
How to Run Neo4j Across Cloud Platforms

Senior Director of Developer Relations, Neo4j
20 min read

Editor’s Note: This presentation was given by David Allen at GraphConnect New York in September 2018.
Presentation Summary
This post is about self-managed cloud delivery of Neo4j. If you’re interested in managed services, check out Neo4j AuraDB, Neo4j’s cloud database service.
Cloud computing is flourishing – and Neo4j’s support for public cloud platforms is growing with it.
In this post, Neo4j’s technology partner architect David Allen provides an overview of how Neo4j can be run quickly, easily and just about anywhere. Specifically, he discusses how to run Neo4j on three major cloud platforms – Amazon Web Services (AWS), Google Cloud and Microsoft Azure – and delves into the options and tradeoffs of each.
He also covers the various modes of running Neo4j to show how similar techniques apply regardless of the edition and configuration you’re using.
Moreover, Allen explores other topics, including Docker and Kubernetes, deployment considerations and network security.
Full Presentation: How to Run Neo4j Across Cloud Platforms
My name is David Allen and I’m a Partner Solution Architect with Neo4j.
A big part of my job is working with public cloud platforms like Google, Amazon and Azure. I work on making it simpler and easier to run Neo4j wherever you need, specifically with a focus on cloud support. In this post, a lot of what I’ve been doing over the last few years with Neo4j will become apparent.
Getting Started: A Focus on Cloud in 2018
In 2018, we put a fair bit of focus on cloud.
Why did we do that? Well, when we went out and talked to our customer base, about 50 percent told us they were already running on public clouds, so we sought to make it much simpler to launch Neo4j in the cloud.
We particularly noticed that of the customers already deploying on public clouds, the way they were typically doing this was by creating bare VMs, installing the software from scratch on those VMs as a Debian package or RPM, and doing the configuration themselves.
This works fine, but we saw the opportunity to make the process a lot easier and help people set up a known, good configuration that works out of the box and focus on customizing only the bits specific to their problem.
At the same time, we wanted to provide flexible options for power users. There are easy, simple ways to get started, but everybody has their own particular challenge to address. Therefore, real system operators and maintainers need options to do whatever is specifically necessary for their use case.
Neo4j on Public Clouds: Options
In this post, I’ll discuss three major clouds: Amazon Web Services (AWS), Google Cloud Platform (GCP) and Azure. Across the columns in the image below, there are a lot of different options. I’ll go through them in broad terms later in the post.

First, we have single instance. By that, I mean the kind of Neo4j you have when you run Neo4j desktop, in which you want a single, standalone machine, not a cluster. Single instance is adept at rapid prototyping and proof of concept. It’s not a high-availability setup that you’d put into production, but it’s usually enough.
The cluster world regards causal cluster, where you have this notion of core nodes and read replica nodes and need the ability to flexibly scale a cluster.
After that comes containers. In the cloud, some folks are running these as virtual machines, which we want to support. Other folks use the Docker container. We have some added support there as well.
Finally in the last column, we have Kubernetes. If you want to run a clustered setup in a containerized environment, that’s when you typically look at something like Kubernetes. We’ll discuss this later on in the post.
Azure – on the very bottom row – is something I’m actively working on. I still need to clear the Azure marketplace process, but this is expected by October, so I gave myself a green check there.
BYOL – Bring Your Own License
When you consume software from a cloud platform, there are different models.
At Neo4j, we’ve adopted a Bring Your Own License (BYOL) model. All of the offerings we’re discussing today are BYOL, which means you’re able to go into the marketplace on one of these cloud solutions and launch it.
On the enterprise level, we assume you have a license, since you need to have an existing enterprise license before you do this. You can contact your local Neo4j representative to get started on this.
Of course, anyone can use community for free anytime, but what’s not happening here is the process of obtaining the license through the cloud-computing provider and then paying us X-amount of dollars per hour for that license.
What Does It Cost?
Before we go too deep, I also want to detail how much this all costs.
The idea here is that when you launch something on a public cloud, you pay the cloud-computing provider for infrastructure – typically by-the-hour for virtual machine time. This is all separate from Neo4j.
As far as software licensing is concerned, if you have an existing relationship with Neo4j, it’s governed under the terms of that license and there’s no additional charge for using any of this.
If it’s community, all you pay for is the VM time on the cloud-computing provider. If it’s enterprise, it just depends on your license.
If you’re out there in the community and want to experiment with Neo4j, most clouds have a free-pricing tier, which is essentially a small instance you can use that requires zero commitment on any of these clouds, for no money.
Deployment Considerations
Let’s discuss a bit about deployment considerations, just to provide some context.
Cattle vs. Pets
In server and infrastructure management, we often talk about the concept of cattle vs. pets.
