Neo4j: From graph database to graph platform

Product Team
12 min read
Today at GraphConnect New York, Neo4j has announced our transformation from the provider of a graph database into the creator of a graph platform.
We are making this change to address the evolving needs of customers in their deployment of Neo4j, in both needing to interoperate within a complex IT infrastructure as well as to help a variety of users and roles succeed with Neo4j.
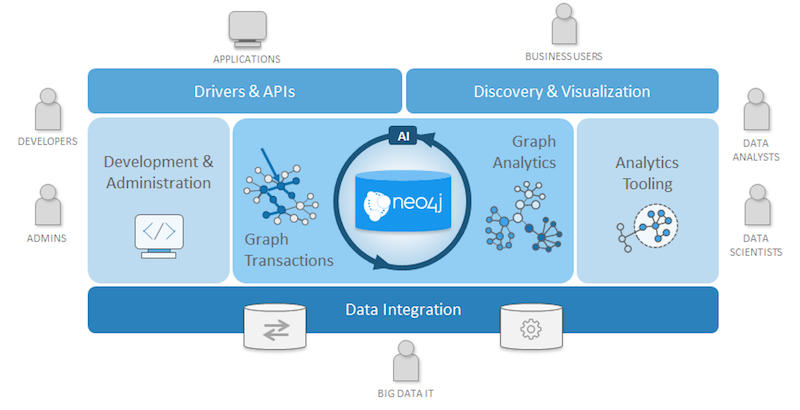
The figure below depicts both the elements of the platform as well as those user roles that they serve. As we look at this new graph platform strategy, we’ll consider these capabilities within those user contexts.
The Neo4j Graph Platform is designed to help you introduce graph technology and Neo4j beyond just developers to new users, like data scientists, data analysts, business users, and executives.
In deploying the platform, your big data IT teams will enjoy new data integration features designed to make fitting within your infrastructure easier. This is so data scientists and analysts can use new tooling like Cypher for Apache Spark and the graph algorithms library to support their graph analytics needs. All while helping business users understand and participate in the evolution of graph-based applications.
Looking deeper at the platform
The Neo4j Graph Platform is built around the Neo4j native graph database and includes the following components:
- Neo4j Desktop is developers’ mission control console for all things Neo4j
- Neo4j Native Graph Database supports transactional applications and graph analytics
- Neo4j Graph Analytics helps data scientists gain new perspectives on data
- Data integration tools expedite distilling RDBMS data and other big data into graphs
- Graph visualization and discovery help communicate graph benefits throughout the organization
- The platform-wide enterprise architecture supports corporate availability, scaling and security needs
Introducing Neo4j Desktop
Neo4j Desktop is the new mission control console for developers. It’s free with registration, and it includes a local development license for Enterprise Edition, and an installer for the APOC user-defined procedures library. It is available immediately and will become the vehicle by which most users experience Neo4j.
