Build Spring Data Neo4j 4.1 Applications Like a Superhero

Global Head of Public Sector & Workforce Intelligence
16 min read
–
What we’re going to talk about today is how to build an application in under 30 minutes using Spring Data and Neo4j:
Spring Data, the most active Spring framework project today, offers a convenient way to access databases — particularly NoSQL databases.
It provides consistent APIs that do typical crowd-like operations, executing queries with a very consistent API. Typically you have to annotate POJOs (i.e., “Plain Old Java Objects”) that map the domain objects to the underlying database. The more popular implementations of Spring Data include Neo4j followed by JPA (Java Persistence API) and MongoDB.
Object-Graph Mapper Features
Why the focus on the performance of Spring Data Neo4j (SDN) 4.1? Earlier versions of Spring Data Neo4j were only built to support Neo4j in embedded mode. It unfortunately wasn’t catching up with new Neo4j servers as they were released, which resulted in performance problems when working over the wire.
In SDN 4, we re-routed it from scratch to provide a more performant way of accessing Neo4j over the wire, which then only supported Neo4j over HTTP. But our latest release is able to access Neo4j via three drivers: HTTP, which operates using Cypher over the transactional endpoint; with an embedded driver; and — our newest addition — with the Bolt driver.
Another important difference in Spring Data Neo4j 4 is that we’ve engineered the Object-Graph Mapper (OGM) in such a way that it can be used completely separately from Spring, while still offering 90% of the Spring framework features.
To do this, we use a process called “vampire metadata scanning” to scan the classes that contain your domain objects and translate your domain model into a graph. We call it “vampire scanning” because there’s no reflection, which greatly decreases start-up times to more quickly bring up your application.
This version also offers smart object mapping, which allows us to recognize and send only new domain model changes to Neo4j for persistence and makes the application much more performant. For example, if you’ve performed two actions that may cancel each other out, such as adding a relationship and then deleting that same sort of relationship, OGM won’t send them to the graph. All of this is done right after you save your object.