Pets are machines that have special names (like frodo.mycompany.com). They’re unique, hand-cared for and, when sick, nursed back to health. There’s often an operation staff focused on keeping these machines running like clockwork.
Cattle, on the other hand, are machines that have numbers (like pod-01-mycompany.com). Typically, from an operations perspective, we view them as completely identical to other cattle out there, so when they’re ill, you get a new one. In such scenarios, operations staff members tend to think about how to automate creating a new cattle, as well as how to automate processes like backup and restore.
Virtual Machines
Virtual machines (VMs) virtualize hardware and allow you to run multiple operating systems on one big-blade server in a data rack.
Advantages:
- Fewer flexible VMs with multiple workloads: A lot of the time, people use VMs when Neo4j isn’t the only thing running on the machine.
- Easier to migrate to if you’re coming from an existing legacy software or platform.
Disadvantages:
- Tend to be heavier on resources.
- Usually managed as pets: If you run many different processes on a single VM, you’re going to get into the mode of operating and maintaining it overtime.
Containers
Containers, on the other hand, virtualize the entire operating system (OS). People tend to put only one thing in a container, which almost never runs three different programs inside of it. They generally only run one thing.
However, you’re able to run multiple workloads and containers on that one machine. It’s essentially a different way of thinking about the same problem.
Advantages:
- Light.
- Starts fast.
- Reduced memory management overhead.
- More portable than a VM: You can pick up a container and you can move it to a different cloud-computing provider if desired.
Disadvantages:
- Proliferation and management: Once you’re fluent with containers, you often have too many and need to manage all of those containers.
- Requires careful security configuration: There are special considerations in the security world for containers.
Unlike VMs, containers are typically managed as cattle. People don’t usually SSH into a container, fix the problem and keep the car rolling down the road. Instead, they throw the container away, spin up a new one and keep their service in place without much maintenance.
Neo4j in the Cloud: Approaches
This all brings us around to how it applies to Neo4j. We support a couple of different approaches. Some of these approaches are template-based and others are roll-your-own based. I’ll briefly discuss the differences between the two.
In the template world, what you’re basically performing on a cloud-computing provider is deploying a lot of resources – Neo4j being one of them – and possibly creating a virtual private network with multiple IP addresses as well as some hostnames for these databases. From then on, we’d want to wire it all together into a working cluster of a particular configuration.
We provide templates for all of this. On AWS, they have a technology called CloudFormation, which is just one way of expressing this template and deploying a set of resources. On Google, it’s called Deployment Manager, though conceptually, it’s the exact same thing. On Azure, it’s (again) the same concept, just with a different marketing name: Resource Manager.
A pro of a templated approach is that it’s a fast startup. If you only have 10 minutes but you need a cluster, this is the way to go – I can give you a cluster really quick and it’s just going to work.
The downside to the templated approach is that I’d need to make some decisions for you in the process. I probably don’t have perfect knowledge of what your company’s IT structure looks like, and maybe you need it deployed into a particular virtual private cloud (VPC) or need a specific security configuration. The template I created might not do that for you. After all, the main focus of the template is just to get you up and running quickly with a provenly-good figuration for a complicated cluster setup.
The second option is the roll-your-own approach. What we do here is provide raw containers and VMs. In the roll-your-own world, using an Amazon image for Neo4j is equivalent to the ability of starting a new virtual machine that has Neo4j pre-installed and configured.
However, this approach only provides fast startup for a single node, and just gives you one machine. If you want to put three into a cluster, you’re always required to do that configuration yourself.
If you’re trying to get started quickly and easily, it’s a con, but if you have very bespoke requirements that you need to satisfy, it’s definitely a pro. You have total control and power.
The overall message here is that we try to provide many approaches, and we’re happy to provide additional help and guidance on choosing if that’s useful for you. At its core, we want to support various methods and modes of deploying.
Neo4j Cloud Availability
I’ll now briefly discuss cloud availability. Cloud images can be thought of like other packing formats, such as Debian, RedHat and Windows package versions. In today’s day and age, the cloud platforms are just other platforms like Linux or Windows. You’ll want to be able to run them on AWS – and we want to meet you there.
By themselves, they require installation and configuration. You’re able to launch it and produce a single node that works out-of-the-box, but its configuration might not be optimal for your case; you’d probably want to go in and configure as you see fit. As discussed earlier, these templates are reasonable best-practice defaults, but still may require design.
I’ve had a couple of customers approach me after seeing our templates and say how our templates don’t fit their security topology, for example. From there, we give them the template – all other bits and pieces – and show them how to change it, but designing it for IT architecture is ultimately something that has to be done company by company for specific use cases.
Cloud-Specific Extras
When you download Neo4j off of the website and run one of these cloud instances, APOC and graph algorithms will be installed automatically.