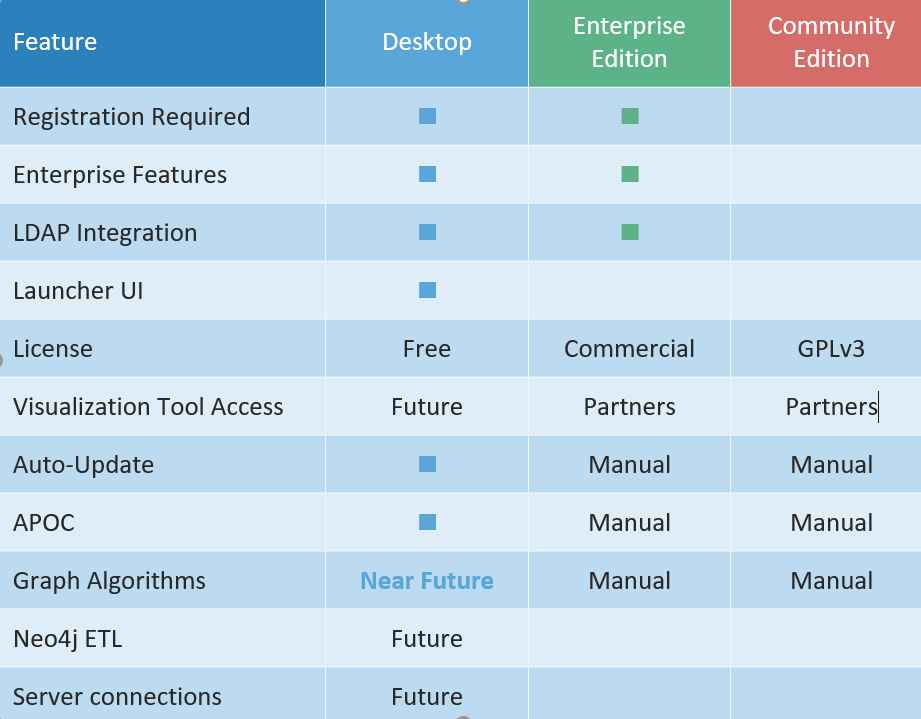
The Neo4j Desktop will evolve quickly and eventually connect to your production servers, and install other components like graph algorithms, run Neo4j ETL or upgrade Java. For developers, you get exposure to Enterprise Edition convenience features like:
- Built-in user management, user security, Kerberos authentication and LDAP integration
- Performance boost from compiled Cypher, enterprise lock management and space reuse
- Schema features like Node Keys, existence constraints and composite indexes
- Scaling features like unlimited nodes and relationships, and supported Bolt language drivers
- All platform components and interfaces like query management and the Neo4j Browser
- Exposure to production deployment features like high availability, disaster recovery, secure Causal Clustering, IPv6 and least-connected load balancing.
The amount of time these features save for developers is astounding. Users can download Neo4j Desktop immediately.
Now shipping: Neo4j graph database 3.3
Also for Neo4j developers users, we have shipped Neo4j 3.3, the latest version of the Neo4j graph database. In this version, we focused on improving write and import performance in Community Edition as well as cluster throughput and security in the Enterprise Edition. The result is that 3.3 writes are more than 50% faster than 3.2 and twice as fast as 3.1.
Let’s take a closer look at what we have improved since Neo4j 3.2:
Write data faster: Improvements to import and write speeds was the most popular request from users. Here’s what we’ve done to address that:
- Native indexes for numeric properties, improves inserts and updates speeds dramatically.
- The bulk data importer uses 40% less memory, and adds the ability to use the page cache when memory is full.
- In clusters, during high speed writing activities, we now pre-fetch node IDs in batches, which eliminates an annoying performance bottleneck.
- For very large graphs, we have move the metadata about the page cache, into the page cache, which allows more of the actual graph to be contained within memory and delays the need for caching to disk.
This is the fifth consecutive release to improve overall write speed, and this release’s improvement bumps are impressive.
