

Neo4j Integrates Into Your Data Ecosystem with Connectors

Senior Director of Product Marketing
5 min read
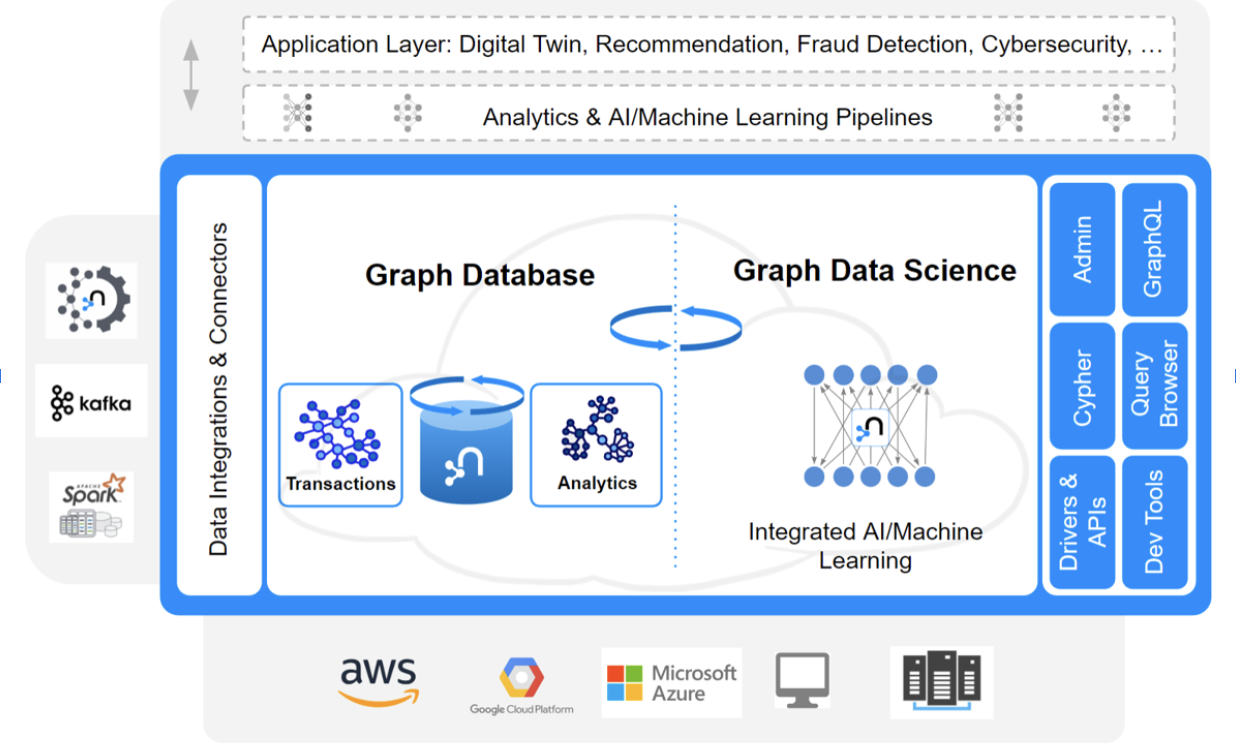
Neo4j’s graph platform is unique compared to traditional relational databases (RDBMS) and NoSQL datastores because it prioritizes connections between data points, called relationships, as first-class citizens. Relationships are just as easy to access and just as important as the data points, or nodes, they connect. This enables not only better performance and more expressive queries, but also adds an additional dimension of understanding for data scientists.
With Neo4j, data scientists can easily see patterns and identifiers that might be hidden in other types of data stores. Additionally, because Neo4j is a scalable platform, organizations can start small and grow their graph as their needs expand. For these reasons and more, Neo4j is the perfect platform for organizations who want to make the most of their data.
Heterogeneous Data Ecosystems
The modern data stack is not a monolith, consisting of a single data management system. Instead, developers and data scientists leverage many different technologies, each best suited for specific tasks: different types of databases, data warehouses, and data lakes, knit together with powerful ETL tools.
