
RDBMS & Graphs: Graph Basics for the Relational Developer



6 min read
We already know that relational databases aren’t always enough for handling the volume, velocity and variety of today’s data, but what’s the clear alternative?
There are a lot of other database options out there – including a number of NoSQL data stores – but none of them are explicitly designed to handle and store data relationships. None, that is, except graph databases.
In this RDBMS & Graphs blog series, we’ll explore how relational databases compare to their graph counterparts, including data models, query languages, deployment paradigms and more.
Last week, we discussed why relational databases aren’t always enough for today’s big data challenges. This week, we’ll cover the basics of graph databases from the perspective of an RDBMS developer.
The Case for Graph Databases
The biggest value that graphs bring to the development stack is their ability to store relationships and connections as first-class entities.
For instance, the early adopters of graph technology reimagined their businesses around the value of data relationships. These companies have now become industry leaders: LinkedIn, Google, Facebook and PayPal.
As pioneers in graph technology, each of these enterprises had to build their own graph database from scratch. Fortunately for today’s developers, that’s no longer the case, as graph database technology is now available off the shelf.
Let’s take a further look into why you should consider a graph database for your next connected-data application. We’ll start with some basic definitions.
What Is a Graph?
You don’t need to understand the arcane mathematical wizardry of graph theory in order to understand graph databases. On the contrary, if you’re already familiar with relational databases, you’ll find graphs to be a breeze.
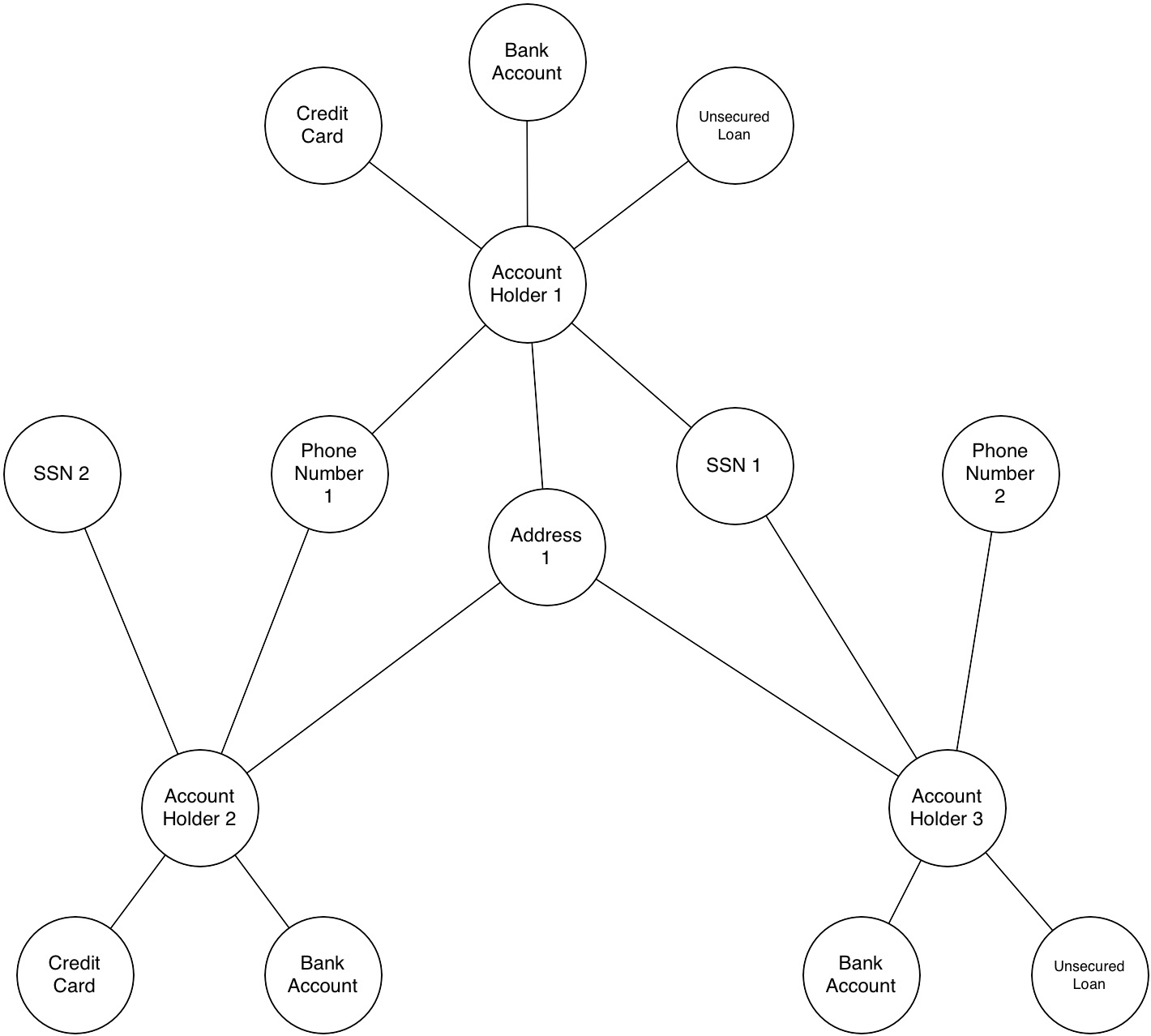
First thing: A graph – in mathematics – is not the same as a chart, so don’t picture a bar or line chart. Rather, picture a network or mind map, like in the example below.
A basic graph of a fraud ring sharing similar contact information.
A graph is composed of two elements: a node and a relationship.
Each node represents an entity (a person, place, thing, category or other piece of data), and each relationship represents how two nodes are associated. For example, the two nodes “cake” and “dessert” would have the relationship “is a type of” pointing from “cake” to “dessert.”
This general-purpose structure allows you to model all kinds of scenarios – from a system of roads, to a network of devices, to a population’s medical history or anything else defined by relationships.
What Is a Graph Database?
A graph database is an online database management system with Create, Read, Update and Delete (CRUD) operations working on a graph data model. Graph databases are generally built for use with transactional (OLTP) systems. Accordingly, they are normally optimized for transactional performance, and engineered with transactional integrity and operational availability in mind.
Unlike other databases, relationships take first priority in graph databases. This means your application doesn’t have to infer data connections using foreign keys or out-of-band processing, such as MapReduce.
By assembling the simple abstractions of nodes and relationships into connected structures, graph databases enable us to build sophisticated models that map closely to our problem domain.
There are two important properties of graph database technologies:
- Graph Storage
- Graph Processing Engine
Some graph databases use native graph storage that is specifically designed to store and manage graphs, while others use relational or object-oriented databases instead. Non-native storage is often much more latent, especially as data volume and query complexity grow.
Native graph processing (a.k.a. “index-free adjacency”) is the most efficient means of processing graph data because connected nodes physically “point” to each other in the database. Non-native graph processing uses other means to process CRUD operations that aren’t optimized for graphs, often involving an index lookup which results in reduced performance.