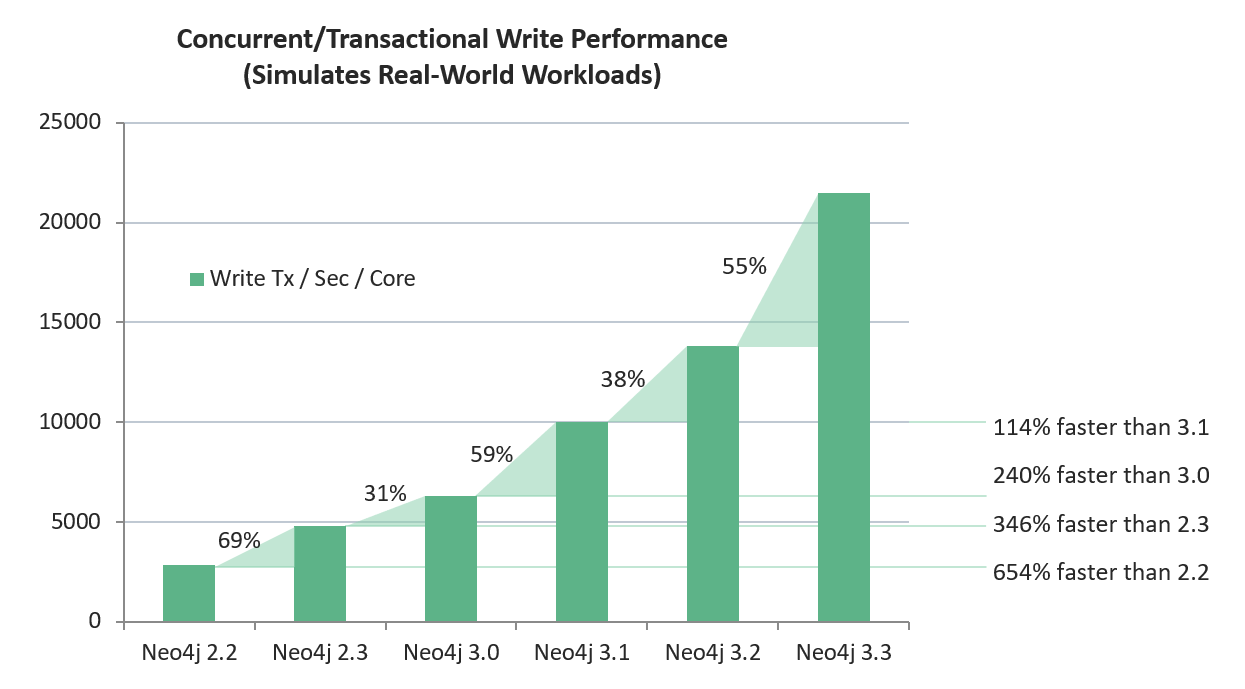
Cypher is faster: The Cypher compiler has been refactored and results in 30-50% faster Cypher execution.
Less intrusive locking and configuration updates: Local database locking rules are less restrictive, and some server configuration features can be changed without requiring the database to be restarted.
Cluster operations are faster and more secure in Enterprise Edition
Least-Connected Load Balancing: We have changed the automatic load balancer from round-robin selection to choosing active servers who are “least connected” first. This allows us to optimize the throughput of the cluster, and it works with the existing routing rules for transactionality, write consensus with Causal Cluster core servers, replication priority for read-replica servers, data center routing priorities, and read-your-own-write (RYOW) consistency support.
Intra-Cluster Encryption is now supported in Enterprise Edition, automatically securing transmissions to data centers or cloud zones. Because we are managing security ourselves, the certificate generation and management is built into the Enterprise Edition binary. Intra-cluster encryption supports backup and disaster recovery routing as well.
Enterprise Edition Binary supports commercial licenses only. In order to support the encryption functions above, the pre-built binary for Enterprise Edition is only available through a commercial license.
IPv6 : Causal Clustering also now supports IPv6 to extend its horizontal scalability.
Graph analytics with graph algorithms to extend OLTP functionality
Graph analytics help organizations gain a connections-first perspective of their data assets that may never have been revealed before. The new analytics functions includes the ability to materialize graphs from relational and big data (or any data), and then explore them in a “hypothesis-free” manner – i.e., without knowing what you are looking for.
