
RDBMS & Graphs: Why Relational Databases Aren’t Always Enough



5 min read
Relational databases are powerful tools.
Since the 80s, they have been the power-horse of most software applications and continue to do so today. Relational databases (RDBMS) were initially designed to codify paper forms and tabular structures, and they do that exceedingly well. For the right use case and the right architecture, they are one of the best tools for storing and organizing data.
Because relational databases store highly structured data in tables with predetermined columns and many rows of the same type of information, they require developers and applications to strictly structure the data used in their applications.
But today’s user requirements and applications are asking for more. More features, more data, more agility, more speed and – most importantly – more connections.
In this RDBMS & Graphs blog series, we’ll explore how relational databases compare to their graph database counterparts, including data models, query languages, deployment paradigms and more.
This week, we’ll discuss why relational databases aren’t a good fit for connected data use cases.
Why We’re Writing This Blog Series
To begin, let’s be clear about why we’re writing this blog series.
First things first: We didn’t write this series to bash relational databases or to criticize a still-valuable technology. Without relational databases, many of today’s most mission-critical applications wouldn’t run, and without the early innovation of RDBMS pioneers, we would have never gotten to where we are with today’s database technology.
Rather, we wrote this series to introduce you – likely a developer with RDBMS experience – to a database technology that changed not only how we see the world, but how we see the future being built. Today’s business and user requirements demand applications that connect more and more of the world’s data, yet still expect high-levels of performance and data reliability.
We believe those applications of the future will be built using graph databases, and we don’t want you to be left behind. In fact, we’re here to help you through every step of the learning process.
While other NoSQL (Not only SQL) databases advertise themselves with in-your-face defiance of RDBMS technology, we prefer to be a helpful resource in helping you add graph databases to your professional skillset – no matter whether graphs are a replacement of or a complement to your RDBMS.
Relational databases still have their perfect use cases. But for those cases when you need a different solution, we hope this series helps you recognize when – and how – to use a graph database to tackle those new challenges.
The Mismatch between Relational Databases and Data Relationships
Despite their name, relational databases are not well-suited for today’s highly connected data, because they don’t robustly store relationships between data elements.
(It’s worth noting that relational databases take their name from the highly specific mathematical notion of a “relation” – a.k.a. a table – as part of E.F. Codd’s relational algebra. The name does not derive from describing relationships between data.)
Traditionally, developers have been taught to store data in the columns and rows of a relational model. Yet, columns and rows aren’t really how data exists in the real world. Rather, data exists as objects and the relationships between those different objects.
These types of complex, real-world data are increasing in volume, velocity and variety. As a result, data relationships – which are often more valuable than the data itself – are growing at an even faster rate.
The problem: Relational databases aren’t designed to capture this rich relationship information.
The bottom line: Applications (and the enterprises that create them) are missing out on critical connections essential for today’s high-stakes, data-driven decisions.
The Agile Realities of Today’s Software Applications
Every development team faces the reality of ever-changing business and user requirements that call for frequent modifications and pivots to a given data architecture.
Database administrators (DBAs) and developers face a steady stream of business requests to add elements or attributes to meet new requirements – such as storing information about the latest social platform – but such regular schema changes are problematic for RDBMS developers and come with a high maintenance cost.
That’s because relational databases don’t adapt well to change. Rather, their fixed schema works best for problems that are well-defined at the outset.
Slow and expensive schema redesigns also hurt the agile software development process by hindering your team’s ability to innovate quickly – a significant opportunity cost no matter the size of your bottom line.
The verdict: Relational databases aren’t engineered for the speed of business agility.
How Connected Data Queries Cripple RDBMS Performance
Despite advances in computing, faster processors and high-speed networks, the performance of some relational database applications continues to slow. This performance slump has several known symptoms, but the root cause usually boils down to one factor: queries about data relationships.
Since relational databases aren’t built or optimized to handle connected data, any attempt to answer data relationship queries – such as a recommendation engine, a fraud detection pattern or a social graph – involves numerous JOINs between database tables.
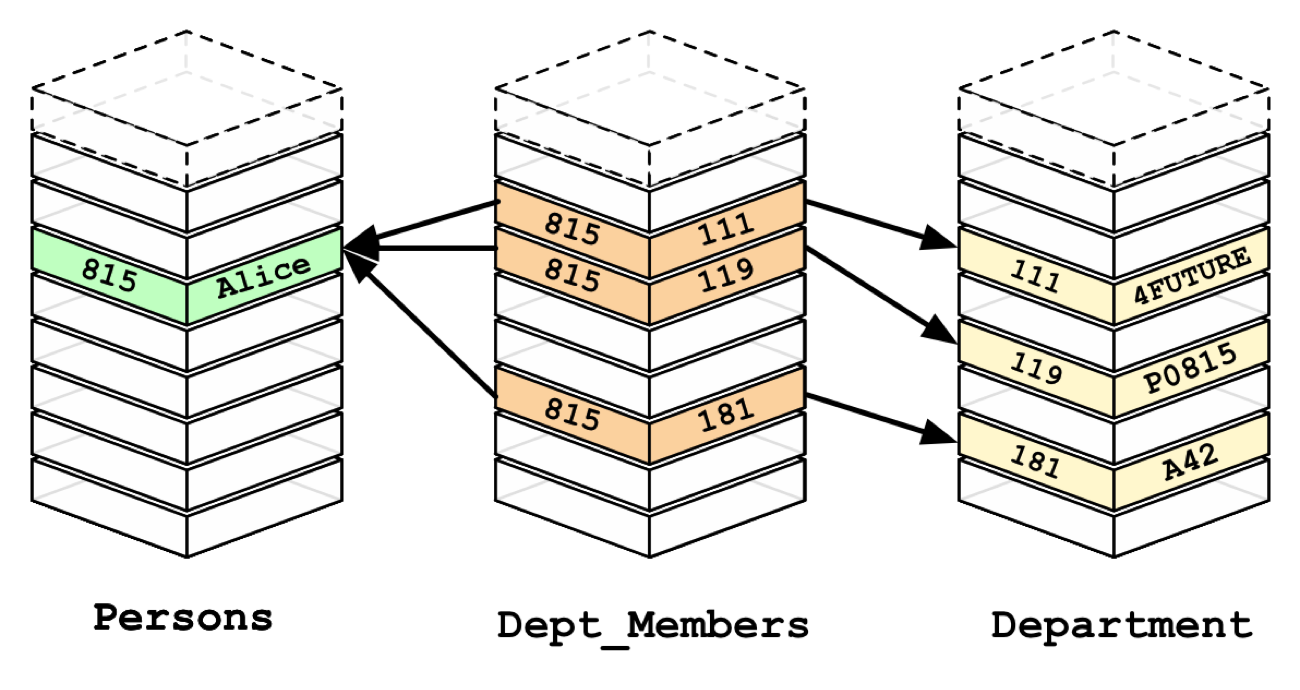
In relational databases, references to other rows and tables are indicated by referring to their primary-key attributes via foreign-key columns. (See below for an example.)

