Neo4j ETL 1.2.0 release: What’s new + demo


7 min read
In the last seven months since GraphConnect New York, we have worked on enhancing the Neo4j ETL tool adding support for all relational databases with a JDBC driver.
We also did some backend optimizations and made few changes to the UI for Neo4j ETL. With data and databases being messy, we also fixed a number of issues resulting of under-specified data operations.
The tool is now fully integrated with Neo4j Desktop (from version 1.1.3), and a Neo4j ETL activation key will unlock it for you. Please ask your trusted Neo4j contact for one or send an email to [email protected]. After adding the key, you can then add Neo4j ETL as an additional graph-app to your projects.. (Edited 9-March-2019: Activation keys are no longer required. More information in our update on the 1.3.1 release.)
The new release has a number of new features and capabilities that we’ll discuss below. But first, we want to demonstrate the tool in action.
If you’d rather watch it in action, we also recorded a quick demo:
ETL data transfer from Microsoft SQL Server
Let’s see how to define a connection to a relational database (for this example I use a Docker instance of Microsoft SQL Server).
Project selection
After starting the Neo4j ETL tool you select the project you want to work in from the drop-down box.

Connection setup
On the left sidebar, click on Connections and then set up the database connection.
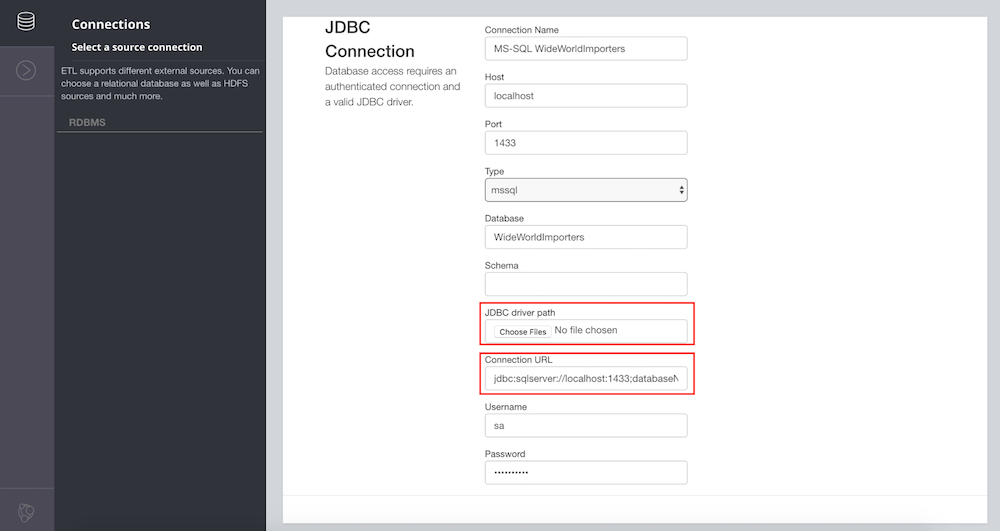
MySQL and PostgreSQL drivers are bundled, so if you use a different database, then you have to provide a valid JDBC driver (jar-file) via JDBC driver path.
You can also change the suggested connection URL.
Test and Save the MS-SQL WideWorldImporters connection.

Metadata mapping
Afterwards, we’ll continue on the other sidebar tab (>), a.k.a., Import data from source in the left sidebar and then click on IMPORT DATA.
Now we’ll inspect my relational database metadata and see the resulting data mapping.
Before doing that, you have to choose:
- The source, that is the JDBC connection to the relational database and
- the Neo4j target instance.
The ETL tool is fully integrated with Neo4j Desktop, so I can see all Neo4j graphs that are defined for a specific project and also the current status (running, stopped, etc.).

From this frame, you can also delete your source connections using the (x) icon on the connection box.
After clicking Start Mapping, the Neo4j ETL tool starts to inspect the relational database and extract the database metadata into a JSON file representing how tables and columns are to be mapped into the Neo4j graph database. The log output is then displayed in the lower part of the frame.