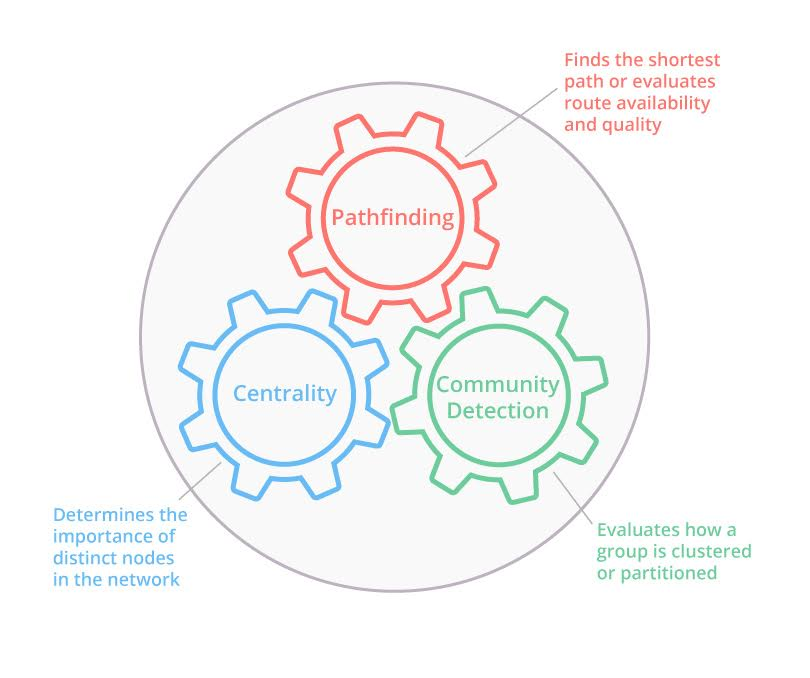
The new graph algorithms library supports the ability to detect hard-to-find patterns and structures in your connected data including:
- Community detection algorithms to evaluate how your graph is clustered or partitioned
- Pathfinding algorithms to quickly find the shortest path or evaluate route availability and quality
- Centrality algorithms like PageRank to determine the importance of distinct nodes in the network
Why do graph analytics matter?
The Neo4j Graph Platform helps operationalize connections revealed as “big data analytic insights” and turn them into high-value graph applications. In fact, we are starting to see customers support workflow loops that involve the activities of developers, big data IT data suppliers and data scientists.
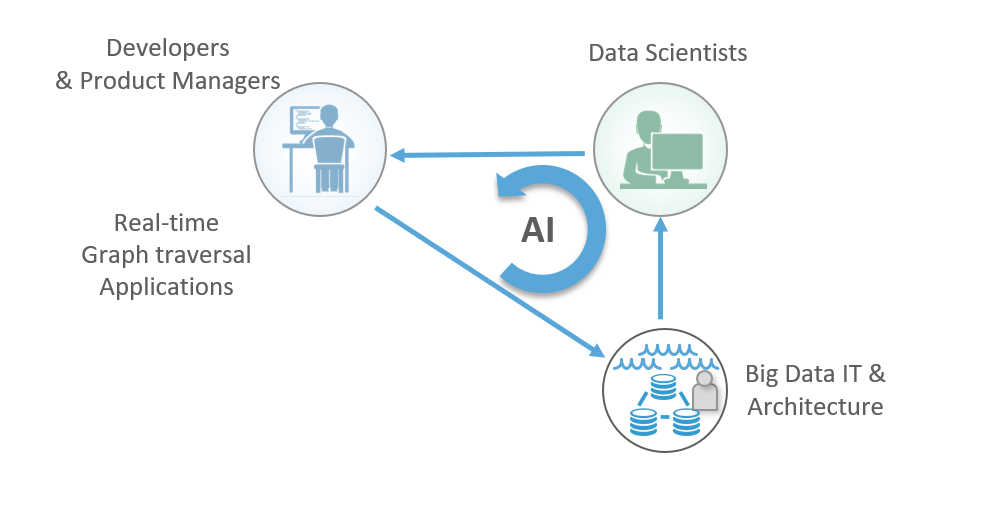
Here’s a sketch of what that workflow loop looks like:
- Developers build real-time graph traversal applications, which quickly become hungry to grow and need more data to connect and traverse.
- Big data IT can supply that new data and increase the utility of the data lake.