When I first started publishing these – Amazon images in particular – 100 percent of my early requests were for APOC to be installed, so now it comes packaged by default. If you’re in the roll-your-own mode and can’t use APOC because of local security restrictions, you can simply remove it.
We also have a series of cloud startup scripts. For those who aren’t used to operating in a cloud environment, it’s much more dynamic than working inside a data center in that you can have a machine with a dynamic IP address. When you shut it down and restart it, it comes back alive with a different IP address.
We’ve added some extra features to keep track of that, so your default advertised address – how your node talks to the rest of the world – keeps pace with IP address changes.
We also have community support that’s always available. Check it out – there’s great content, blogs and discussions. You’ll find a lot of technical answers coming from here, as we’ve published knowledge-base articles, troubleshooting articles and all kinds of other content on that site.
Amazon Web Services (AWS)
Now, let’s talk a little bit about Amazon Web Services (AWS). If you’re on AWS, you probably know about the marketplace. This is AWS’s concept where you search for a solution, press a button and answer a few questions. Bam – solution deployed.
Marketplace: Causal Cluster
Neo4j Enterprise Causal Cluster is also out there and you can find it today. When you subscribe to this in Amazon’s language, it’ll ask you some questions, such as how big you want your machines to be, how large you want your data disks to be when they attach to them and how many nodes you want in your cluster.
That’s about it – there’s not a whole lot of technical configuration beyond that.
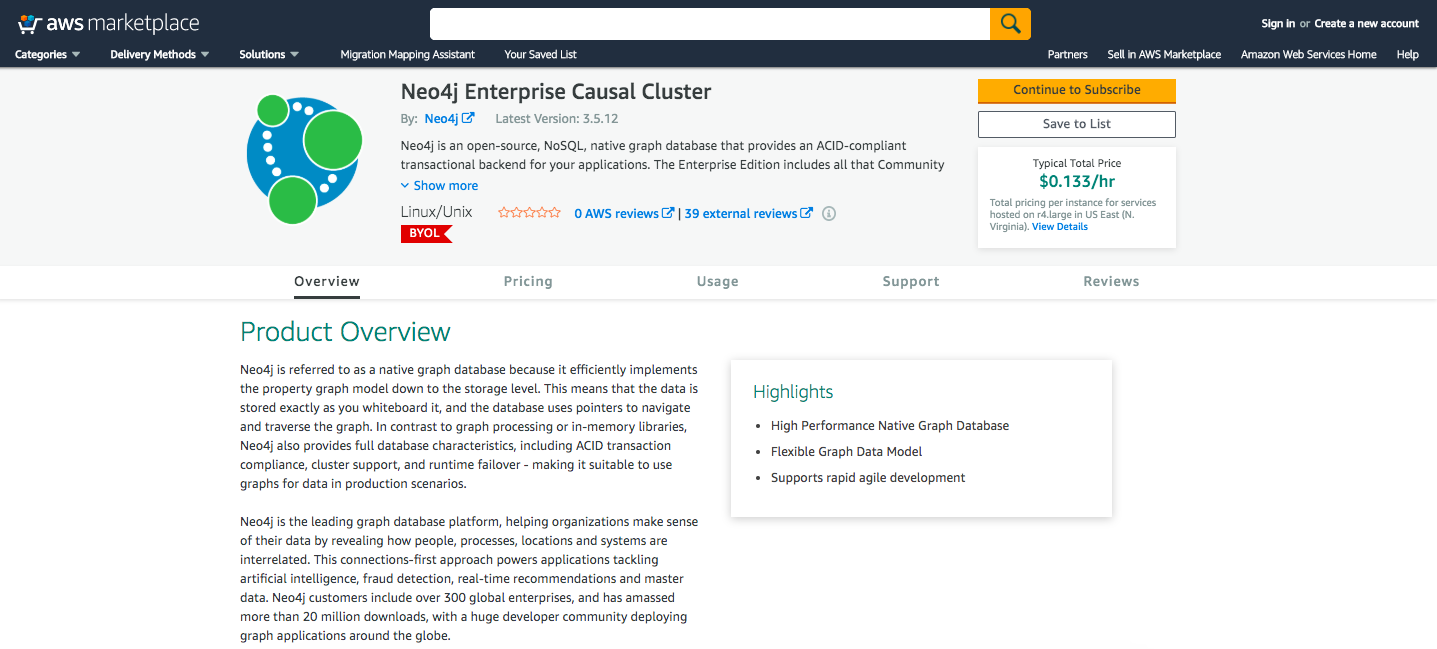
After clicking launch, a cluster is formed five or six minutes later. You’ll end up with an endpoint, specifically a bolt endpoint, where you’re able to directly attach apps like Bloom. You’re also granted SSH access.
Regarding all of these marketplaces we’re talking about, keep in mind that you still own and operate the VM. You have root access to all the VMs that are spun up inside your cloud organization.
