
The Neo4j JDBC Driver 3.3.1 Release Is Here [+ Examples]

Founder & CEO, LARUS Business Automation
6 min read
Our team at LARUS has been quite busy since the last JDBC driver release. Today, we’re happy to announce the 3.3.1 release of the Neo4j-JDBC driver.
The release has been upgraded to work with recent Neo4j 3.3.x versions and Bolt driver 1.4.6. (Work on Neo4j 3.4.x and drivers 1.6.x is in progress.)
Neo4j-JDBC Driver Improvements and Upgrades
We worked on a number of improvements:
- Added Bolt+routing protocol to let the driver work with the cluster and being able to route transactions to available cluster members.
- Added support for in-memory databases for testing and embedded use cases.
- Added a debug feature to better support the development phase or inspect how the driver works when used by third-party tools.
- Added support for TrustStrategy so that you can now configure how the driver determines if it can trust the encryption certificates provided by the Neo4j instance it is connected to.
- Implemented the DataSource interface so that you can now register the driver with a naming service based on the Java Naming and Directory Interface (JNDI) API and get a connection via JNDI lookups.
- PLEASE NOTE: We’ve deprecated the usage of
,as the parameter separator in favour of&to be compliant with the URL parameter syntax. Please update your connection URL because in future releases we’ll manage just&. (In the future, we want to use,for parameters that can have a list of values).
Updated Documentation + Matlab Example
The documentation has been updated to explain how to use the new features and now includes a Matlab example.
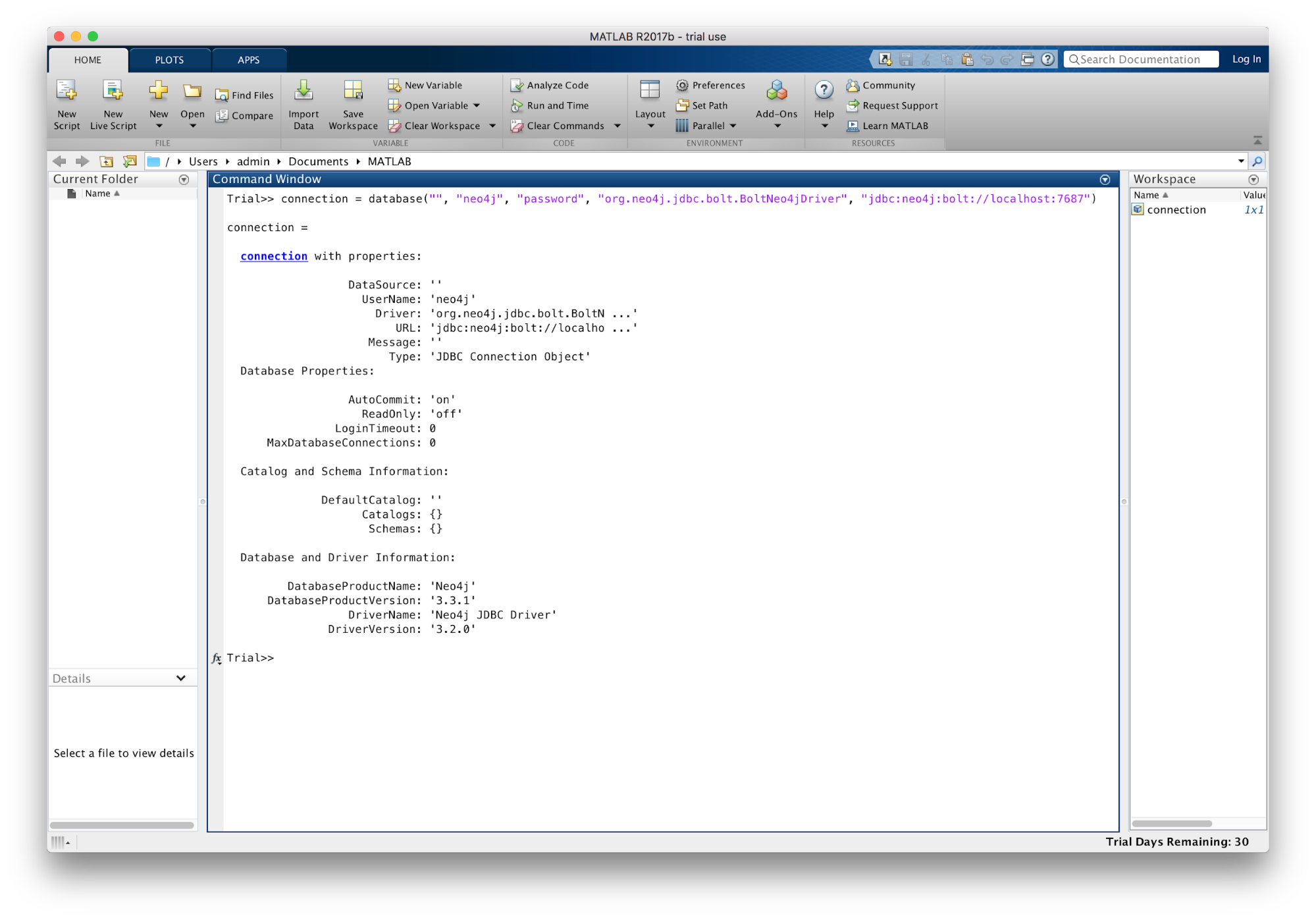
Open connection:
conn = database('','neo4j','test','org.neo4j.jdbc.BoltNeo4jDriver',
'jdbc:neo4j:bolt://localhost:7687')
Fetch Total Node Count:
curs = exec(conn,'MATCH (n) RETURN count(*)') curs = fetch(curs); curs.Data close(curs)
Output:
ans = '102671'
Besides Matlab, Neo4j-JDBC can of course be used with many other tools. Here is a short list:
- Squirrel SQL
- Eclipse / BIRT
- Jasper Reports
- RapidMiner Studio
- Pentaho Kettle
- Streamsets
API / Interface Work for JDBC Compatibility