These domain model changes are managed by what is called a mapping context, which allows us to know what has been mapped, what hasn’t been mapped, and what needs to be mapped. This is closely tied to a session, which represents your conversation with the database and is sent to Neo4j to persist. Because this is tied to your session lifetime, it can be operated in various scopes, including application scope. This provides a view of all the actions that have been made in your applications over its lifetime.
Because of these changes, it’s likely that there’s actually a small amount of data that you need to send over the wire. The downside is that if other users are modifying these objects, your application-wide session scope may not see those until you load them yourself. For these web-based applications, the HTTP session scope (request scope) which closely mirrors your true unit of work is something you should assign to your session. This provides a good balance between not knowing anything and knowing everything, without missing updates.
We also offer support for both default converters and converters that you can add yourself, which are for converters that are non-native Neo4j data types. We can support more simple data such as dates, URLs, and enum by converting it right out of the box. But for more complex classes that need to be stored as node properties, you simply write a converter that will convert that data both when it’s written to and loaded from the graph.
Spring Data Neo4j 4.1 Features
The following features are only found in Spring Data, the first of which is repositories. These allow you to do your CRUD operations in a very standard, consistent manner. You will have methods out of the box to load data, load objects, save objects, find objects by, and query objects. It also has a Neo4j template, which is slightly more low-level if you want to use Spring Data directly instead of using repositories. Really all the functionality that powers repositories and the Neo4j template belongs to the Neo4j OGM.
Another feature you’ll find in Spring Data Neo4j 4.1 is custom queries, which are at-the-rate query annotations that are actually backed by OGM, so they can be used in those sessions as well. Conversely, the derived finders feature is only a Spring functionality, which allows you to assign property filters to your queries.