In causal cluster, the cluster is fundamentally replicated. The default is that you’re going to stand up three nodes, not one.
For example, in the clustered configuration for Neo4j, let’s say you have three nodes – you can talk to any one of the three and execute Cypher. If a disaster happens, AWS loses a data center and one of your nodes completely disappears, your entire graph is still available online.
If you have three nodes, you can lose one and you can still read and write your graph. If you lose two nodes out of three, your graph is still available but you can only read it. If you lose three, well I can’t help you. In that case, you’d need a five-node cluster or more reliable hardware.
So on AWS, if what you’re after is a cluster of VMs, this is the best option.
Marketplace: Community
In the marketplace, there’s also community edition. Community is obviously always single-node: the clustered deploy isn’t supported under community, so it’s best if you want a single VM for testing or for an open source project.
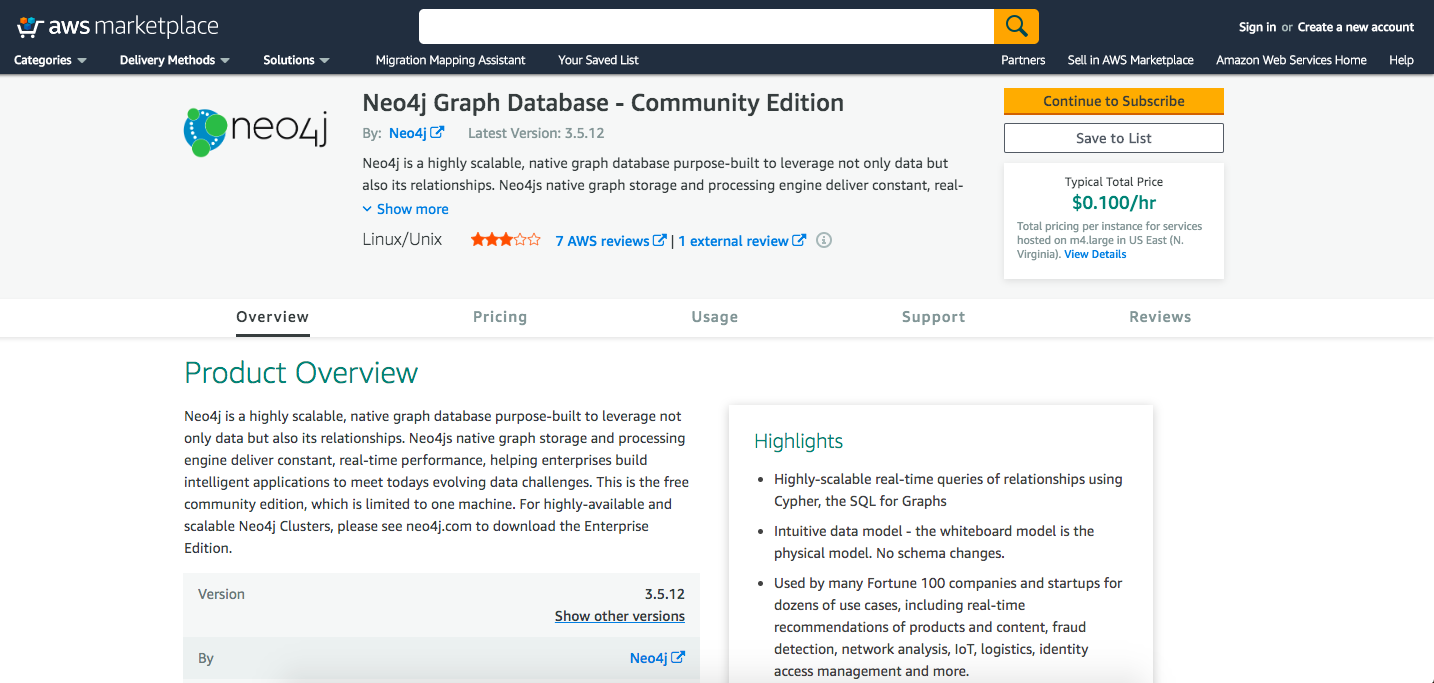
If you want to do the equivalent of Neo4j Sandbox – a.k.a. spin up a VM, try something out and load some data – this is a quick way to do so with pretty much zero setup. When you’re done with it, destroy the VM and you’re back to normal.
Public AMIs
Public Amazon Machine Images (AMIs) are the equivalent of the roll-your-own option in the Amazon world. They’re literally an image of a virtual machine.
Thankfully, Amazon makes it really easy to launch an instance of this to create a new VM. If you’re looking for the ability to have fine-grained control over your configuration, you would do it this way.
On the community site, I posted that we now have 3.4.7 with APOC and graph algorithms, and I also gave the AMI IDs. If you’re a developer and you know how to launch this type of stuff on AWS, it’s as simple as plugging in an ID, clicking and launching. It goes very fast.