Clicking Next gets us on the next screen, which is the Mapping Editor.
Mapping editor
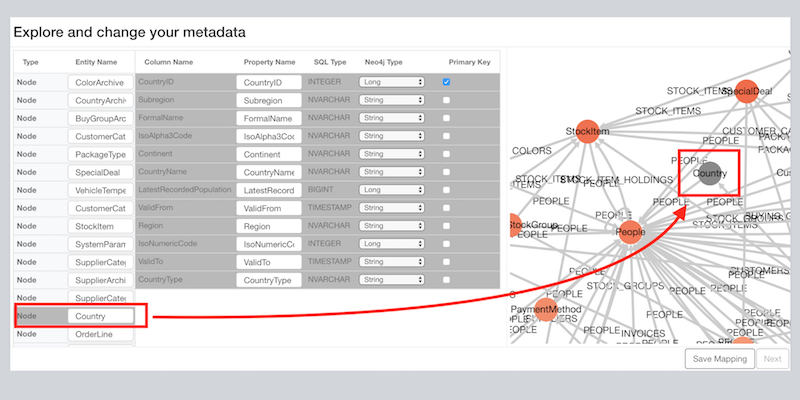
The WideWorldImporters database is made of a lot of tables, so the resulting mapping is quite complex. Here I am focusing only on the Country table where I can see all the columns, their data types and how they are converted to Neo4j data types.
Using the Mapping Editor, I can change:
- The name of the resulting node,
- The name of each property and
- The resulting data type
The latter might result in conversion issues so pay attention when doing data type conversions.
Once I have completed all the changes, I can Save Mapping which stores the edits. And then I start to import data from the WideWorldImporters database to the Neo4j instance.

Data import
In the last frame, you can choose one of four import modes:
The first two modes (neo4j-import, neo4j-shell) are offline (i.e., Neo4j should be stopped before running them) while the others (cypher-shell, direct cypher) are online modes.
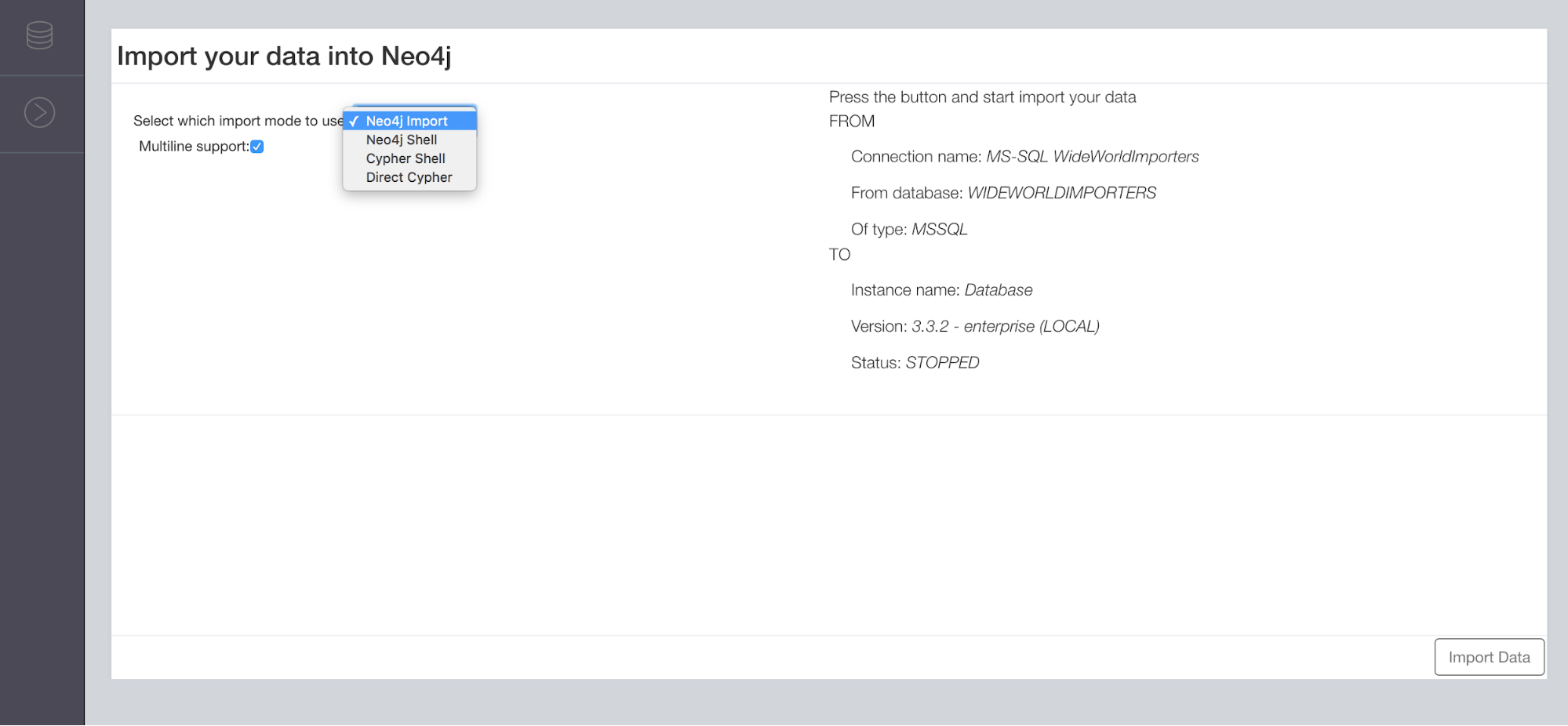
If you try to import your data with an online mode but your instance is stopped, you will get an error conversely, and vice versa.
The import will stream results and also report the update statistics.
After the import from the relational database to Neo4j is complete, you can explore your data through the Neo4j Browser. For example, starting from a country (Italy), you can see the (limited) related entities until the third level of relationship.