- Data scientists can use this existing and new data to explore, test and develop new algorithms and share them back with developers to operationalize in the application.
- The data scientists’ algorithms not only operate upon the expanded graph, they can add data and connections to the graph itself, essentially making it smarter for each subsequent query as the application operates.
- If you look at the interaction of these teams, you’ll notice a loop where developers, big data IT and data scientists help the graph application grow by itself. This is the foundation of artificial intelligence, and we call it the AI workflow loop enabled by the Graph Platform.
We see this AI loop in play in recommendation engines seeking deeper contextual connections, fraud detection applications mapping transaction and money flow, cybersecurity applications, and more.
We also see other emerging workflow loops:
- Knowledge Graph workflow loops involve big data IT, data scientists and traditional business analysts who all want a common catalog (ontology) of data assets and metadata, and these Knowledge Graphs want to represent how all these assets are related.
- Digital Transformation workflow loops between big data IT, business analysts who know both data and business processes, and the C-level initiative holder – like a Chief Data Officer or Chief Security Officer, or Chief of Compliance – all of whom need to see and understand how their information assets and business processes relate to each other.
Cypher for Apache Spark
We recognized the indisputable popularity of Apache Spark as an in-memory computation engine that supports relational, streaming, learning and bulk graph processing. Yet we also noticed that Spark’s graph capability is missing a declarative query language that enables pattern matching and graph construction.
To address this, and advance the adoption of graphs within the Spark and big data market, we have donated an early version of the Cypher for Apache™ Spark® (CAPS) language toolkit to the openCypher project. This contribution will allow big data analysts to incorporate graph querying in their workflows, making it easier to bring graph algorithms to bear, dramatically broadening how they reveal connections in their data.
Cypher for Apache Spark implements the new multiple graph and composable query features emerging from the work of the openCypher Implementers Group (oCIG) which formed earlier this year. The openCypher project is hosting Cypher for Apache Spark as alpha-stage open source under the Apache 2.0 license, in order to allow other contributors to join in the evolution of this important project at an early stage.
Cypher for Apache Spark is the first implementation of Cypher to allow queries to return graphs, as well as tables of data. CAPS introduces the newest features of the Cypher query language adopted in the openCypher Implementers Group.
The new features in Cypher will include:
- Multiple named graphs which allow Cypher to identify specific graphs upon which to operate.
- Compositional graph queries allows users to save graph query results as graphs in addition to Cypher’s default of returning tables. Supporting this allows compositional queries, which can be chained together in a function chain of graph algorithms, and this provides the building blocks for multiple graph-handling queries.
- Path control: New language features are in gestation to give user control over path uniqueness while defining traversal types like “walks,” “trails” and “paths” as specific patterns.
- Regular path expressions apply regular expression syntax in concisely stating complex path patterns when extracting subgraphs. It applies a powerful path expression language based on the leading-edge research language GXPath.