Google Cloud
Now, let’s delve into Google Cloud.
GCP Marketplace: Virtual Machines
In the GCP marketplace, there’s Neo4j Enterprise. Basically, you go there, click “Launch on Compute Engine” and it’s a similar flow as AWS.

This is for multi-node cluster setups – it’s the replicated, three-node cluster setup that has high availability. It’ll also allow you to create both core nodes and read replicas.
In Neo4j’s cluster architecture, core nodes guarantee high availability and read replicas help scale out your read workload.
Suppose you have a transactional database. Everyday, your customers are hitting it, so it needs to be up at all times to handle the transactions that are coming through. But, once a month you have to do analysis on your database and run big, heavy queries that take a lot of memory and CPU.
A read-replica in your cluster architecture keeps pace with what’s in the database – you’re able to run those heavy queries against a read replica with zero disruption to your production system.
All of these templates are built to allow you to scale in whichever way you’d like and pick how many cores and read replicas you have. How you design this and how many nodes you put into each category just depend on what you’re trying to do.
Google Kubernetes Marketplace: Containers
Google also has something that’s a little bit different; they have a Kubernetes marketplace. They want to be known as the best at managing Kubernetes clusters, so they have a managed service called Google Kubernetes Engine (GKE), which allows you to create a Kubernetes cluster.
At Google, the vision is that you’re going to have a Kubernetes cluster and run a lot of workloads on top of it. It’s essentially a pool of nodes – whenever you need to run some new program, you’ll schedule it onto that pool rather than creating a server for the purpose of running this application.
At Next ’18, they launched the Kubernetes marketplace, which is just like a regular cloud marketplace but for applications that run on top of Kubernetes.
Neo4j was announced as one of the launch partners. Now, you have the ability to configure and deploy a Neo4j cluster into a Kubernetes cluster – that is, a cluster in a cluster – with Neo4j Enterprise Causal Cluster.
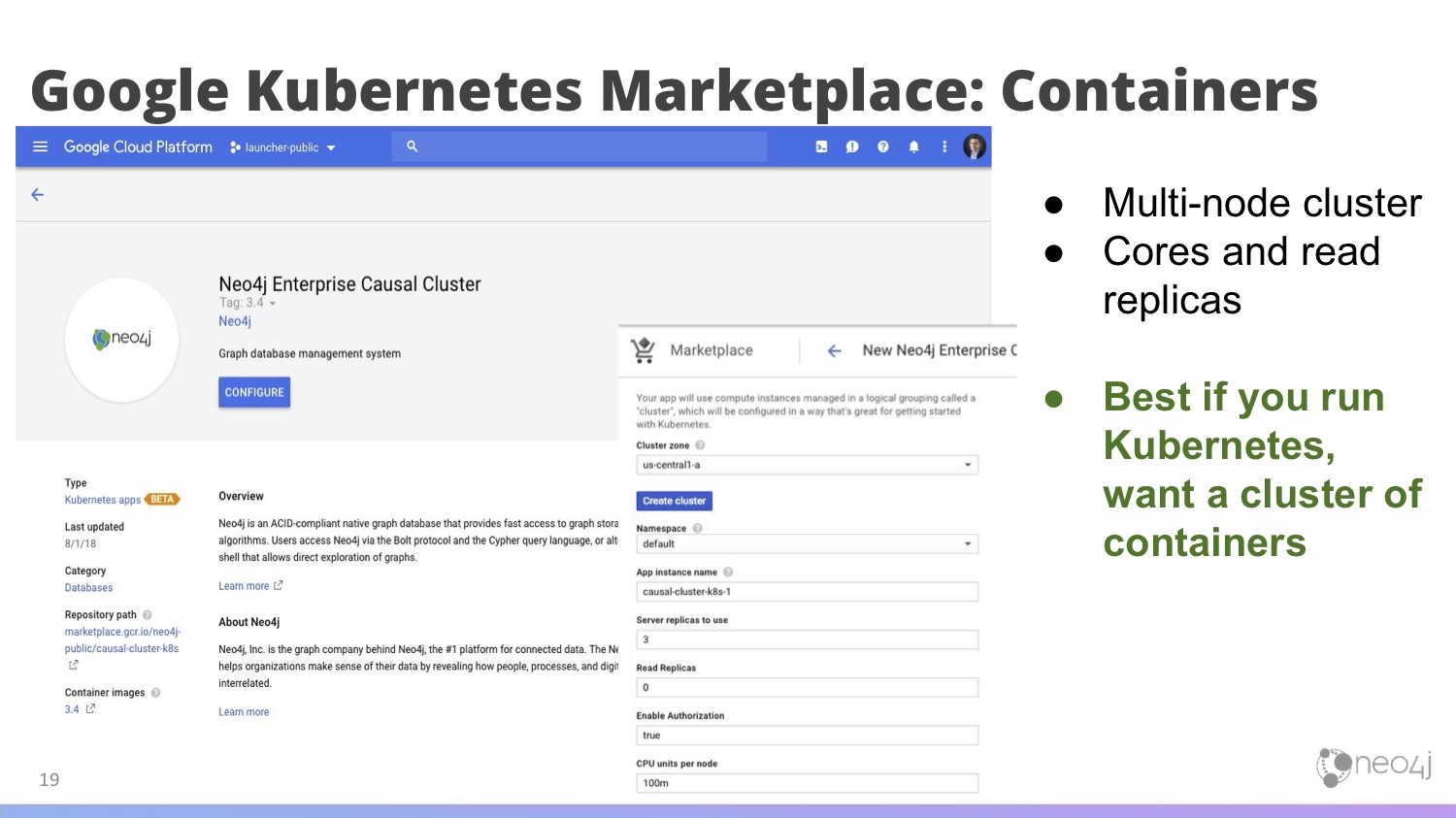
This is similar to the marketplace entry, where what you’re getting is a multi-node cluster of read replicas. However, it’s best if you run Kubernetes, if you’re interested in running a clustered setup and if you want to use Docker containers.
