
The first pattern, which is probably the most common, is extracting data out of Neo4j. It will typically need to be extracted in some kind of tabular format that will have all the features that are necessary to do the model build. We’ll push that into some modeling environment like R, H2O, or TensorFlow, and then we’ll take the scored results and write that back to the graph. It’s a little clunky. It works. It’s very powerful and leverages the best abilities of each platform.
Pattern 2: Distributed OLAP graph processing
Another pattern that’s starting to emerge is the pattern of using a distributed OLAP graph processing. I believe that this pattern will become increasingly prevalent. Here you’re talking about doing extracts from Neo4j, pushing those into graph frames inside Spark, running a Scala-based modeling procedure, and then updating from that output back up into Neo4j.
Pattern 3: In-graph, in-memory machine learning
My favorite pattern is in-graph, in-memory machine learning. There’s been some really nice work that was recently done by Michael Hunger and team around a whole set of extensions and procedures. They’re basically a plug-in that you can put into your Neo4j server. This exposes for you a number of highly parallelized graph machine learning algorithms. This is a really powerful model because now, instead of moving the data around to go where the modeling is, we’re actually bringing the modeling into the graph. This can be very fast as well.
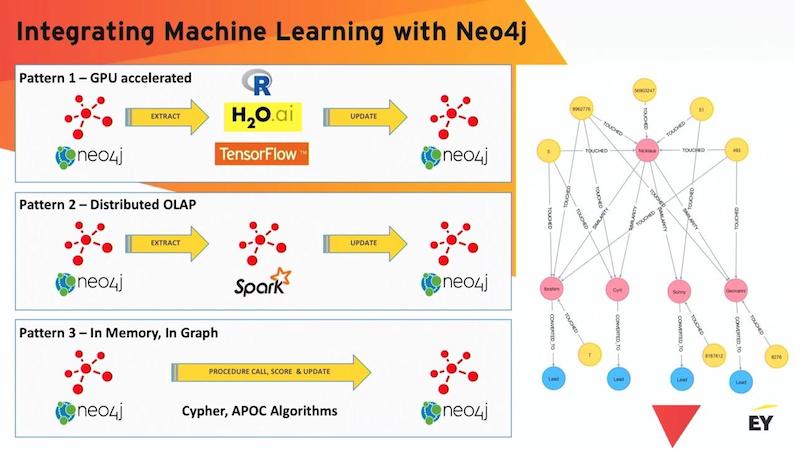
What transforms your data
Where do we go from there?
Once we have the model scores, what transforms your data graph into a knowledge graph is how you choose to write your predictions back to the graph.
On the graphic below, to the right is a marketing attribution graph. All those yellow dots are different marketing messages that have all converged on a single individual. The question on the table is, “What marketing message should this individual be exposed to next so that they will convert to a lead?” This graph includes a similarity relationship we can use.

There are basically four ways you can think about how you want to make your graph smarter. You can take your predictions and you can just simply add them as properties to existing nodes. This is commonly done.
Another interesting thing that you can do – which is good for things like clustering algorithms – is to apply additional labels to nodes in your graph. You can have as many different labels as you want in a Neo4j graph. All a label does is just declare a set of nodes, and those labels could be fully overlapping. One of the things that you get by applying a label is a free index and you may immediately subsegment your graph by labels.
Of course, you can take complex model results and just push them in as nodes and connect them into the graph but I think one of the most powerful models around for pushing scores into graphs is to leverage the relationship.
One of the interesting things about Neo4j is that it is a property graph and you can put properties on relationships. Because you can put properties on relationships, I can have two data points and I can have multiple model runs.
With each model run, I can set a new model relationship, a new predicts relationship, that references which model made that prediction and add a probability score, or a confidence score, or a similarity score. And that’s essentially what we’re doing here with these similarity relationships.
We compute similarities across every single customer to every other customer in this graph. That’s a very accessible kind of calculation in Neo4j. And then you write it out as a relationship. You can keep track of multiple versions of your models. Because of directionality, you could have different predictions for the same two nodes.
As shown above, I’ve got some blue arrows where A is predicting B, but I could just as easily have B predicting A. And then this becomes a very compact language for representing knowledge in a graph.
And the most important aspect of all of this is that, now that they are instantiated as relationships, I can actually traverse using Cypher and pick out all the predicted nodes. You could have multiple linked predictions. You got multiple linked predictions extracting highly related data that you’re essentially imputing using this combination of the graph and machine learning. It’s a very powerful construct.
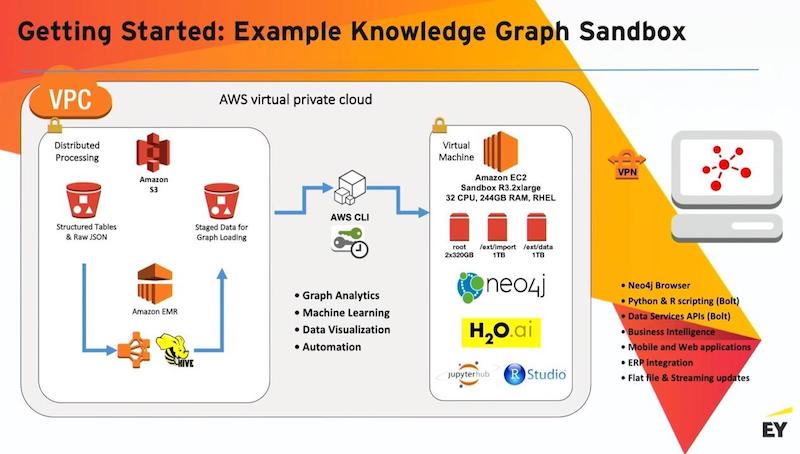
For getting started, the below graphic is a typical sandbox implemented in AWS. Azure has very similar services.
Typically, what we’ll end up doing is we’ll do stuff in Hive. We’ll create a bunch of those graph-form tables in S3. And then we’ll import those into an EC2 server that’s running stand-alone in the virtual private cloud. We add in a bunch of tooling so that the data science teams work directly with the graph using the packages of their choice.
How to recognize graph problems
How do you know you need to use a graph?
Rather than thinking about this as a technical problem, it’s much better to think about it as a business problem. If you are starting to hear questions like, “I have a large volume of incoming customer communication. How can I better understand what my customers are saying?” that’s a graph problem.
“How can I get a better understanding of my customers to give them a better experience? How can I improve the way that I directly interact with my customers?” (Another good graph problem.)
“How can I be more proactive? How can I separate signal from noise?” (Again, a great graph problem.)
“My data is spread across many, many sources. How can I easily get access to it and come up with a better view without having to go through so much difficulty?” (Excellent workload for graphs.)
Then finally, and I think this is probably the most important question, “What’s the next best action I can take?”
In my opinion, a knowledge graph, a data graph that’s combined with iterative machine learning, is probably going to be the best pattern going forward for answering that specific question.
Share Article



Explore
Related Articles
Introducing MCP for Aura: Hosted MCP, built into every Aura instance


Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

