
Graphs at Scale: Scale Out Neo4j Using Apache Mesos and DC/OS

Software Engineer, Neo4j
9 min read
Editor’s Note: This presentation was given by Johannes Unterstein at GraphConnect Europe in May 2017.
Presentation Summary
In this talk, Johannes Unterstein walks you through the mechanics and advantages of using Apache Mesos and DC/OS (data center operating system) for hosting your Neo4j Causal Cluster.
Unterstein starts by addressing the question of whether or not you even need a cluster (yes, you probably do). He then moves on to discuss how to keep data persisted through node failures, and how the best way to protect your data is through clusters of servers, including the Causal Clustering approach available with Neo4j. Clusters are also essential to overcome the challenge of load peaks.
This is where Apache Mesos comes in. Mesos uses a two-level scheduling system in addition to a master-agent scheduling architecture to optimize compute resources in the best possible way.
He then moves on to dynamic container orchestration and the concept of local persistent volumes: If the container containing a particular label fails, or if the container is restarted for an upgrade or maintenance, you are able to restart the replacement container exactly on the same data again to prevent full-cluster replication.
Finally, he wraps up with an explanation of how to use Neo4j and DC/OS, including a demo of a Twitter stream in Neo4j.
Full Presentation: Graphs at Scale: Scale Out Neo4j Using Apache Mesos and DC/OS
This talk focuses on scaling Neo4j Causal Clustering on top of DC/OS.
My name is Johannes, and at the time of this presentation, I worked for Mesosphere, the company behind DC/OS. [Johannes now works for Neo4j.] You can find me on Twitter, and I’m in two Slack communities. We have a DC/OS community Slack. I’m also available in the Neo4j user Slack community, especially on the Neo4j DC/OS channel.
I want to talk about clusters, and I’m really happy with the new Neo4j 3.2 clustering features. I will go over all the new features and answer questions like Why do I need a cluster?
Do I Actually Need a Cluster?
Neo4j is great at storing data in one node, and having a big graph dataset at one node. It’s great at serving a bunch of requests and a bunch of Cypher queries on that single node.
Keeping Data Persisted through Node Failures
But when it comes to high availability, when you’re not allowed to have downtime, when your business is depending on your Neo4j installation, or if you really want to keep your data persistent even through failures of nodes. If you put it in containers of nodes or even data centers, you want to make sure your data’s persisted, and you probably need a cluster of more than one node.
Or, in the third case, it’s a matter of high-throughput. When you really have big requests – so we have a huge amount of requests – you need a scale-out strategy for serving all of these read requests. And this is all about the Neo4j Causal Clustering technology.
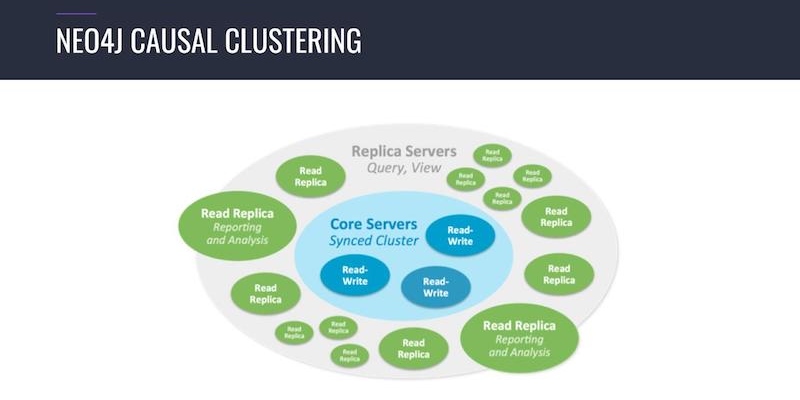
The Causal Clustering technology introduced in Neo4j 3.1 consists of two parts basically. You have core servers, and they’re basically in-sync, and they receive read and write requests. So when you’re talking to one of these leading core node, it’s basically building a leader-follower concept. So when you’re talking to the leading core node and writing these write requests, it is synced to the other core nodes so they’re always consistent.
You also have read replica servers that are basically caches but really intelligent ones. They’re full-fledged Neo4j nodes, but they can be specialized for caching, for region or for special purposes like analysis or reporting. Some nodes are specialized on these topics and other nodes on other topics.
So we have these kind of technologies while we have a core part of the cluster and the scale out part. And the scale out part can be scaled out to hundreds of thousands of servers.
When we’re talking about these amounts of servers, or talking about large data centers, you don’t just have Neo4j running but a couple of data services running. It’s your whole stack: You have Neo4j, you have probably Kafka or Cassandra or Flink when it comes to streaming, and Apache Spark and so on, and you have your data center microservices.
What we often see is that you static partition your clusters, pinning applications to specific nodes. If you have a cluster – let’s say you have 30 nodes – and you say the first two are for Neo4j testing, the next three for Neo4j prod, and then you have five for microservices, five for Cassandra, and so on, and so on. This has a bunch of downsides.
The Challenge of Load Peaks
Let’s talk about load peaks.
When one part of the application is on a heavy load and then some node fails, you’re not able to dynamically shift this workload to another physical or visual load. This is a problem with these kinds of static partitioning. The other problem is that you need to optimize each subpart of your cluster against load peaks.
If you optimize all parts, you need to make all separate parts able to serve load peaks. This is a huge waste of resources: CPU, memory, and probably disk waste as well.
What would be a little bit better is multiplexing, pictured below. You are then able to dynamically shift the resource – the running services between servers based on the available resources – on that node. So you can optimize your whole cluster against load peaks.