And why would you do that? There’s a bunch of different reasons. Some of our customers are moving towards Kubernetes because of its workload portability. If you have a Kubernetes cluster, you’ve abstracted away what cloud you’re using. Essentially, you have a big pool of virtual machines and you’re scheduling your workload onto that.
If you have a GKE cluster, one of the things you can do is add a new pool of machines on Amazon and then shift the workload from one cloud to another by simply scheduling it into a different node pool on Kubernetes.
If your company isn’t doing this now, that’s perfectly okay in that it’s still a little bit forward-leaning. But in the coming years, we’re going to see more and more adoption of this type of technology, in part because it frees some companies from cloud-specific lock-in for their workloads.
Because Neo4j already had great support for Docker, it was pretty straightforward for us to add and support this.
Neo4j Test Drive
On Google, there’s also Neo4j Test Drive, which is similar to Sandbox in that they’re both environments where you can launch a time-limited graph. Test Drive provides a small node for free – you don’t even need to have an account with one of these cloud providers. From there, you create a graph, and in this particular test drive, it comes pre-populated with data.

If you’re at the learning stage, want to play with Cypher or want your own little sandbox to mess around and try things out, this would be the ideal way to do that.
Test Drive also has built-in browser guides, so you don’t start with an empty screen, but rather with a tutorial that provides the basics of what graph databases, nodes and relationships are. Moreover, it’ll allow you to run some interesting queries and see results right off the bat.
Of course, you wouldn’t run this in production, but if you have folks in your organization who’d like to understand what Neo4j is and what it offers, this would be the perfect new-user entry point.
Google Compute Engine Images
Finally, we have Google Compute Engine, which is Google’s term for EC2. They all have very conceptually-similar offerings. We have a number of images available – this is the roll-your-own deployment option for Google Compute Engine.
Microsoft Azure
Our work with Microsoft Azure is still in progress; if you go to Azure catalog right now, you’ll find Neo4j HA available, which is the high-availability product that came before our latest causal clustering product.

We’re currently working on deploying all these concepts we’ve talked about for Amazon and Google, but now for Azure as well. Basically, you’ll also have templates for clusters, images for single nodes and an easy way to deploy a single node.
Though the engineering on it is basically done, we’re just working through the process of getting it approved and listed on their marketplace.
Recent Developments: Pivotal & Oracle Cloud
We’ve recently added Pivotal PKS as a cloud option, which is also Kubernetes-based. Check it out here. Additionally, we offer a VM image on Oracle cloud.
Running Docker Containers
Let’s discuss a little bit more about running Docker containers. Up until now, we’ve focused really heavily on virtual machines.
However, if you want to run bare Docker containers and don’t yet want to do Kubernetes because that’s a step too far for you, all of these cloud-computing providers provide easy options.
On Amazon, it’s called ECS. On Google, you can either use Kubernetes, or you can also run a Docker container on top of a VM whose sole purpose is to run a Docker container. On Azure, it’s the same thing again; you can basically deploy Docker Enterprise Edition and run containers on top of that. This is a different option that some people use as the equivalent of roll-their-own of Neo4j.
The one thing I wouldn’t recommend would be setting up three individual docker containers and managing the connections between them in order to obtain a cluster of three Neo4j machines. This is possible, but causes a lot more pain than necessary.
Docker Considerations
Docker doesn’t come with APOC by default, but it’s extremely easy to add.