Transactional support is available in both OGM and Spring. In some operations we provide implicit transaction, which is the equivalent of an autocommit transaction. In Spring, any time you save, query or delete objects, we automatically wrap it in a transaction and send it to Neo4j. However, in the OGM, you can manage this yourself.
The last feature is variable-depth persistence. Very frequently when you have a node, you are most interested in those other nodes that are one hop away. There are a few ways to find those related nodes, one of which is to load a single node with its properties and then make multiple calls to the database. But, that’s highly inefficient.
Instead, you want the first-level connections. Below is the persistence depth of one, which has the node and only those first level relationships:
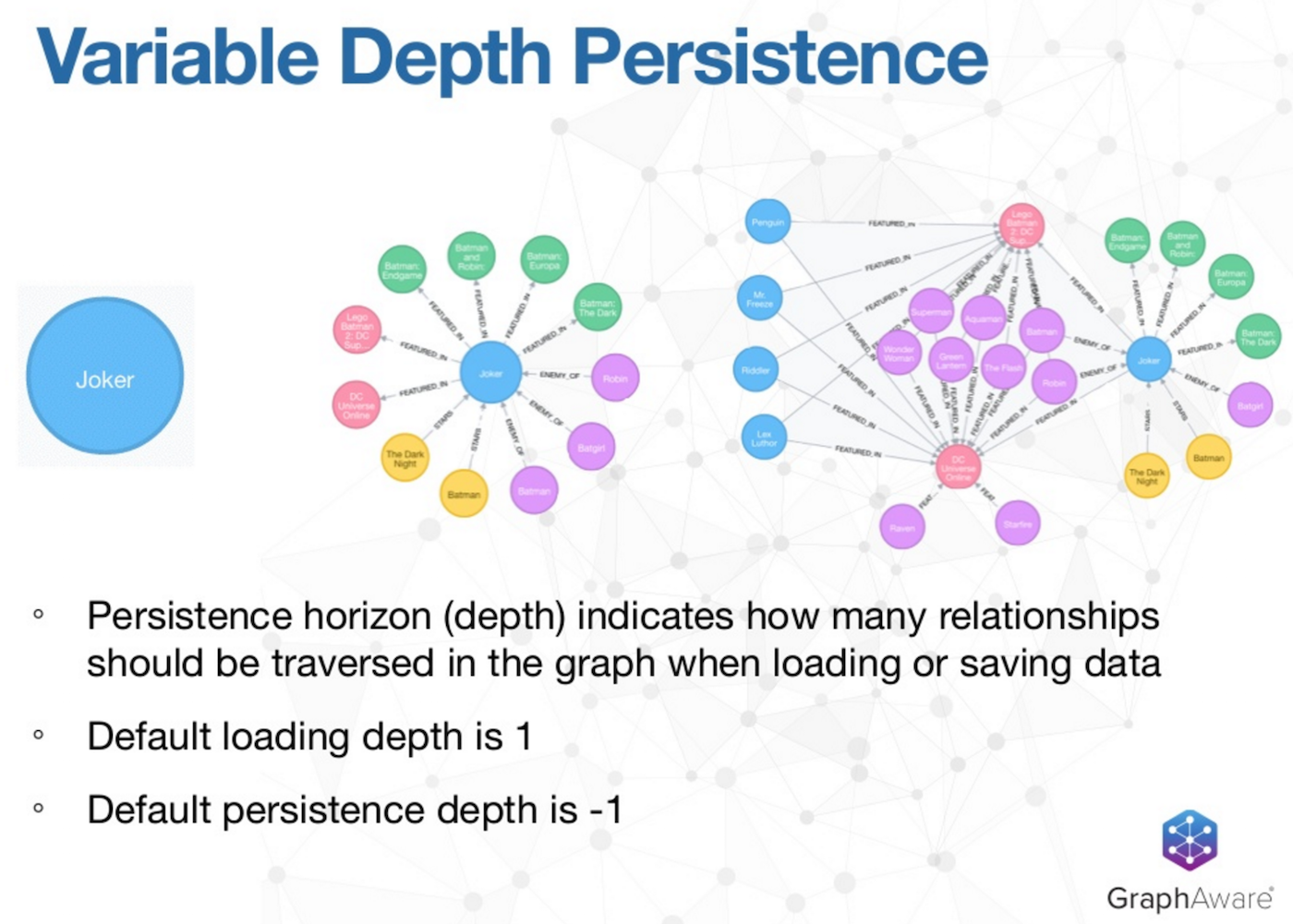
This is fully customizable, but Spring Data Neo4j 4.1 and the OGM assume very sensible defaults. When automatically loading your objects, the default depth is one, which is the graph shown in the middle (above), but you can also load at whatever depth you want. The second example on the far right (above) is loaded at a depth of two, which essentially picks up the node in the center – the object of interest – and finds everything two hops away. This really indicates how many relationships you should traverse in the graph when you’re loading and saving data.
The default for saving data is minus one, meaning that when you save an object, we will find out whatever has changed in all the objects that are reachable from the object that you are saving. In other words, if you’ve made changes to a lot of connected objects, you can just save one of them and Spring will automatically save the rest.
Variable depth persistence is a really important feature of SDN 4.1. The default persistence depth is minus one, but this can be changed. However, we do recommend that your loading and your persistence depth be in sync.
Example: Building a Superhero Graph
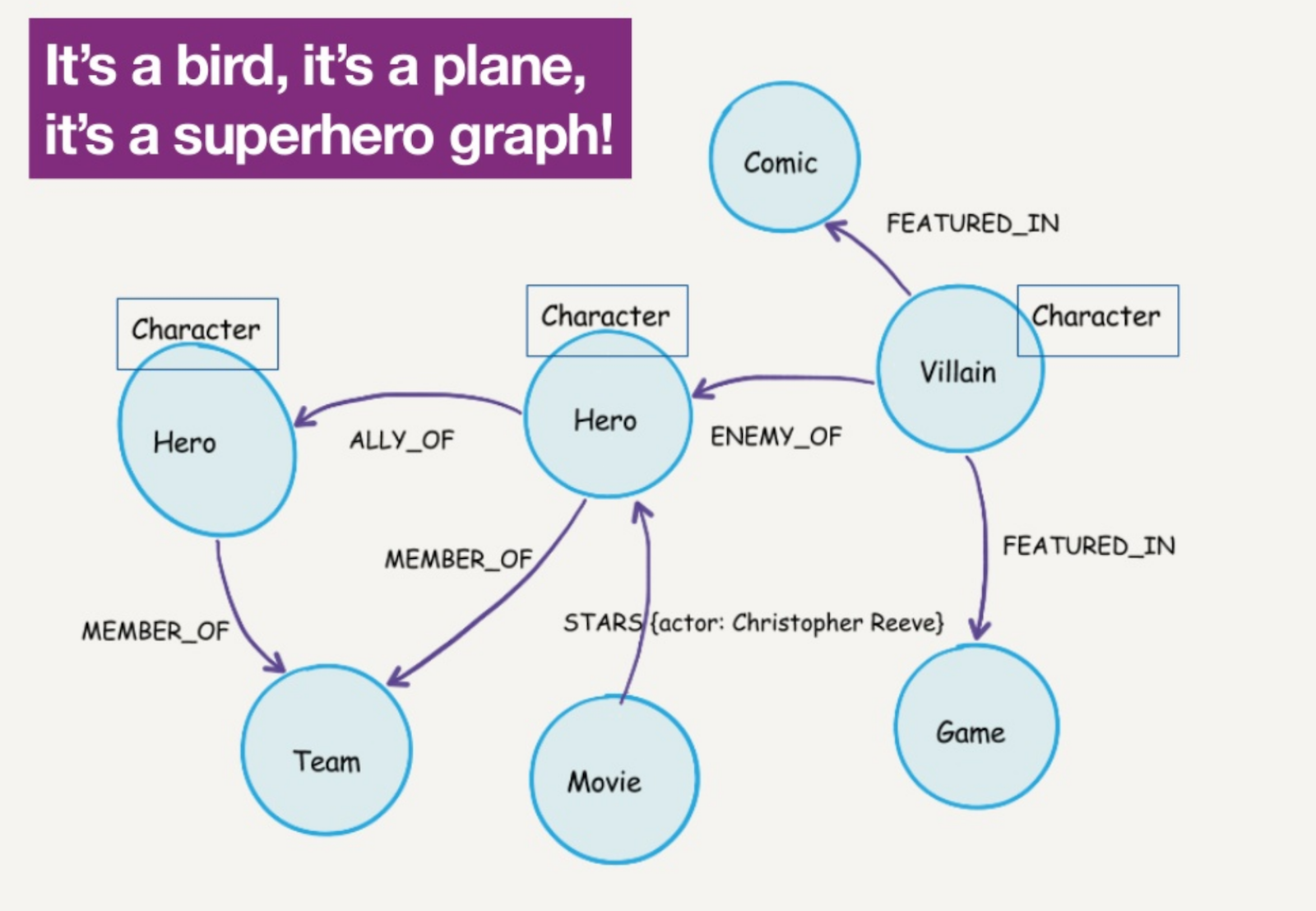
Next we’re going to build a superhero graph with a very simplified domain data model:
We have nodes that represent characters, which can either be heroes or villains, as well as teams, games and movies. Relationships include allies, enemies, members of, stars in and featured in. In this case, we decided to store the actor that played a role as a property on the relationship.
The Character Node
Below is a portion of the character class with the annotation NodeEntity which shows the label as “Character:”