We implemented the DataSource interface so that you can now register the driver with a naming service based on the Java Naming and Directory Interface (JNDI) API and get a connection via JNDI lookups. This should help a lot when you need a server managed connection to Neo4j in a JEE environment.
We also added implementations for several methods in Driver, Connection, Statement, ResultSet that were not there previously.
This helps you use the Neo4j-JDBC driver with MyBatis and other frameworks, like Spring JDBC.
Introducing New Support for Causal Clustering
It’s not always easy to adapt the brand-new Neo4j features and protocols to an old-fashioned interface such as the Java Database Connectivity (JDBC). This is because the capabilities of Neo4j Clusters and the Neo4j Java Bolt driver are evolving very rapidly.
Our latest task at LARUS was to make the Neo4j-JDBC driver interact with a Neo4j Causal Cluster providing all the client-side clustering features supported by the Bolt driver:
- The possibility to route reads and writes to the server with the correct role
- Defining a routing context
- Managing bookmarks for causal consistency
- Supporting multiple bootstrap servers
We’re very happy to present what we’ve been able to achieve!
Bolt+Routing Protocol
If you’re connecting to a Neo4j Causal Cluster and you want to manage routing strategies the JDBC URL must have this format:
jdbc:neo4j:bolt+routing://host1:port1,host2:port2,…,
hostN:portN/?username=neo4j,password=xxxx
You might have noticed we introduced the new protocol jdbc:neo4j:bolt+routing which indeed allows you to create a routing driver.
The list of [host:port] pairs in the URL correspond to the list of servers that are participating as Core instances in the Neo4j Cluster. If you or your preferred tool doesn’t support this format you can fall back to the dedicated parameter routing:servers, as in the following example:
jdbc:neo4j:bolt+routing://host1:port1?username=neo4j,password=xxxx,
routing:region=EU&country=Italy&routing:servers=host2:port2;…;hostN:portN
In that case, the address in the URL must be that of a Core server and the alternative servers must be ; separated (instead of ,).