Currently, we’re also working on improving Docker documentation. There are some edge cases as well as more advanced things people are trying to do with the Docker container that are supported, but we need to be doing a better job of explaining that in clear terms so people can get started and running quickly.
Neo4j and Kubernetes
I want to talk a little bit more about Kubernetes, and I’ll do so by first explaining what a Helm Chart is.
Public Helm Chart
A Helm Chart in the Kubernetes world is akin to the templates that describe what a cluster is, what the resources are and how they connect to one another.
Neo4j offers a public Helm Chart on this GitHub repo. If you’re running Kubernetes but you don’t think GKE is for you, you can deploy Neo4j on any Kubernetes cluster using this set of open source artifacts. Basically, you create a copy of the repo, type one command – as long as you’re authenticated against your Kubernetes cluster – and that’s about it.
Another nice thing about this is that it’s both template and roll-your-own. Because you’re getting the chart, if you have local Kubernetes people who want it configured in a different way, you already have the source code.
Neo4j on K8s: What’s Happening
In Kubernetes, they refer to pods, which are just machines that are running. They’re basically instances of the docker containers. We take the container and make a new machine out of it – that’s a pod in Kubernetes land.
Kubernetes also has this concept of a replica set, as shown in the image below. Say you want a cluster that always has three machines. If something bad happens to one of those machines – such as a failure of any underlying hardware, power supply or disk – Kubernetes will kill the machine with the problem and create a new one in its place that’s a copy of that. In this way, you’ll always have three machines available.
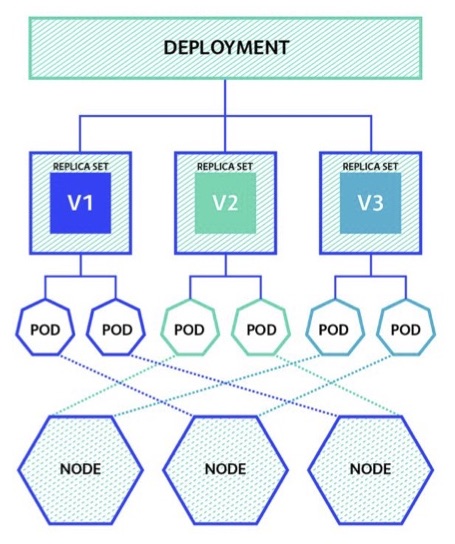
There are also situations where an underlying hardware server may have a problem and cause one of your nodes of your cluster to fail. However, you wouldn’t even notice it because Kubernetes creates a new one under the covers and knits you cluster right back together.
The underlying nodes are the VMs or the hardware are at the very bottom of the graph. This is what I meant earlier when discussing the pool of resources. What we’re seeing some companies do is that they have a fleet of 200 machines, 500 machines, whatever the number is. All of the workloads – whether it’s a marketing application, a customer-facing system or a database – are put onto that pool.
If you start operating hundreds of machines, one of them within that pool is going to fail almost every month. However, if you have a flexible management framework on top like Kubernetes, you’ve abstracted away some of those problems. You might not even notice anything even through some of those IT disruptions.
This is just one of the compelling things about containerization in Docker, and it ties back to the concept of cattle versus pets. If you’re taking care of each machine carefully and individually, it’s very difficult to operate in this mode because you set it up in a way that management technology like Kubernetes is told what a good, healthy machine looks like and to make another one when a problem arises.
This all implies more automation and less manual work, which in turn helps us go faster.
Network Security & VPC
The last thing I’ll discuss regards network security. Databases don’t exist in isolation, and they’ll inevitably be a part of a complicated architecture that a company has. This all raises the important question of where to put Neo4j into that architecture.
I wrestled a lot with this when building all of the cloud stuff because in the template world, I had to make some of these choices.
In the image below, we have these three setups.