You can react dynamically to node failure, shifting around, running services to other nodes. Also, you can combine your microservice architecture on the same cluster, on the same nodes, together with your data service, your big data, your streaming, and your complex data like Neo4j.
A Brief History of Apache Mesos
This is where Mesos comes into the game. Mesos was invented in 2009 at UC Berkeley. There were three students making a class project, and they wanted to invent a system to have fine-grained resource-sharing within a cluster between different applications.
At the time, MapReduce was really popular, so they wanted to share resources between different kinds of MapReduce things.
At the same time, Twitter had these crazy scaling problems. Do you remember the Twitter Fail Whale? So this sad whale shows up when Twitter was not able to respond to user requests because of scaling issues.
Twitter was super happy about the concept of having a higher utilization of their cluster resources and being able to manage their servers accordingly. Twitter really pushed that forward. In the same year, a source code draft of Mesos was published. Mesos entered the Apache Incubator project, and soon afterwards it entered the Apache top-level projects.
Mesos nowadays is used in really big installations. Twitter uses Mesos for their productions. They publish numbers at about 27,000 nodes – clusters to serve twitter.com. But Airbnb and Netflix also use Mesos, so we have a big utilization advantage if you’re able to dynamically shift the resource between the applications during times of day.

Mesos basically works on a two-level scheduling system, which is kind of cool.
Mesos itself deals with resource negotiation, sharing resources across a cluster. Mesos has a master-agent concept. And the master is in charge of distributing all the compute resources – memory, disk, CPU and ports – between all registered schedulers, as well as dealing with node failures and so on.
But the actual scheduling decision is done by the scheduler. This decision was made because scheduling stateless containers, for example, is way different than scheduling a big data framework, or a complex data framework, or a streaming framework.
If you’re stateless, you probably don’t care about the restart of an application in case of failure. By running Cassandra, carrying multiple gigabytes of data, you probably want to wait a few minutes, to see if the failing node comes back to prevent a full cluster replication.
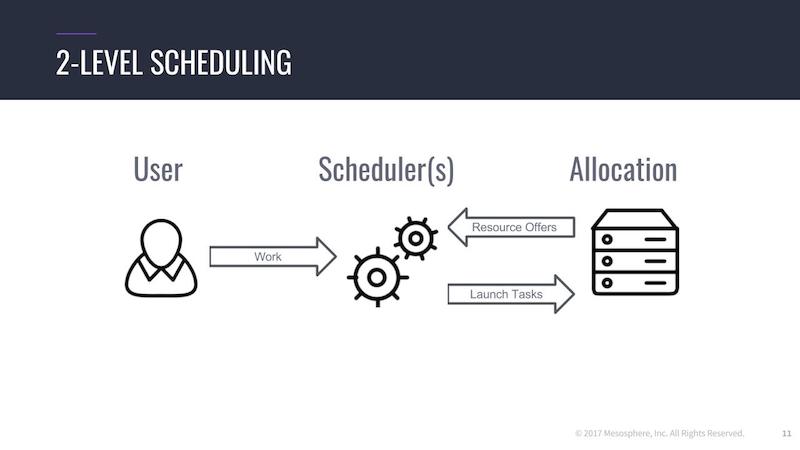
So this is a reason why this is split up, and as a user I’m talking through the scheduler. I’m saying, “Hey, I want to have 20 instances of my microservice running. Please do that for me.”
The scheduler on the other side talks to Mesos, accepting the resource offers given by Mesos, and then decides on a given logic of where to start all the services the user wants to have.

