Ontologies in Neo4j: Semantics and knowledge graphs

AI Field CTO, Neo4j
13 min read

Editor’s Note: This presentation was given by Jesús Barrasa at GraphConnect New York City in September 2018.
Presentation summary
Jesús Barrasa is the director of Telecom Solutions with Neo4j. In today’s talk, he speaks from his background in semantic technologies.
Barrasa starts with a brief introduction to ontology. Ontology is a form of representing knowledge in a domain model. Ontology is an umbrella term that could also represent knowledge representation and reasoning (KR), natural language, machine or automated learning, speech, vision, robotics and problem solving. These all fall under the ontology umbrella.
Knowledge representation is the idea to make ones data smarter in a way that you are able to move some of the application logic out of it and make data. An example of knowledge presentation would be publishing structured data, self-described data or data described in terms of well defined semantics as opposed to natural language text.
Barrasa give an example of ontology using a fragment of the FIBO ontology. The FIBO ontology fragment describes a number of finance terms and relationships. Barrasa also gives an example of ontology using schema.org which compares to a Google search.
In Neo4j, there are two main uses of ontologies. Interoperability is the definition of shared vocabulary. Another use is inferencing which is actionable knowledge of fragments.
Finally, Barrasa shares a video example of ontologies and graphs using Neo4j and NeoSemantics.
Full presentation
I am Jesús Barrasa. I am the Director of Telecom Solutions with Neo4j. However, today I’m wearing a different hat. I’m wearing my semantic technologies expert hat. In a previous life, I did my Ph.D in the semantic technologies area and then spent seven years in the telecom industry. I particularly focused on using RDF and ontologies to solve real world problems.
Today I want to talk about ontologies and how we use them with Neo4j.
A brief introduction
I’ll still do a brief introduction for those of you who are unfamiliar with ontology. Right now, I am in a cool room because it is an AI. AI is the topic of the year but lately, AI tends to be seen as a synonym of machine learning and that’s not the case.
I’ve enumerated some of the disciplines that fall under AI.