What Are the Advantages of Using a Graph Database?
A graph database is purpose-built to handle highly connected data, and the increase in the volume and connectedness of today’s data presents a tremendous opportunity for sustainable competitive advantage.
When it comes to applying a graph database to a real-world problem, with real-world technical and business constraints, enterprise organizations choose graph databases for the following reasons:
- Minutes-to-Milliseconds Performance
- Drastically Accelerated Development Cycles
- Extreme Business Responsiveness
- Enterprise ready
- ACID transactionality
- High availability
- Horizontal read scalability
- Storage of billions of entities
Query performance and responsiveness are at the top of many organizations’ concerns with regard to their data platforms. Online transactional systems – large web applications in particular – must respond to end users in milliseconds if they are to be successful.
In the relational world, as an application’s dataset size grows, JOIN pains begin to manifest themselves, and performance deteriorates. Using index-free adjacency, a graph database turns complex JOINs into fast graph traversals – which are constant time operations – thereby maintaining millisecond performance irrespective of the overall size of the dataset.
The graph data model reduces the impedance mismatch that has plagued software development for decades, thereby reducing the development overhead of translating back and forth between an object model and a tabular relational model.
More importantly, the graph model reduces the impedance mismatch between the technical and business domains. Subject matter experts, architects and developers can talk about and picture the core domain using a shared model that is then incorporated into the application itself.
Successful applications rarely stay still. Changes in business conditions, user behaviors, and technical and operational infrastructures drive new requirements. In the past, this has required organizations to undertake careful and lengthy data migrations that involve modifying schemas, transforming data and maintaining redundant data to serve old and new features.
Developing with graph databases aligns perfectly with today’s agile, test-driven development practices, allowing your graph database to evolve in step with the rest of the application and any changing business requirements. Rather than exhaustively modeling a domain ahead of time, data teams can add to the existing graph structure without endangering current functionality.
When employed in a mission-critical application, a data technology must be robust, scalable and – more often than not – transactional. Although some graph databases are fairly new and not yet fully mature, there are graph databases on the market that provide all the -ilities needed by large enterprises today:
These characteristics have been an important factor leading to the adoption of graph databases by large organizations, not merely in modest offline or departmental capacities, but in ways that truly transform the business.
What Are the Common Use Cases of Graph Databases?
While graph databases first became popular with social applications for the consumer web (Facebook, LinkedIn, Twitter), their use cases extend far beyond the social space.
Today’s enterprise organizations use graph database technology in a diversity of ways, including these six most common use cases:
Next week, we’ll take a closer look at how relational databases compare to graphs when it comes to data modeling.
Want to learn more on how relational databases compare to their graph counterparts? Download this ebook, The Definitive Guide to Graph Databases for the RDBMS Developer, and discover when and how to use graphs in conjunction with your relational database.
Catch up with the rest of the RDBMS & Graphs series:
Share Article



Explore
Related Articles




Top 10 Graph Database Use Cases (With Real-World Case Studies)