In order for Neo4j to be a part of this landscape, it is essential to be able to efficiently import and export data. ETL – exporting data from Neo4j as a transactional database and preparing it for downstream data warehouses – and reverse ETL – importing data into Neo4j for specialized analysis of connected data, and then returning those insights to a data lake or warehouse. Minimizing friction around data movement can greatly enhance the adoption of graph technology – and empower users to gain even more insight from graphs.
Data exchange between databases, data lakes, data warehouses, and applications often follows standardized architectures:
-
- Streaming processes, like Apache Kafka and Apache Beam, which stream data in real time from source applications to data sinks (e.g., a database or data warehouse)
- Batch processes, like Apache Spark jobs, where large volumes of data are moved from data warehouses, typically using map-reduce frameworks to aggregate and transform big data sets
- Driver based processes, where applications can connect to databases to execute specific queries (e.g., ODBC, JDBC)
Below, I’ll cover how Neo4j offers connectors and drivers for each of these applications.
Neo4j Connectors
Neo4j provides multiple connectors and drivers that allow easy data integration for the three different concepts we described above.
-
- Streaming: Our Kafka connector allows easy integration into Event Driven Architectures by using a commonly used platform, Apache Kafka, as a message broker for bi-directional data exchange.
- Batch: Spark and our new Enterprise Data Warehouse (DWH) connectors allow bi-directional batch data transfer.
- Drivers: BI (JDBC) Connector, in addition to our language drivers (Python, Java, Javascript, Go, .NET).
Our drivers are primarily intended for application developers, while our BI connector is built for generic applications, like Tableau, to simplify connectivity.
Let’s take a deeper dive into each connector and its capabilities.
Neo4j Kafka Connector
