Graph databases for beginners: Other graph technologies

Editor-in-Chief, Neo4j
8 min read

Back in the day (when Prussia was still a thing), Königsberg must have been a really boring place.
That’s because the definition of fun in Königsberg was to walk around the city’s seven bridges and find a path that only crossed each bridge once. (This was before Netflix.)
This isn’t that complex of a problem, but the people in Königsberg also weren’t that good at math. So they asked their math “friend” (not their friend), Leonhard Euler to figure it out. Euler had way more important shit to figure out at the time – namely number theory and infinitesimal calculus – so he invented a new type of math for his “friends” (not his friends) to play with.
The moral of the story: We could have understood the fundamental nature of the entire universe by now (and be writing this from Mars), but instead, someone(s) had to ask Euler to invent a new type of math like an annoying child asks their uncle for a balloon animal.
But this is Euler we’re talking about: Even his balloon animals give us profound insights into the nature of reality. And this particular balloon animal is graph theory.
Even after 280 years, graph theory is still powering some of the most innovative tech on the planet: graph database technology.
Because it’s based on such a paradigm-shifting field of mathematics and computer science, graph technology grows and evolves fast. So whether you’re brand-new to the world of graphs or you’re a seasoned vet, it’s time to survey the space.
In this Graph Databases for Beginners blog series, I’ll take you through the basics of graph technology assuming you have little (or no) background in the space. In past weeks, we’ve tackled why graph technology is the future, why connected data matters, the basics (and pitfalls) of data modeling, why a database query language matters, the differences between imperative and declarative query languages, predictive modeling using graph theory, the basics of graph search algorithms, why we need NoSQL databases, the differences between ACID and BASE consistency models and a (brief) tour of aggregate stores.
This week, we’ll be looking at the wide spectrum of graph database technologies and their context within the world of NoSQL.
Quick recap: The NoSQL matrix
The macrocosm of NoSQL databases is a diverse one of which graph databases are only a part. Last week, we toured the three blue quadrants of the matrix below which are collectively known as aggregate stores, including key-value, wide-column (or column family) and document stores.
This week, we’ll be double-clicking on the equally diverse world of graph technology which occupies the green quadrant in the matrix below.
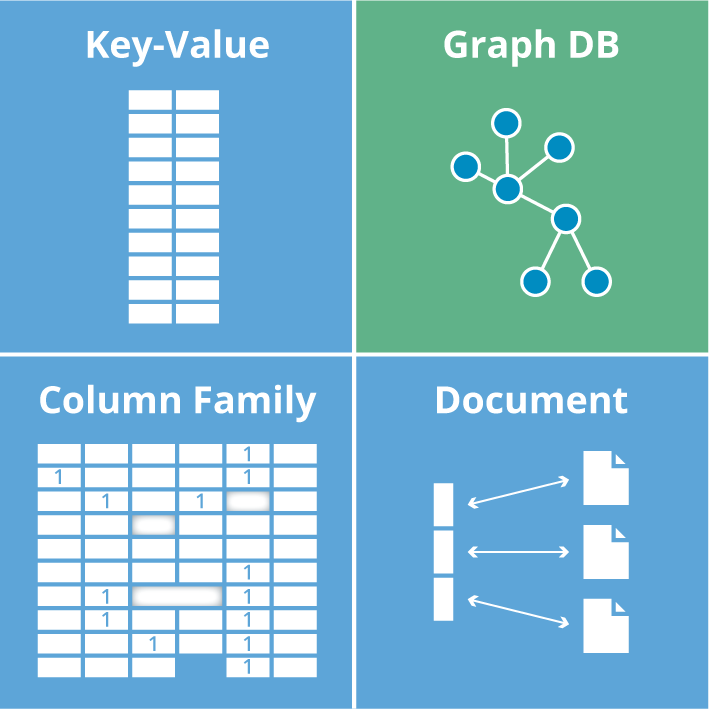
The matrix of NoSQL databases. Quadrants in blue are collectively known as aggregate stores.
The spectrum of graph database technologies
We already walked through a formal definition of a graph database in our first post, but let’s do a quick review.
A graph database is an online, operational database management system capable of Create, Read, Update, and Delete (CRUD) processes that operate on a graph data model.
There are two important properties of graph database technologies:
- Graph storage
- Graph processing engine
Some graph databases use native graph storage that is specifically designed to store and manage graphs, while others use relational or object-oriented databases which are often slower ( due to the data model mismatch).
Native graph processing (i.e., index-free adjacency) is the most efficient means of processing data in a graph because connected nodes physically “point” to each other in the database. Non-native graph processing engines use other means to process CRUD operations.
Besides specifics around storage and processing, graph databases also adopt distinct data models. The most common graph data models include property graphs, hypergraphs and RDF triples.