To add a more technical view of that, Mesos by itself is a master-agent architecture.
You can have Mesos as a master with high availability, so you have three or five nodes depending on your availability requirements. They’re also building a quorum – just like Causal Clustering – but this quorum is based on Zookeeper.
Underneath the Mesos master you have the Mesos agents carrying resources for computation. And on top, you can have several kinds of schedulers, so you can have Marathon, which is our interpretation of container orchestration, or Myriad, which is a bridge for Hadoop, or you can have Cassandra, Spark, Kafka, or you can even run Neo4j on this.
In the current implementation, Neo4j is based on the Marathon container orchestrator, and we will have a short look into this in a second.
Dynamically Running Your Containers
But first, I want to talk about data.
We’re now at the point where you can dynamically run your containers in your data center, and you actually don’t care where it’s running as long as it is running. You need to think about where your data is actually stored when you’re running data services on top of the same dynamic infrastructure, and basically, you can distinguish between three kind of applications.
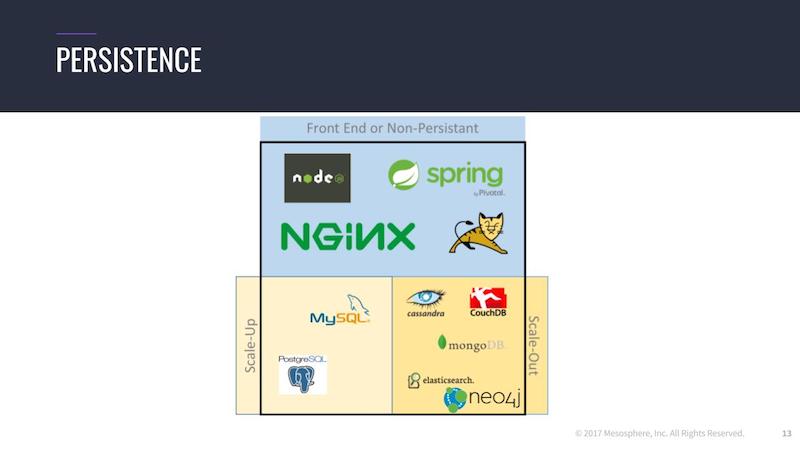
You have stateless applications, like Tomcat on NGINX, or something like this, which is probably not relevant where it’s restarted. And you can have scale-out databases, databases that are written for distributed systems. This is MongoDB, Elasticsearch, Cassandra or Neo4j and the new clustering features, and they are scaling by adding more new nodes to the cluster.
Or you can have scale-up databases, traditional database like MySQL and PostgreSQL, which are not designed initially for distributed systems and where the cluster support was added afterwards. For these kind of applications, Mesos and DC/OS offers different search options.

For stateless applications, you’re probably not interested in keeping your data.
It’s okay to have a local folder – having a sandbox – and it gets deleted after the container stops. But when we’re talking about data like Neo4j, which has an in-builder application, it’s probably really cool to have something like local persistent volumes.
Local persistent volumes is a concept that you have a place on your disk carrying a label – it’s reserved for Neo4j – and if the container fails, or the container is restarted for an upgrade or maintenance, you are able to restart the replacement container exactly on the same data again to prevent this kind of full-cluster replication.
You only need to replicate the small amount of data between shutting down and restarting again. So it is a big advantage, and you have the big advantage that you have local writes, so your local disk. So this is really great for databases like Neo4j.
If you are in the situation of having a single-instance database, for whatever purpose, and you want to have this data persistent and stored forever, even if the node fails or the database it runs on, you probably need something like distributed file systems, or an external file system that is distributed and fault-tolerant. But for Neo4j, we do not need this.
Using Neo4j and DC/OS
Now we come to DC/OS.
DC/OS is a platform on top of Apache Mesos, which includes Marathon for container orchestration to have a battle-proven platform for running microservices. But it also adds a benefit to run all your data services, streaming, machine learning, complex data and so on.
You have your whole stack in one platform. And on top you get a concept for security for the whole platform, a common roadmap, common documentation, common CLI and UI.

Demo of a Twitter Stream in Neo4j
Let’s take a closer look at using Neo4j together with DC/OS in this demo of a Twitter stream in Neo4j:
You can easily scale your database, having all your complex graph data inside the same cluster architecture – just like you would run the rest of your stack like streaming and big data microservices and so on. It’s really easy to operate Neo4j Causal Clusters on top of DC/OS.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