The Neo4j Kafka Connect connector is based on the Apache Kafka Connect framework and allows the bi-directional data flow for Neo4j as a source as well as sink. When used as a source, it periodically queries Neo4j through customized queries to produce messages representing change records of a topic on a Apache Kafka message broker. It allows the user to adapt the queries to the scope and filter that solve the problem encountered.
When used as a sink, the Neo4j Kafka connector is a consumer of a topic from an Apache Kafka broker and each message received triggers a custom query in the Neo4j database that executes the intended data change.
Since there are a lot of databases, data warehouses, and data lakes that have similar connectors to Kafka, it is a plug and play solution when integrating Neo4j into an existing system architecture.
This technology allows integration through common reliable architecture patterns like ETL, but also the currently very popular Event Driven Architecture pattern. For this connector, Neo4j can be either the data sink, allowing data to be continuously imported into Neo4j, or data source, allowing the continuous export of data.
Summarizing, the Neo4j Kafka connector has the following features:
-
- Exchange of data records
- Bi-directional dataflow
- Customisable queries
- Optimized for single record exchange
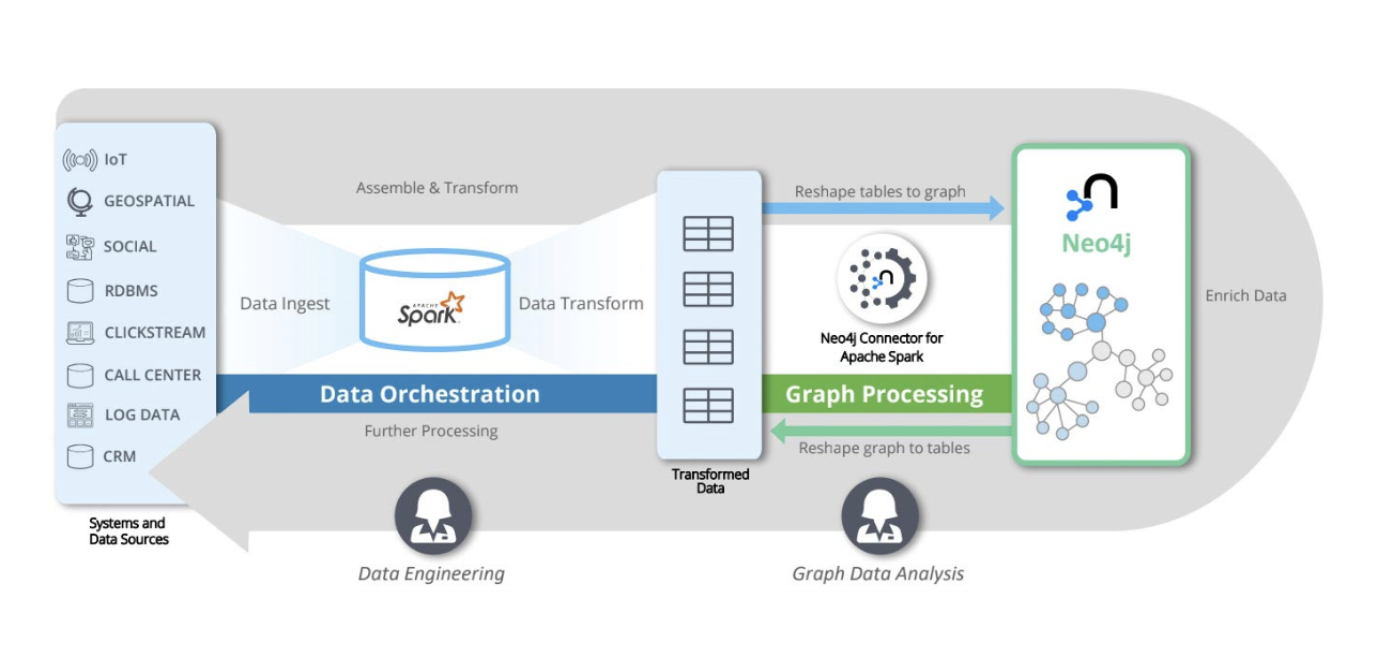
Neo4j Spark Connector
The Neo4j Spark connector enables efficient batch processing between Apache Spark data frames and graphs using Spark jobs, a popular framework for large-scale, distributed, data processing.
With the Neo4j Spark Connector, you can read from and write to Neo4j using a simple API you are already familiar with in either Scala Spark or PySpark.
You can leverage the connector wherever you’re running Spark. It’s simple to use the connector in notebooks and Spark submit jobs on managed Spark services, such as DataBricks, or directly in your own environment.
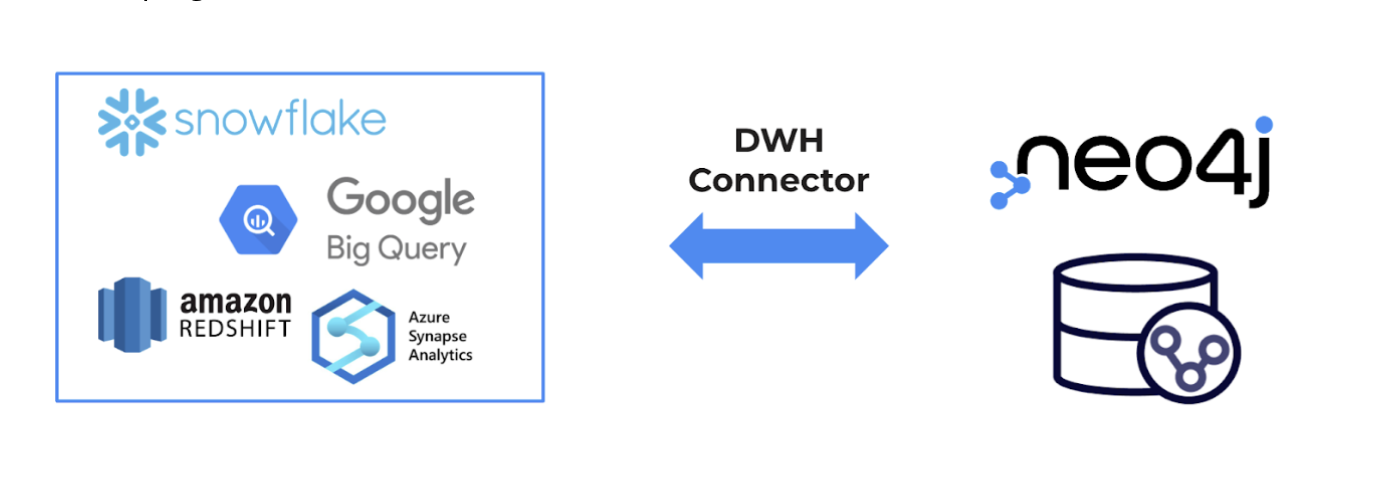
🆕 Neo4j Data Warehouse Connector
As announced at GraphConnect 2022, we have added the Neo4j Data Warehouse Connector to our portfolio of connectors. This new connector provides a simple way to move data between data warehouse tables and graphs.