A JOIN table between the Persons and Departments tables in a relational database using foreign key constraints.
These references are enforceable with constraints, but only when the reference is never optional. JOINs are then computed at query time by matching primary- and foreign-keys of the many (potentially indexed) rows of the to-be-JOINed tables. These operations are compute- and memory-intensive and have an exponential cost as queries grow.
Consequently, modeling and storing connected data becomes impossible without extreme complexity. That complexity surfaces in cases like SQL statements that require dozens of lines of code just to accomplish simple operations. Overall performance also degrades from query complexity, the number and levels of data relationships and the overall size of the database.
With today’s real-time, always-on expectations of software applications, traditional relational databases are simply inappropriate whenever data relationships are key to success.
An Alternative (or Addition) to Relational Databases
As previously mentioned, relational databases have their appropriate use cases. For highly structured, predetermined schemas, an RDBMS is the perfect tool.
But as we’ve seen, relational databases aren’t always enough. Applications that require connected data insights can’t rely on the relational model alone.
While relational databases sometimes need to be replaced entirely, often the RDBMS solution can’t (or doesn’t need to) be shut down. In these cases, developers and architects can use a polyglot persistence approach – using different databases for their best-of-breed strengths.
So whether you’re replacing your RDBMS or just complementing it with another data store, the volume, velocity and variety of today’s data – and data relationships – require a solution that’s engineered from the ground up to store and organize connected data.
Next week we’ll meet that solution: graph databases.
Want to learn more on how relational databases compare to their graph counterparts? Download this ebook, The Definitive Guide to Graph Databases for the RDBMS Developer, and discover when and how to use graphs in conjunction with your relational database.
Catch up with the rest of the RDBMS & Graphs series:
Share Article



Explore
Related Articles




Top 10 Graph Database Use Cases (With Real-World Case Studies)