Let’s dive into each of these below.
Property graphs
Property graphs are the type of graph database we’ve already talked about most. In fact, our original definition of a graph database was more precisely about a property graph (pictured below).
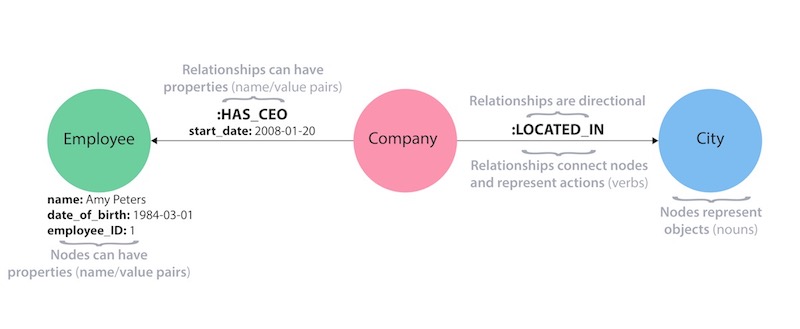
Here’s a quick recap of what makes a data model a property graph:
- Property graphs contain nodes (data entities) and relationships (data connections).
- Nodes can contain properties (i.e., key-value pairs).
- Nodes can be labeled with one or more labels.
- Relationships have both names and directions.
- Relationships always have a start node and an end node.
- Like nodes, relationships can also contain properties.
Neo4j is a property graph database.
Hypergraphs
A hypergraph is a graph data model in which a relationship (called a hyperedge) can connect any number of given nodes. While a property graph permits a relationship to have only one start node and one end node, the hypergraph model allows any number of nodes at either end of a relationship.
Hypergraphs can be useful when your data includes a large number of many-to-many relationships.
Let’s look at the example below.
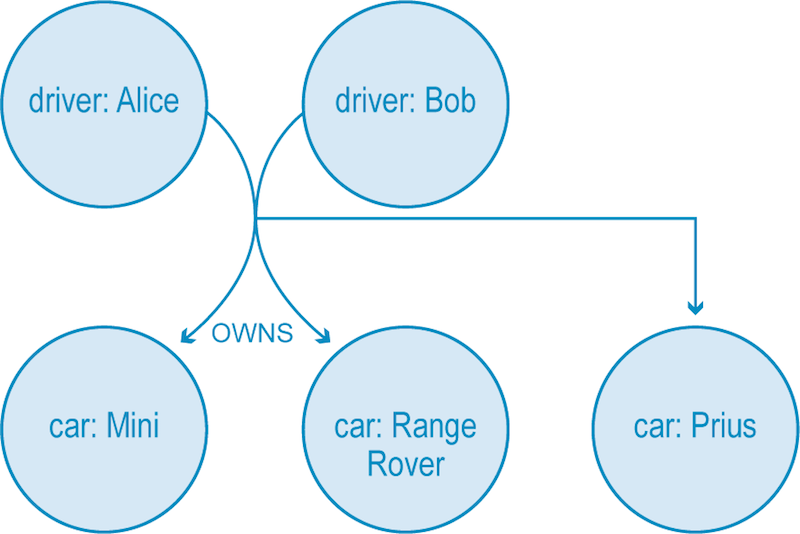
In this simple (directed) hypergraph, we see that Alice and Bob are the owners of three vehicles, but we can express this relationship using a single hyperedge. In a property graph, we would have to use six relationships to express the concept.
In theory, hypergraphs should produce accurate, information-rich data models. However, in practice, it’s very easy for us to miss some detail while modeling. For example, let’s look at the figure below, which is the property graph equivalent of the hypergraph shown above.
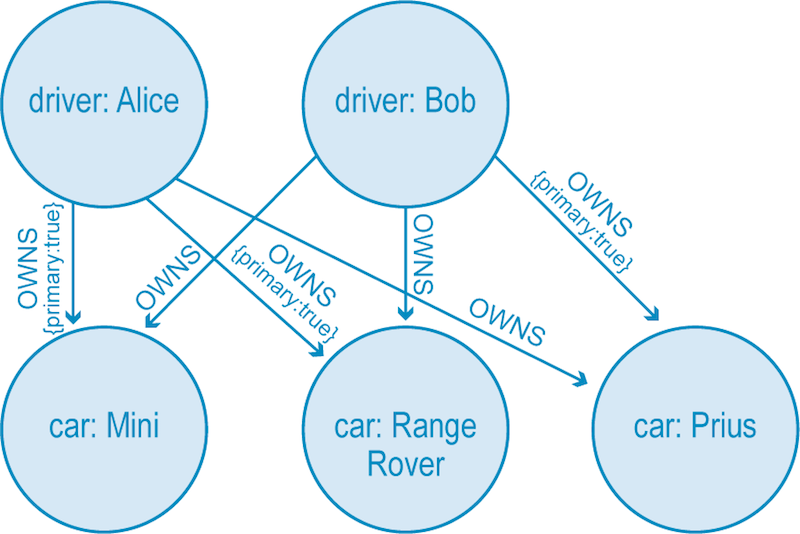
This property graph model requires several OWNS relationships to express what the hypergraph captured with just one hyperedge. Yet, by using six relationships instead of one, we have two distinct advantages:
- First, we’re using a more familiar and explicit data modeling technique (resulting in less confusion for a development team).