You have robotics, natural language, understanding generation speech, vision and automated learning. There’s machine learning, but there is also knowledge representation and reasoning which is the area I’m going to be talking about.
If you want the other end of the spectrum of machine learning, one of the problems is that we have a neural network that produces a fantastic model that is able to tell if this picture is a biscuit or is a dog. We can’t explain why. It just works. This is a black box problem.
At the other end of the spectrum under the AI umbrella, is knowledge representation. This is where we will try to make reasoning explicit. We will try to explain what we know and how do we run these inferences. It’s what we call more explainable AI. That’s where we are and that’s where ontologies fit.
Knowledge Representation
What’s the rationale behind knowledge representation? Well here is a very simplified view.
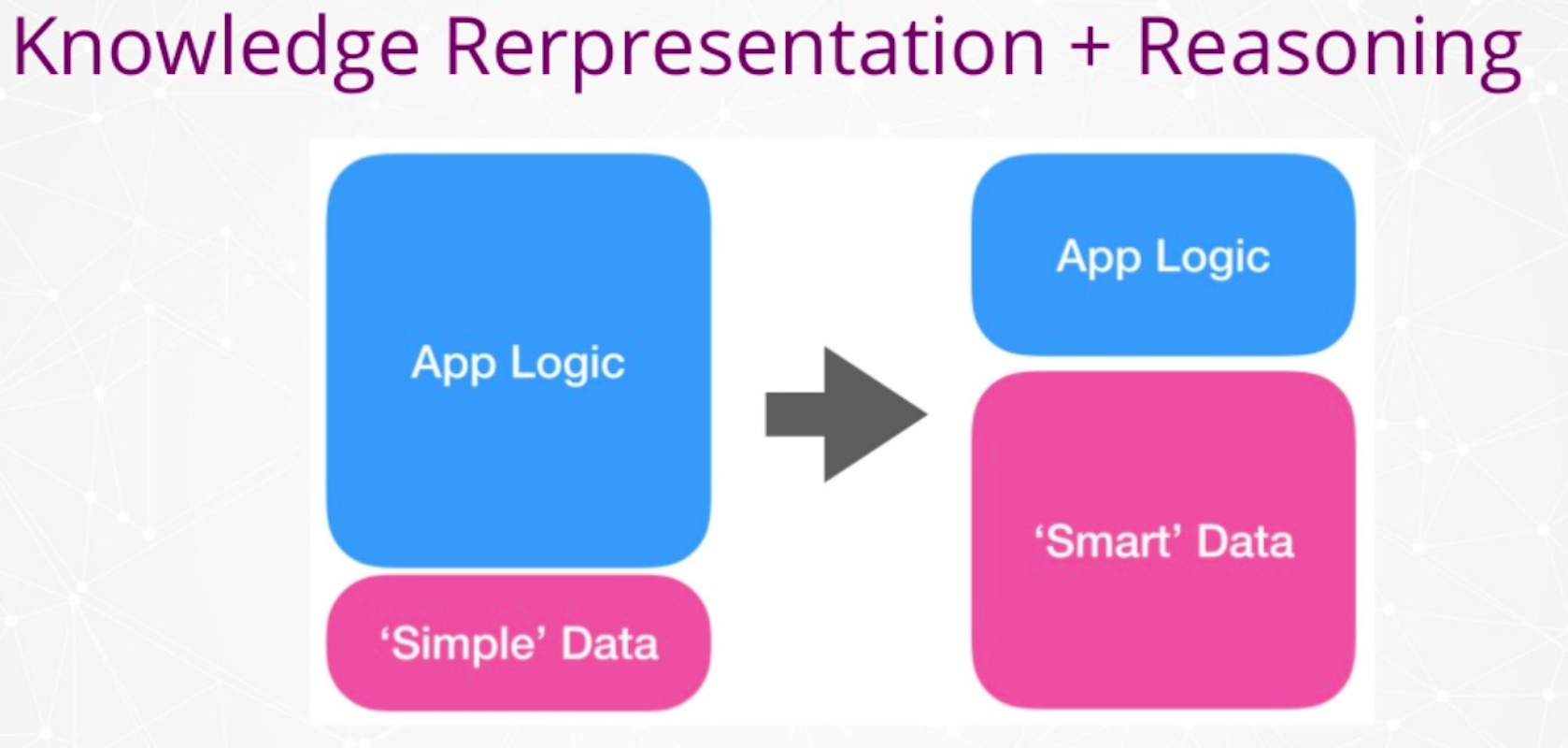
In any solution, you will find your application logic being a fat component and your data tends to be simple data.
The idea with knowledge representation is to make your data smarter in a way that you are able to move some of the application logic out of it and make it data. By doing that, you reuse knowledge that you don’t have to replicate in any application. You make it explicit.
There’s a number of benefits and a great example of this idea of knowledge representation and reasoning that Tim Berners Lee shared about the Semantic Web. If you remember, the web at the time was purely for human consumption. The data published was pretty dumb, it was text. What you had at the other end was a client not an application. At the other end was a human that needed to be able to understand that text.