New features and bugfixes
- Multi schema support: the Neo4j ETL tool now can “parse” more than one schema at time.
- Additional driver support: The Neo4j ETL tool comes with two embedded JDBC drivers (for MySQL and PostgreSQL), but you can set up an external JDBC driver for Microsoft SQL Server, IBM DB2 and Oracle RDBMS (the list is not limited to these drivers but they are the default ones in the combobox). You can add a jar using the
--driverparameter. - The resulting mapping file can now be written to a file without output redirection using
--output-mapping-file. The mapping file now is also different for each import, currently the following naming convention is supported:<databasetype>_<databasename>_<schemaname>_mapping.json. In future releases, we want to move this file into the same directory where all the CSV files are created. - Fetch size has been added to a default value of 10000 records. It will be configurable in future releases.
- The Neo4j ETL tool has undergone additional testing with Microsoft SQL Server sample databases AdventureWorks and WideWorldImporters and a DB2 sample database in addition to the previous tests.
- When importing through Cypher, all fields are now mapped correctly according to their data type. Now the Neo4j ETL tool creates a separate directory for each schema/catalog when writing the CSV files.
- Schema names are well-separated from table names: The Neo4j ETL tools doesn’t rely anymore on splitting names with
.in order to separate the schema name from the table name. These changes also reflect on themapping.jsonfile where the name of the schema is explicitly written. - The concept of catalog/schema has been generalized, so when you need to filter what you’re going to inspect use the
--schema parameter. If using the UI, you don’t need to think about this. - CSV files are now escaped according to the standard CSV escaping rules. No more backticks appear as a quoting character.
- No more numeric overflow when converting numbers from Oracle 11 or older versions.
- Constraints are now created correctly according to the information that is retrieved by the
SchemaCrawler. Currently there is no support for multi-column primary keys, but we are working on it, and it will be available in the next release.
Neo4j Desktop ETL – UI updates
- UI updates now reflect all the previously listed capabilities (see screenshots above).
- Once a database connection is defined, it’s now possible to remove it using a X icon on the top-right corner of the connection box.
- Bugfix: No more
stdout buffer exceedederror when creating big mapping JSON output from the UI because the way the UI writes the JSON file has been reviewed to handle big JSON files better.
Documentation
The documentation was updated to explain how to setup a Docker container with a MS-SQL sample dataset in addition to new command-line interface options.
Try it now
Try out the new release via either the command-line tools or the mentioned Neo4j Desktop Graph App.
A big thanks to everyone for giving us feedback and suggestions that help us to improve the Neo4j ETL tool. Please continue to provide feedback by either submitting GitHub issues or joining neo4j.com/Discord and asking in the #neo4j-etl channel.
Click below to get your free copy of the Learning Neo4j ebook and catch up to speed with the world of graph database technology.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


A workbench for teams to query, explore, and visualize graph data


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.