- Second, we can also fine-tune the model with properties such as “primary driver” (for insurance purposes), which is something we can’t do with a single hyperedge.
Because hyperedges are multidimensional, hypergraph models are more generalized than property graphs. Yet, the two are isomorphic, so you can always represent a hypergraph as a property graph (albeit with more relationships and nodes) – whereas you can’t do the reverse.
While property graphs are widely considered to have the best balance of pragmatism and modeling efficiency, hypergraphs show their particular strength in capturing meta-intent. For example, if you need to qualify one relationship with another (e.g., I like the fact that you liked that car. Whoa, so meta.), then hypergraphs typically require fewer primitives than property graphs.
Whether a hypergraph or a property graph is best for you depends on your modeling mindset and the kinds of applications you’re building.
Triple stores
Triple stores come from the Semantic Web movement and store data in a format known as a triple. Triples consist of a subject-predicate-object data structure.
Using triples, we can capture facts such as “Ginger dances with Fred” and “Fred likes ice cream.” Individually, single triples aren’t very useful semantically, but en-masse, they provide a rich dataset from which to harvest knowledge and infer connections.
Triple stores are modeled around the Resource Description Framework (RDF) specifications laid out by the W3C, using SPARQL (pronounced “sparkle”) as their query language.
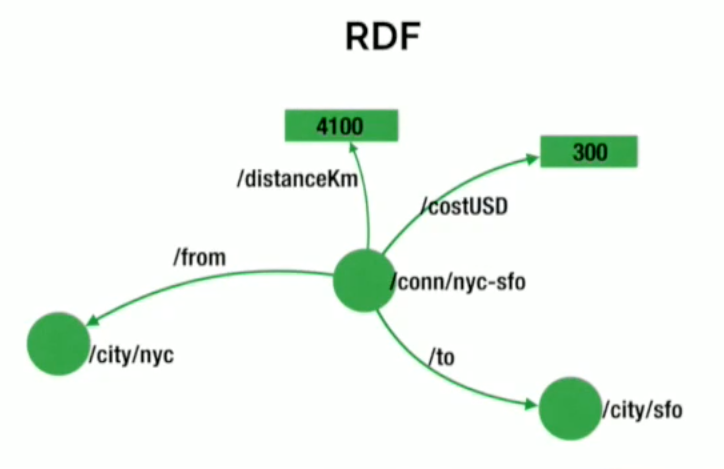
An example of an RDF triple store data model
Data processed by triple stores tends to be logically linked, thus triple stores are included in the category of graph databases. However, triple stores are not native graph databases because they don’t support index-free adjacency, nor are their storage engines optimized for storing property graphs.
Triple stores store triples as independent elements, which allows them to scale horizontally but prevents them from rapidly traversing relationships. In order to perform graph queries, triple stores must create connections from individual, independent facts – adding latency to every query.
Because of these trade-offs in scale and latency, the most common use case for triple stores is offline analytics rather than for online transactions.
Read this article for more information on the difference between RDF triple stores and labeled property graph databases.
Conclusion
Euler would be proud to see what we’ve been able to do with his graph theory balloon-animal (“There, there, little one, that’s very cute.”). That’s because there’s a lot of different graph technologies – we didn’t even get to graph analytics or graph visualization!
Just like we saw last week with aggregate stores, every type of graph database technology is best suited for a different function. Hypergraphs are a good fit for capturing meta-intent and RDF triple stores are proficient at offline analytics. But for online, transactional processing nothing beats a property graph for the rapid traversal of data connections.
Catch up with the rest of the Graph Databases for Beginners series:
- Why Graph Technology Is the Future
- Why Connected Data Matters
- The Basics of Data Modeling
- Data Modeling Pitfalls to Avoid
- Why a Database Query Language Matters (More Than You Think)
- Imperative vs. Declarative Query Languages: What’s the Difference?
- Graph Theory & Predictive Modeling
- Graph Search Algorithm Basics
- Why We Need NoSQL Databases
- ACID vs. BASE Explained
- A (Brief) Tour of Aggregate Stores
- Native vs. Non-Native Graph Technology
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

POLE+O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph

1 of 3: The difference between a graph, a knowledge graph, and a context graph