Proponents of the Semantic Web suggested instead of publishing a natural language text, to publish better structured data, self describing data, data described in terms of well defined semantics. They wanted smarter data that we could do smarter things with. Now, we have general purpose applications that use that knowledge. That became quite popular in the early 2000s.
What is ontology?
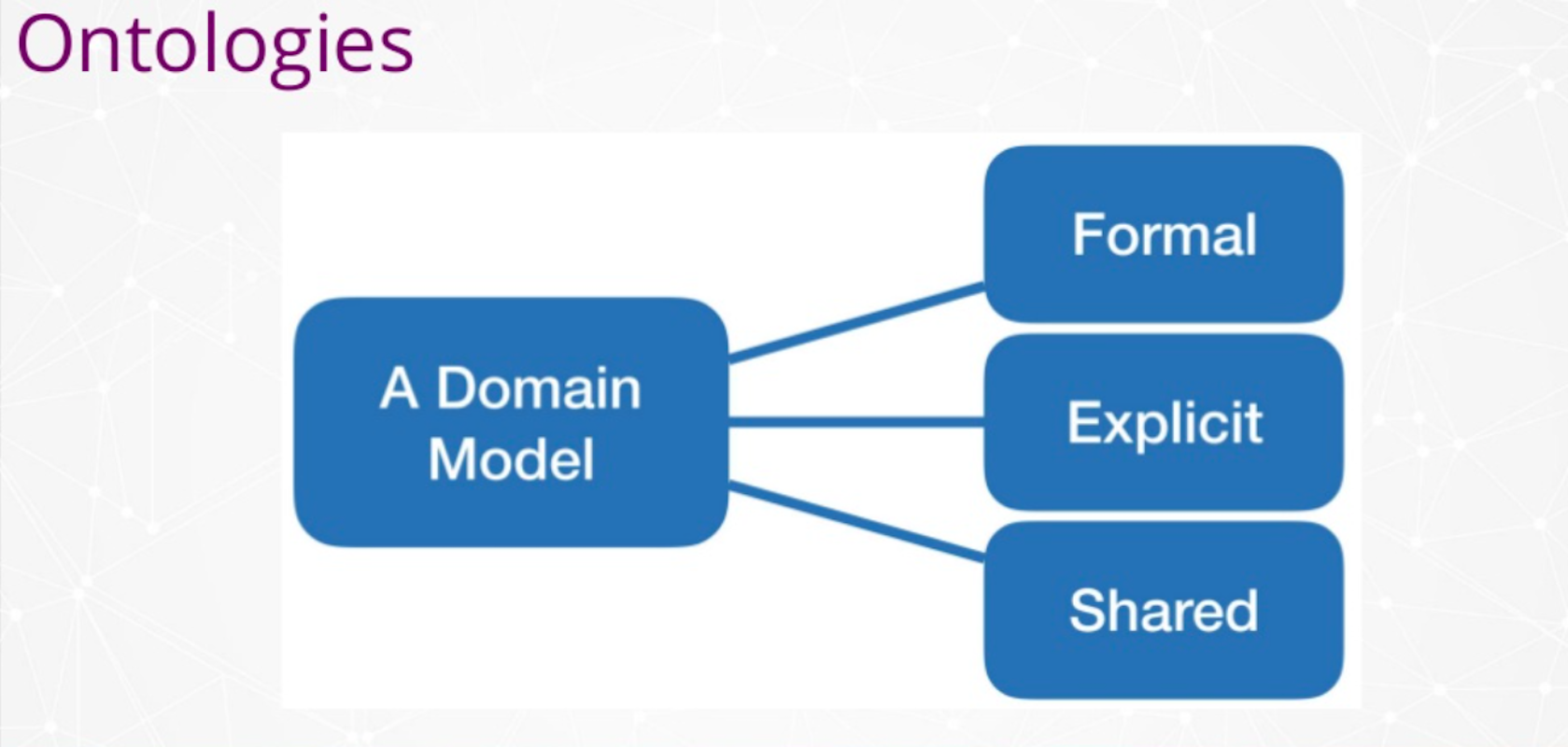
An ontology is a form of representing knowledge in a domain model. It’s a representation of a particular domain. However, it has three characteristics that make it a bit different and a bit particular. We build models for many things, we create models when we are going to create a database. We create entity relationship models, we create models when using modeling tools, we create models when we write something on a white board. An ontology needs to have these three characteristics.
The first characteristic of an ontology is it has to be a formal representation. It has to be machine readable, that’s a key point. It has to have some structured form.
The second characteristic is the ontology is an explicit description of a domain. It’s not like a natural language text description it has to be an enumeration of the entities that belong to these domain and how they relate to each other. I’m talking about entities connected to other entities. That sounds a lot like a graph, doesn’t it? Most of the modeling languages used for ontologies, are based on RDF which is actually a graph model. The description being explicit is very important.
The third characteristic is the notion of consensuated knowledge, it’s a shared vocabulary. This vocabulary is typically shared by a community. You could create an ontology and use it just for yourself, but most of the popular ones, and the ones that I’m going to be showing today are shared ontologies which include agreed vocabularies that are shared by communities.
An example of ontology