Routing Context
Routing driver with routing context is an available option with a Neo4j Causal Cluster of version 3.2 or above. In such a setup, you can include a preferred routing context via the routing:policy parameter.
jdbc:neo4j:bolt+routing://host1:port1,host2:port2,…,
hostN:portN?username=neo4j,password=xxxx,routing:policy=EU
While for custom routing strategies you can use the generic routing: parameter:
jdbc:neo4j:bolt+routing://host1:port1,host2:port2,…,
hostN:portN?username=neo4j,password=xxxx,routing:region=EU&country=Italy
Access Mode (READ, WRITE)
Transactions can be executed in either read or write mode (see access mode), which is a really useful feature to support in JDBC too. The user can start a transaction in read or write mode via the Connection#setReadOnly method.
Note: Beware not to invoke that method while a transaction is currently open. If you do, the driver will raise an SQLException.
By using this method, when accessing the Neo4j Causal Cluster, write operations will be forwarded to Core instances while read operations will be managed by all cluster instances (depending on routing configuration).
You can find an example after the next paragraph.
Bookmarks
When working with a Causal Cluster, causal chaining is carried out by passing bookmarks between transactions in a session (see “causal chaining” in the Neo4j docs).
The JDBC driver allows you to read bookmarks by calling the following method:
connection.getClientInfo(BoltRoutingNeo4jDriver.BOOKMARK);
Of course, you can set the bookmark by calling the corresponding method:
connection.setClientInfo(BoltRoutingNeo4jDriver.BOOKMARK, "my bookmark");
Bolt+Routing with Bookmark Example
Run query:
String connectionUrl =
"jdbc:neo4j:bolt+routing://localhost:17681,localhost:17682,
localhost:17683,localhost:17684,localhost:17685,localhost:17686,
localhost:17687?noSsl&routing:policy=EU";
try (Connection connection =
DriverManager.getConnection(connectionUrl, "neo4j", password)) {
connection.setAutoCommit(false);
// Access to CORE instances, as the connection is opened by
// default in write mode (connection.setReadOnly(false))
try (Statement statement = connection.createStatement()) {
statement.execute("CREATE (:Person {name: 'Anna'})");
}
// closing transaction before changing access mode
connection.commit();
// printing the transaction bookmark
String bookmark = connection.getClientInfo(
BoltRoutingNeo4jDriver.BOOKMARK);
System.out.println(bookmark);
// Switching to read-only mode to access all cluster instances
connection.setReadOnly(true);
try (Statement statement = connection.createStatement()) {
try (ResultSet resultSet = statement.executeQuery(
"MATCH (p:Person {name:'Anna'}) RETURN count(*) AS total")) {
if (resultSet.next()) {
Long total = resultSet.getLong("total");
assertEquals(1, total);
}
}
}
connection.commit();
}
Thanks to the bookmark, we of course expect that the total number of Person nodes returned is 1 (given an empty database), even if we are switching from a Core node – where we perform the CREATE operation – to some instance in the cluster, where instead we’ve performed the MATCH operation.
Usage
We really hope you enjoyed our work, and we’d love to hear from you, not just about issues, but also how you use the JDBC driver in your projects or which tools you use that we haven’t mentioned.
If you want to use the Neo4j-JDBC driver in your application, you can depend on org.neo4j:neo4j-jdcb:3.3.1 in your build setup, while for use with standalone tools it’s best to grab the release from GitHub.
Enjoy!
–Lorenzo
Share Article



Explore
Related Articles


Neo4j Graph Analytics for Snowflake: Bringing Graph-Powered Insights to the AI Data Cloud



Introducing Neo4j Aura Graph Analytics: Scalable, Easy-to-Deploy Graph Analytics for Any Data Source