Specifically, the Neo4j Data Warehouse Connector provides convenience and flexibility for moving data between Neo4j and popular Data Warehouses like Snowflake, BigQuery, Amazon Redshift, and Microsoft Azure Synapse Analytics.
There are two ways to use the Data Warehouse connector to move data:
-
- Configure a Spark Submit job by providing a JSON configuration.
- Use the Pyspark or Scala Spark API to configure the job in a notebook or other program.
Neo4j BI Connector
Neo4j provides the BI connector in order to allow data users to visualize or combine data from multiple databases in common business intelligence tools like Tableau or Power-BI. The BI connector enables data from graph projects to be used for further enriching insights brought from data accessed by BI tools in organizations.
This connector is read-only and is available in two different versions – JDBC and ODBC – to allow data users to connect any data tools that use either SQL over JDBC or ODBC to access the data from Neo4j databases.
In summary, the Neo4j BI connector has the following features:
-
- SQL Queries via JDBC/ODBC
- Read-only from Neo4j database
- Used for BI tools to combine and visualize data from multiple databases

Example Fraud Analytics Use Case
Conclusion
Neo4j provides connectors that allow Neo4j to integrate into a variety of heterogeneous database environments. The Neo4j connectors provide plug and play integrations using the most commonly used data exchange concepts to allow adoption in a large number of use cases.
Please look out for more detailed information diving into particular aspects in the upcoming technical blogs.
What are you waiting for? Get started with connectors today.
Share Article



Explore
Related Articles


From Cafeteria Cliques to Graph Communities: Understanding the Louvain Algorithm
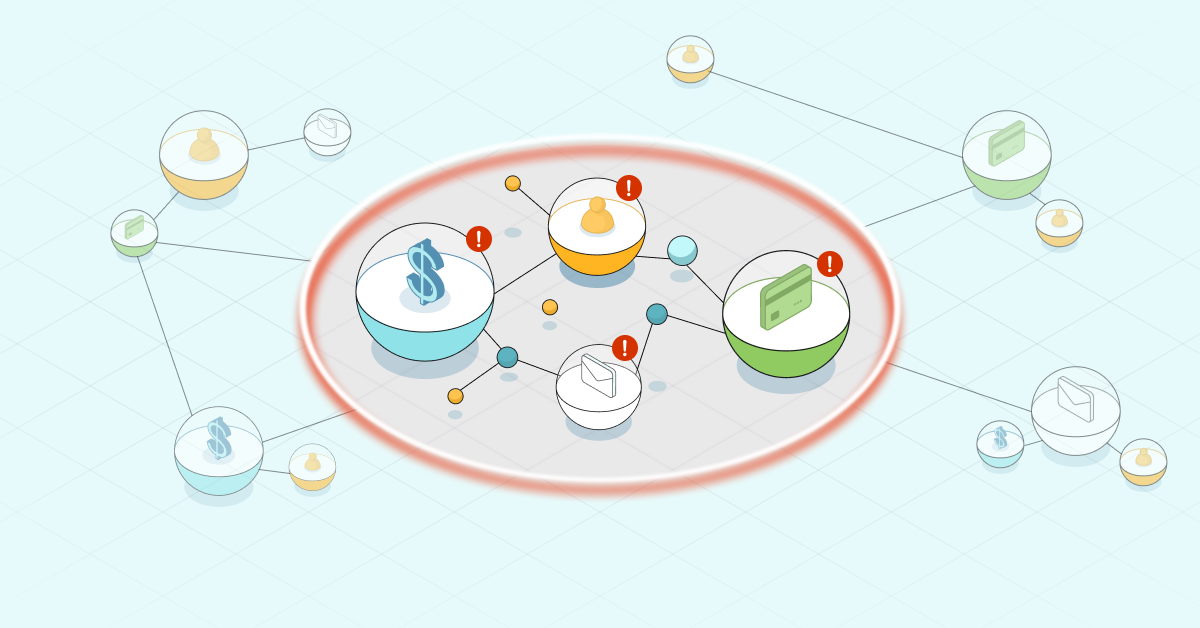
Detect Fraud Faster With a Transaction Graph