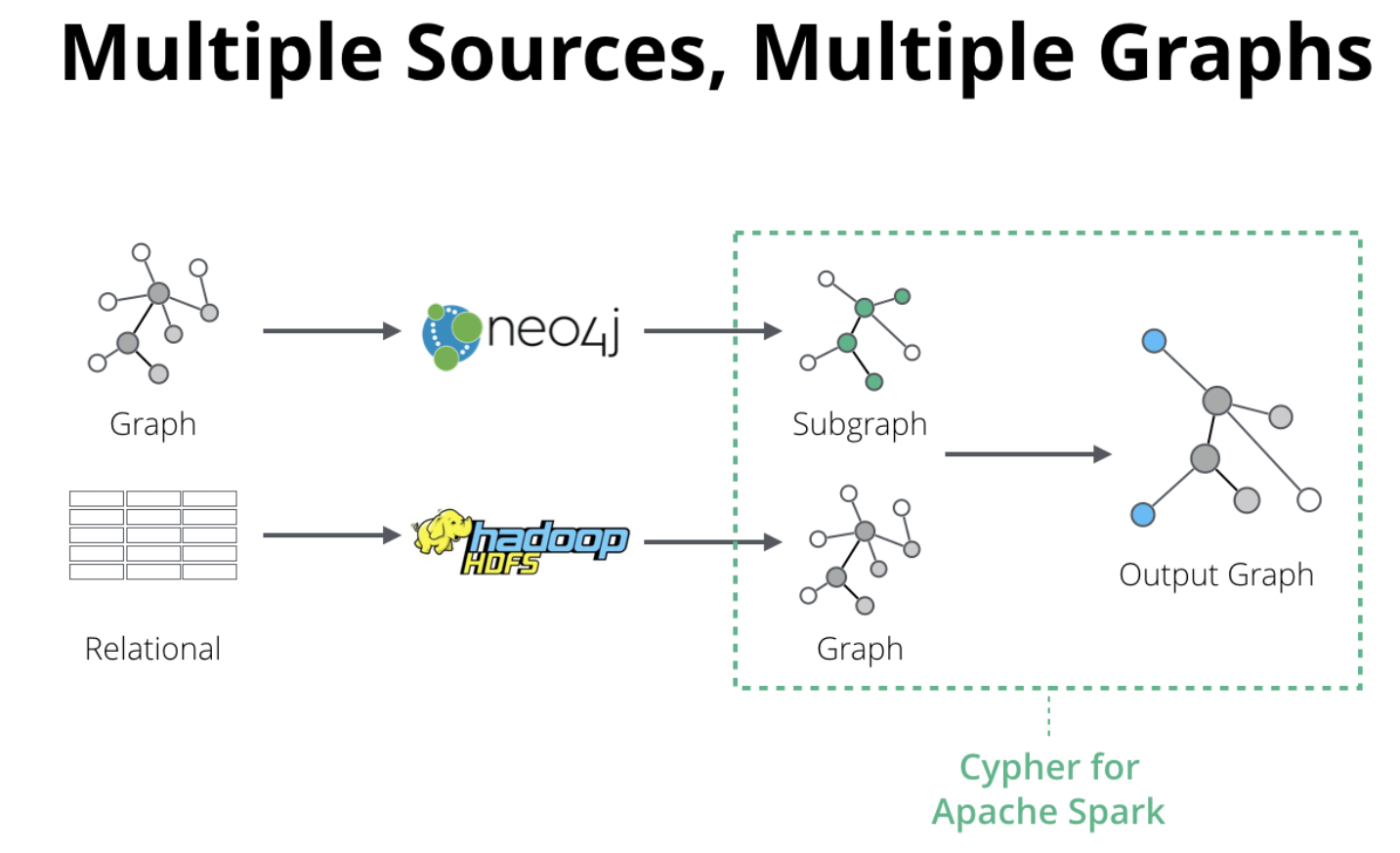
In making Cypher available for Apache Spark, we looked closely at the way Spark works with immutable datasets, and then in coordination with the openCypher group, brought in facilities that let graph queries operate over the results of graph queries, and an API that allows graphs to be split, transformed, snapshotted and linked together in processing chains that give huge flexibility in shaping graph data, including data from users’ data lakes.
Data integration
Fresh from the Neo4j engineering labs, the following are available as pre-release software from Neo4j product management or via special request through Neo4j sales to support enterprise data integration needs. We will continue to invest in both Neo4j ETL and the Data Lake Integrator (and more) to ease moving data in and out of graphs.