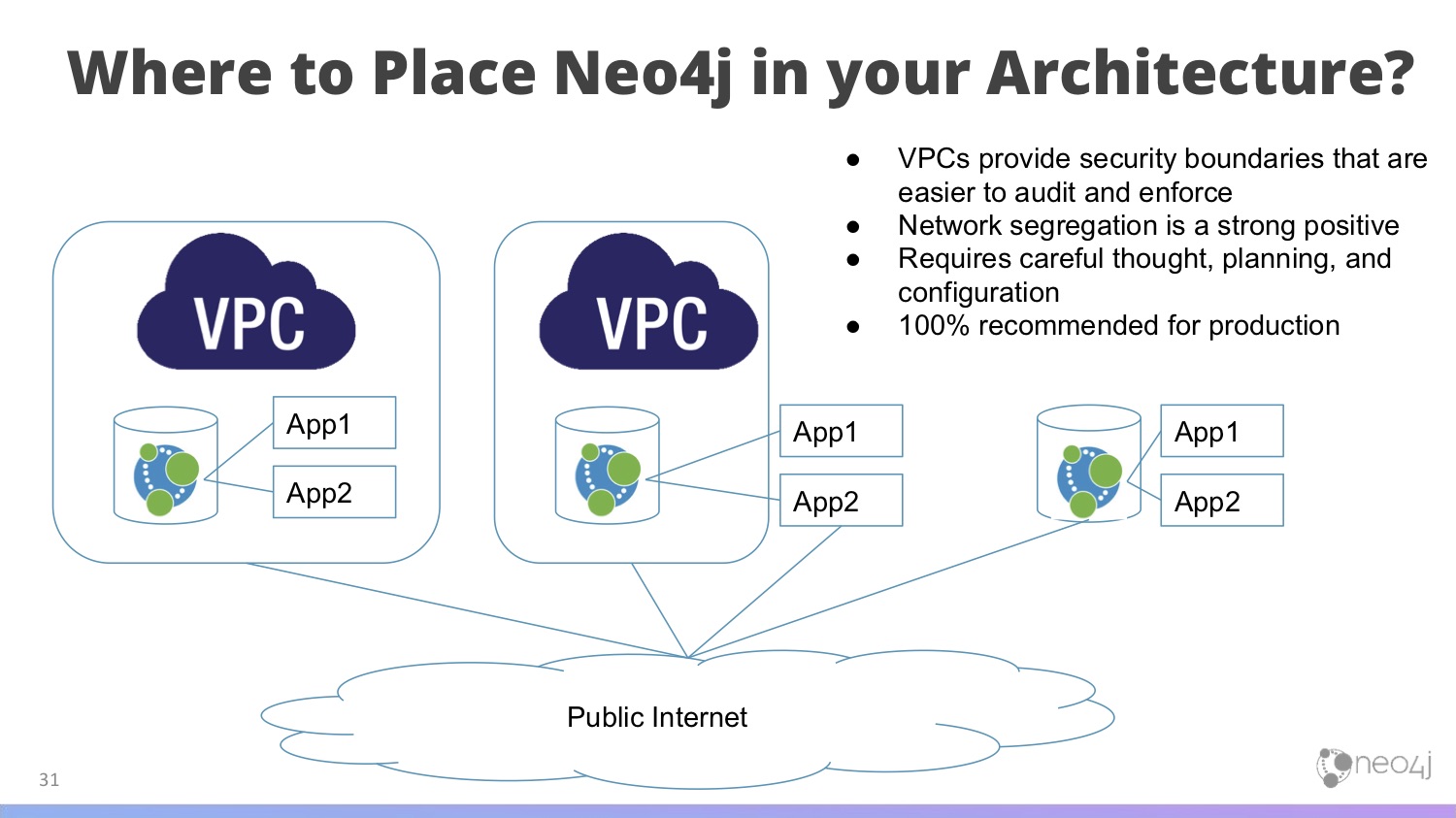
In the setup on the left, you have a virtual private data center, with Neo4j talking to whatever applications need to use in your graph. This line around it is a hard wall – no traffic gets in or out. In this world, if you’re at home on your laptop and try to reach this database, you can’t. It’s a security measure to prevent random people on the internet from connecting to your database or logging in to it.
In the second setup (the one in the middle), we put Neo4j inside of a VPC, but the applications reside outside of the VPC. Imagine you have a customer-facing website and you’re trying to sell some products. The products have to be publicly accessible or you can’t do business, but it needs to talk to something that isn’t.
Third, in the architecture on the right, you’re exposing everything publicly on the internet. This is super convenient, easy and usable, but it’ll make your security team sweat. It means that anybody from anywhere – using any exploit they found on the internet – can connect to your machine, which wouldn’t be a good idea.
Overall, VPCs provide security boundaries that allow you to audit and enforce things. Network segregation – where we chop up the network, create gates and only allow traffic through at certain points and conditions – is good operational deployment practice, but requires careful planning and configuration. We definitely recommend this for production, as part of a good network security posture for deploying Neo4j.
When we created some of these cloud templates, we had to strike a balance. In general, we made it so when you deploy Neo4j in the cloud, you’ll automatically get something you can connect to from the internet.
That’s one of the things you’ll want to look into before you go to production with some of these templates and AMIs – that the overall security architecture of where they fit, what applications they need to talk to and who’s allowed to log in makes the data stay secure and not just available.
Summary and Conclusions
A quick summary of all the technical details we’ve discussed so far:
- You can now go from zero to a scalable cluster in five minutes on these cloud-computing platforms: Just go to their marketplace entries, click configure, plug in some variables – five minutes later, you have a working cluster.
- You can build single machines and enterprise as you need it.
- We always provide love for our community users: Come by the community site and let us know how to make it better! We’d love to hear from you.
Share Article



Explore
Related Articles