The above image is a fragment of the FIBO ontology. If you are in the finance industry, you might be familiar with it. The fragment describes a number of finance terms and relationships. You see that it is XML based. It’s using the old WL language and you are able to see things like at the top. Class description is a category and it describes what a privately held company is.
We see that there are some synonyms like a closed corporation, a privately held corporation, but more interestingly there’s things like sub-class of statements. A privately held company is a sub-class of a stock corporation. That bit of knowledge is going to be useful in a minute.
We’re making our knowledge explicit. It’s a formal description. We’re making it explicit because then there’s also a description of the stock corporation and that is something that’s governed by board agreement. Stock corporations have a date of incorporation so it’s a formal description of all the elements in that particular domain, and it’s shared. It’s governed by the EDM council, is a shared vocabulary and it’s quite widely used.
Schema.org
Another good example of ontologies is schema.org.

You are all familiar with the knowledge graph. Google is a knowledge graph and when you do a search, if there’s a match with a concept, you will see a description like above.
This the human readable version of it. If you do a search for these album by Miles Davis, you see that you have the title, a description and you have the artist. The results include a number of elements, and that’s described according to the Schema.org ontology.
What you have here is not an ontology definition. It is a fragment of content annotated according to that particular ontology.
Below, we are describing this as an album.
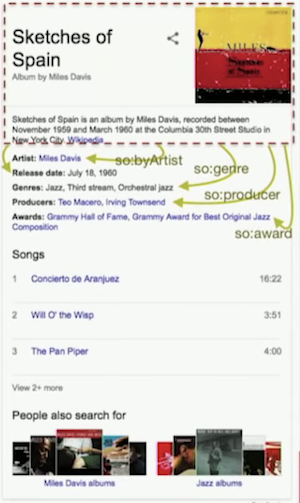
The album has a name, it has a description, a genre and it’s connected to an artist and to other elements.
Ontologies are out there and they’re being used. I was thinking, I want to benefit from that. I have my data in Neo4j, but I want to use ontologies as well.
Knowledge graph fundamentals
Stop missing hidden patterns in your connected data. Learn graph data modeling, querying techniques, and proven use cases to build more resilient and intelligent applications.
Ontologies and Neo4j
In Neo4j, there’s two main uses of ontologies.

The first use of ontologies is interoperability. If it’s a shared vocabulary, if I share my data, if I expose my data according to that vocabulary, people are going to be able to use it and understand it because there’s a formal definition for it. People are going to be able to define or construct applications that consume that data. Interoperability and RDF are at the core of the whole Semantic Web concept.

The second use is inferencing. An ontology includes fragments of knowledge that I use to run inferences. An inference is being able to infer new knowledge out of the knowledge that I have. I have data in a graph database and I want to derive new facts out of it, I’m going to be able to use ontologies to do that.

I have my data in Neo4j as a graph. I want to expose the data as RDF, and expose it according to un-standard vocabulary. I’m going to use Schema.org.
What does that look like from the architecture, what are the elements involved? First, we have Neo4j as the data store and I’m going to use an extension that I’ve been working on and I’ve actively developed called NeoSemantics.
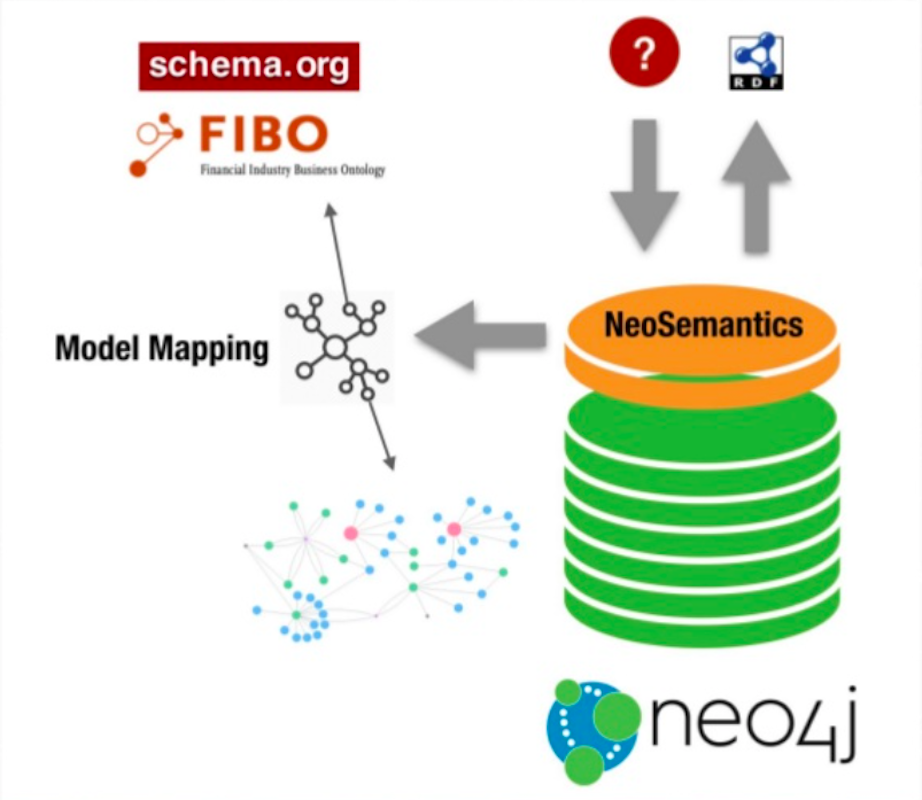
We have a number of components that will make it possible to ingest and publish RDF with two software elements. I want is to expose my data from Neo4j as RDF according to one of these vocabularies and migrate it out.
I want to get my answers on the fly. I’m going to define a mapping that matches my data to the public ontologies. I’m going to use the finance extension of schema.org, which takes concepts from FIBO.
My plan is to then run a query on my Neo4j through that extension, a query in Cypher, or an http request. I want this component to map the results of my query to that vocabulary and expose it as RDF. I’m going to use the financial extension of schema.org and I’m going to use the new semantic extension.
After that, I’m going to show you how we use that information and how we use that ontology to run some basic inferences.
Video example
Let’s get started.
We open Neo4j.
These are loans over $30,000 in the state of New York. We set a limit to show just three of them.

That’s what the model looks like. We have a note representing the loan and the borrower. It’s anonymized data, so we’ll have a unique identifier and a connection to a zip code. The zip code will be connected to a state.
To expose some of that data as RDF, I’m going to use the browser to send a GET request to the extension. The only parameter I’m passing to the semantic extension is an ID of a loan. If I run this, we’re going to get an RDF representation.

If you’re familiar with RDF, this is a turtle serialization of the data in my graph. I get all the properties, all the attributes of my loan, the connection to the borrower and the connection to the state. That’s plain mapping to RDF.
What I want to do now is to be able to define a mapping. I’m going to define a namespace, link to the vocabulary that I’m going to use, and link to a number of key value pairs.

I’m saying this property in my graph corresponds to this property in the schema.org. This category or label corresponds to these other categories.
I have a mapping now and I am going to rerun the request to the transactional endpoint. You see elements that I’ve mapped, are now described according to their schema of ontology. This transformation is done in real time.
You could use these as a way of exposing just a portion of my data. If a have a parameter where I am only showing the map data I could show just a portion of my data thats mapped to the ontology. It would be exactly the same information but only exposing the elements in the schema, or the ontology.
The idea is that we have a graph and we want to map it to a graph. It simplifies a lot of the tasks of defining that mapping. You could run Cypher and expose bigger parts of your model but the second part is about inference and that’s an import one. The idea is, I want to import an ontology now, bring the ontology into the graph and use it to run the inferences.
I could stream the data from an ontology and I will get something like schema.org. I could take the information from these graphs, put them into Neo4j and create a model. That’s what I’ve done.
I have a copy of the schema.org ontology represented as nodes, I have labels there and the labels are connected through sublabel of. Below is a simplified view of the ontology.
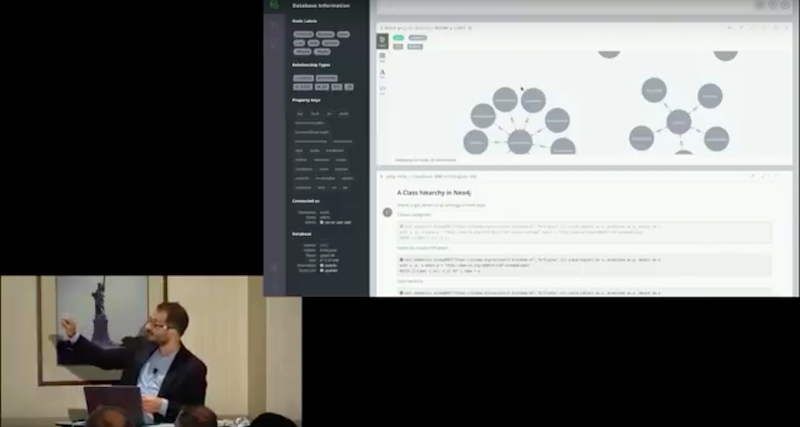
The idea is, I now have a representation of the ontology in Neo4j and I am going to use it to run some inferences. What I could do is hook my model which contains loans to the ontology. I am going to create a new entity for my ontology, that’s loan, and I’m going to say that it is a subclass of the loan concept in the schema.org ontology.
I am going to say “Okay, give me all the financial products in the database.” As you know, there is no mention anywhere in the database of the loan being a financial product. However, I run these requests and I will get these loans because loans have been described as subcategory of financial product in the schema.org ontology.
These were just a few of the many uses you find implementing ontologies and graphs into your artificial intelligence or machine learning solution.
The developer’s guide
Think knowledge graphs are too complex? They’re easier to build than you think. Learn step-by-step how to connect and organize your data with the relationships intact to query at speed.
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

POLE+O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph

1 of 3: The difference between a graph, a knowledge graph, and a context graph