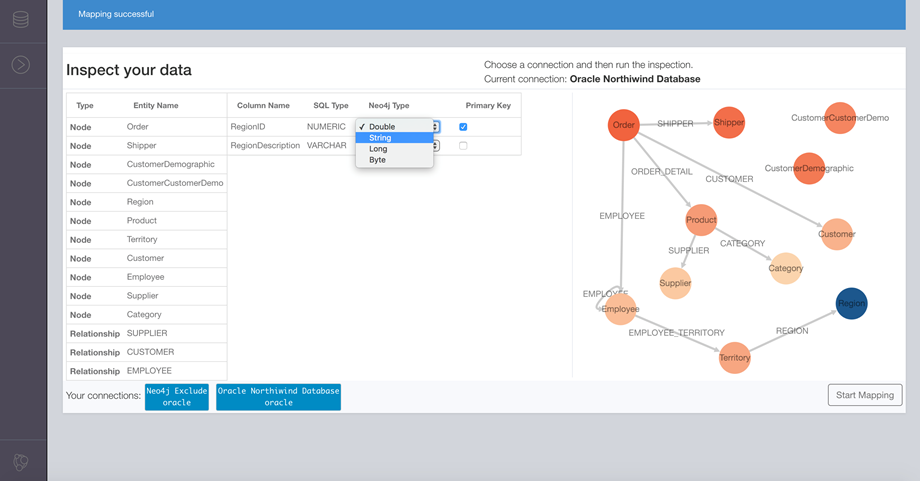
Neo4j ETL
Neo4j ETL reveals graph connections from relational/tabular data and delivers an exceptional initial and ongoing experience moving data into the Neo4j graph database. Its graphical interface allows the DBA to:
- Connect to popular databases via JDBC.
- Arrange table structures as labeled nodes and identify JOINs and JOIN tables as relationships.
- Map or change labels and properties prior to execution.
- Data is exported in graph-ready CSVs and fed to the Neo4j importer.
- Graph connections are materialized through relational JOINs as data is imported, and then they are persisted permanently after import.
Neo4j ETL also provides a visual editor to transform relational data into graph data.
Data lake integrator
Data lakes struggle to derive value from their accumulated data. While it’s easy to fill the data lake, wrangling its contents, adding context and delivering it to analytical and operational use cases remains an IT challenge. Transforming that data to reveal and traverse its connectedness is all but impossible.
The Neo4j Data Lake Integrator surfaces value submerged in data lakes by making it possible to read, interpret and prepare data as both in-memory and persisted graphs for use in real-time transactional applications and graph analytic exercises within the Graph Platform. The Data Lake Integrator can help enterprises:
- Build metadata catalogs: Discover definitions of data objects and their relationships with each other to weave a highly connected view of information in the data lake. The resulting metadata graph will help data exploration, impact analysis and compliance initiatives.
- Wrangle data: Combine data from the lake with other sources including Neo4j, wrangling it with Cypher – the SQL for graphs. Composable queries allow Cypher queries to return data in an in-memory graph format using Apache Spark™, as well as in tabular or CSV formats.
- Conduct graph analytics: Import data directly from the data lake into the Neo4j Graph Platform for faster and intuitive graph analytics using graph algorithms such as PageRank, community detection and path finding to discover new insights.
- Operationalize data: Import data directly from the data lake into the Neo4j Graph Platform for real-time transactional and traversal applications.
- Snapshot graphs: The output of the Data Lake Integrator is a properly structured CSV for reconstituting Neo4j graphs. These files can be saved as snapshots, versioned, diffed, reused and backed up in HDFS.
Discovery and graph visualization
Finally, the Graph Platform is also able to reach business analysts and users via our collection of partners like Linkurious, Tom Sawyer Software, Tableau, Jet Brains and KeyLines. We also have the Neo4j Browser and our in-house professional services team to help construct custom visualizations.

We hope you enjoy the Neo4j Graph Platform and look forward to our investment in it.
–Jeff Morris,
on behalf of the entire Neo4j team
Download Neo4j 3.3 – along with other parts of the platform – find out for yourself why it’s the #1 platform for connected data.
Share Article



Explore
Related Articles

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks

A workbench for teams to query, explore, and visualize graph data

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI
