Neo4j 3.4 release highlights in less than 8 minutes [Video]

Director of Developer Relations @ Neo4j
5 min read

Hi everyone,
My name is Ryan Boyd, and I’m on the Developer Relations team here at Neo4j. I want to talk with you today about our latest release Neo4j 3.4.
Overview
In Neo4j 3.4 we’ve made improvements across the entire graph database system, from scalability and performance, to operations, administration and security. We’ve also added several new key features to the Cypher query language, including spatial querying support and date/time types.
Scalability
Let’s talk about the scalability features in Neo4j 3.4.
In this release, we’ve added Multi-Clustering support. This allows your global Internet apps to horizontally partition their graphs by domain, such as country, product, customer or data center.
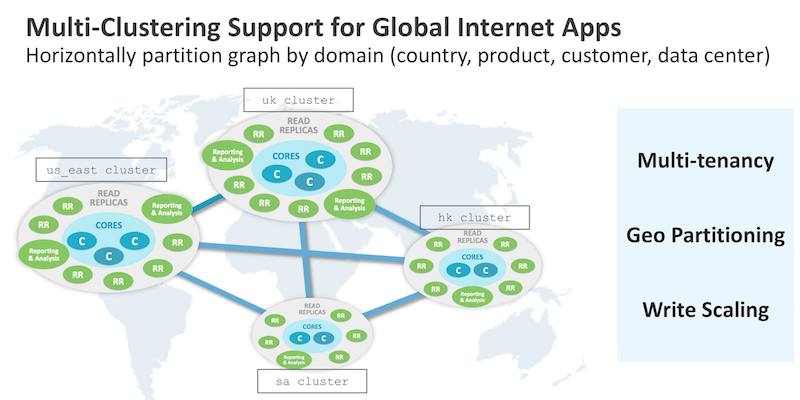
Now, why might you want to do this? You might want to use this new feature if you have a multi-tenant application that wants to store each customer’s data separately. You might also want to use this because you want to geopartition your data for certain regulatory requirements or if you want enhanced write scaling.
Look at the four clusters shown in the image above. Each of these clusters has a different graph, but they are managed together. They can also be used by a single application with Bolt routing the right data to the right cluster, and the data is kept completely separate.
Read performance
As with all releases, in Neo4j 3.4 we made a number of improvements to read performance.
If you look at a read benchmark in a mixed workload environment, you can see that from Neo4j 3.2 to 3.3 we improved performance by 10%.
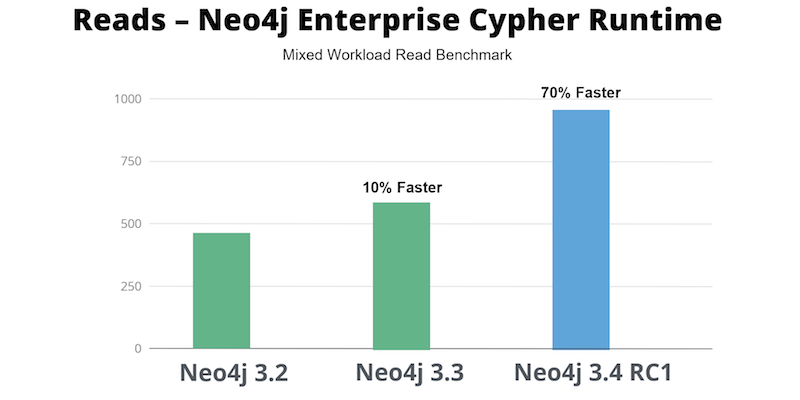
Now, for this release, we spent the last several release cycles working on an entirely new runtime for Neo4j Enterprise Edition. I’m proud to say that in Neo4j 3.4 we’ve made all queries use this new Cypher runtime, and that improves performance by roughly 70% on average.
Write performance
Write performance is also important.
In our ongoing quest to take writes to the next level, we’ve been hammering away at one component that incurs roughly 80% of all overhead when writing to a graph. Now, what component it is may not so obvious – it’s indexes.
Lucene is fantastic at certain things. It’s awesome at full text for instance. But it turns out to be not so good for ACID writes with individually indexed fields. So we’ve moved from using Lucene as our index provider to using our native Neo4j index.
We’ve actually moved to a native index for our label groupings in 3.2, for numerics in 3.3, and now, with the string support in 3.4 we’ve added a lot of the common property types to the new native index. This is what results in our significantly faster performance on writes.
Our native index is optimized for graphs. Its ACID-compliance allows you fast reads, and as you can see, approximately 10 times faster writes. The image below shows you the write performance for the first 3.4 release candidate when writing strings.

At the point at which we implemented the new native string index, we have approximately a 500% improvement in the overall write performance.
Ops and admin
We’ve also made a number of improvements around operations and administration of Neo4j in the 3.4 release. Perhaps the most important is rolling upgrades.
Neo4j powers many mission-critical applications, and something many customers have told us is that they want the ability to upgrade their cluster without any planned downtime. This feature enables just that. So if you’re moving from Neo4j 3.4 to the next release, you could do it by upgrading each member in the cluster separately in a rolling fashion.
Neo4j 3.4 also adds auto cache reheating. So let’s say that you normally heat up your cache when your Neo4j server starts. When you restart your server the next time, we’ll automatically handle the reheating of your cache for you.
The performance of backups is also important to many of our customers and they are now two times faster.
Spatial & date/time data
With Neo4j 3.4, we’ve now added the power of searching by spatial queries. Our geospatial graph queries allow you to search in a radius from a particular point and find all of the items that are located within that radius. This is indexed and highly performant.
In addition to supporting the standard X and Y dimensions, we’ve also added support so that you can run your queries in three dimensions. Now, how you might use this is totally up to you.
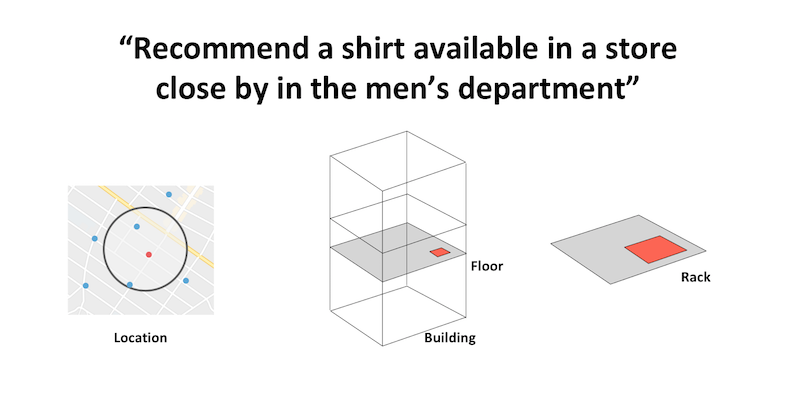
Think about a query like “Recommend a shirt available in a store close by in the men’s department”. You can take your location and find the different stores. And then, once you’re in a particular store you can use that third dimension support – the Z axis – to find the particular floor and rack where that shirt is available.
In addition to the spatial type, we’ve also added support for date and time operations.
Database security
We’ve also added a new security feature in this release that focuses on property-level security for keeping private data private.
Property-level security allows you to blacklist certain properties so that users with particular roles are unable to access those properties. In this case, users in Role X are unable to read property A. And users with Role Y are unable to read properties B and C.
Try it out with the Neo4j Sandbox
For the GA release of Neo4j 3.4, we’ve created a special Neo4j Sandbox. The 3.4 sandbox has a guide that guides you through the new date/time type and spatial querying support.
Watch the video for a quick demo of the new Neo4j Sandbox, or try it out yourself by clicking below.
Get started with the download-free Neo4j Sandbox and play with our pre-populated datasets or load your own.
Share Article



Explore
Related Articles

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


A workbench for teams to query, explore, and visualize graph data

1 of 3: The difference between a graph, a knowledge graph, and a context graph