This annotation is optional. Even if it’s not included, we’ll know that character represents a character node. We recommend using annotations, because if you want to change labels, this makes your database immune to re-factoring and keeps your code clean.
The graph ID is the Java line that attaches your entities to the graph. It’s the internal node or relationship ID used by SDN to determine the entity’s location in the graph. We recommend using internal node and relationship IDs as your own keys, which behave like regular properties. Apart from that, we have all the other properties — name, alias, etc. — that we want on the character node.
Below are some of the relationships associated with our character node:

While relationships don’t have to have an annotation, we strongly recommend having them for two reasons. First, adding annotations prevents relationships from being derived from what your collection is called, which allow the names to make more sense. Second, they also let you specify a direction. In this case, both the allies and the enemies are undirected; we don’t care which direction the relationship is pointing, only that it is there.
In addition to Ally_Of and Enemy_Of, we have Member_Of to indicate that a character is a member of a team, which has no relationship type defined. It’s safe for us to assume that undefined relationships are outgoing. Again, this is a set of teams that a character belongs to because — of course — superheroes can belong to many teams at various points throughout their stories.
Next we have Featured_In, which shows us which games, comics and movies the character has appeared in. It’s important to note that you can have the same same relationship type with different end nodes. For example, our character may be featured in both a game and a comic, which will give it two different types of nodes with two different end types. This won’t cause any problems in Spring Data Neo4j 4. Just make sure you don’t have the same relationship type and the same end node.
The last kind of relationship is the rich relationship between a character and a movie — the Stars relationship — which we call rich because it has a property and role. Because this will always be an incoming relationship from a movie node, we have to indicate that in the code.
We further specialize our character node with the label hero or villain. Because there aren’t many properties that distinguish them, it’s sufficient to extend these two and set their labels. SDN will make sure that all your villain nodes have two labels – a villain and a character – and that your hero nodes have a hero and a character label. This is currently the only way to have multiple labels assigned to your nodes in SDN or the OGM.

Let’s briefly review the rest of the classes. For the team node, the same rules apply: Provide a node entity, give it an annotation and set a label on it. Even though your class name is the same today, it may change in the future.
You also have a graphID. Under properties you have your relationship, which is the reverse relationship to the character. Again, note that it’s incoming:

For comic, we have generally the same set of code. It’s important to remember to assign it a graphID:

The only real difference here is the presence of a “date” field. Spring will store your date as a string by default unless you annotate it with DateLong. Binding is an enum, so you don’t have to apply a converter to it because it’s already built in. As long as you have an enum we can recognize, meaning it’s scanned with your domain packages, we will automatically convert the enum to a string property, store it on your node and convert it back to your enum when you load the entity from the graph.
Next we have game, which will show a log of familiar annotations. We have a collection of enums, which Spring serializes to a string. The resulting array of strings is stored as a property on your node, which you don’t need to annotate.

With movies, we have a URL. Because Spring doesn’t have a default URL converter, you have to write your own converter. This will look something like the following:

You implement the attribute converter interface, and then you tell Spring what should be in the graph and when to read information back from the graph. This will even work with the Spring conversions service — they all play nicely together.
Finally we have the role, which is a rich relationship between the character and the movie:

The only time you need to model a relationship as a relationship entity is when they are distinguishable from each other because of varying properties. In this case, the annotation for a relationship entity is mandatory. We have to specify that the relationship type should be stars, and for ID we don’t have a primary key for a role because it’s not important from an application point of view.
Because of this, I’m just going to say I have this long ID which we will really recognize as the graphID. This is an example of when the graph ID is optional.
After you have your ID and your annotations, you need to have a start node and an end node. In this case, the start of this relationship is from a movie to a character. And the only property it has, apart from its internal ID, is the actor that played the role in this movie. This is why you don’t reference your movie and character class directly; you always reference them to the relationship entity because it really sits between your character and your movie.
Repositories are standard Spring Data repositories that now extend to graph repositories:

It provides all the things you’d expect from Spring Data right out of the box, such as find by ID, save, load, etc. The things you need to add to it are derived finders, such as findBy and NameLike.
On your character class you have a property called name. Instead of writing a Cypher query to find characters by name, you use a derived finder so that Spring can form the query for you. We’ll match by label and character where name is similar.
In this case, we return T because the application I’ll be showing you shortly has two kinds of searches, one of which is a search for all characters, and the other that allows you to search for characters by type (i.e., hero or villain). Because these classes and repositories extend to each other, defineByNameLike will operate differently depending on whether you use it from a hero repository or from a villain repository, because it will filter by the label.
The above example is of a custom query that has both an at-the-rate query and a large Cypher query. Together, this is going to search for a related character; e.g., given a certain character, what are other characters you might be interested in? In this case, we are looking at characters that are enemies or allies of each other and are in the same team, appear in the same comic book or act in the same movie.
Below is what the hero and villain repositories look like. All you have to do is extend your character repository:

Services is very straightforward: Inject your repositories, delegate your calls and you’re done:

We have essentially the same thing for Controller, which sits on top of your services:

The last piece you need in order to get everything up and running is configuration: How do you configure Spring Data Neo4j or the OGM?
The easiest way to do this is with auto configuration. So you supply an ogm.properties file, which must have at least two things: the driver you’re using (HTTP, embedded or both) and the URI to the database. If the driver is embedded, it will already be a part of the database. But if you’re using Bolt or HTTP, they will each have a URI.
If you don’t want to auto configure and need to pull your username and password from elsewhere, you can set up your configuration explicitly. Through Java, it’s very simple: You get your driver configuration, set the class name, set the URI, pull from your sources and go:

Doing the configuration in SDN requires a few more steps, including extending the Neo4j configuration class. Next, you enable the familiar Neo4j repositories which makes up your package that contains all your repositories that extend from the graph repository.

You also have the session factory, which is the entry point that sets up all your metadata where you send all the packages that contain your domain information. It’s responsible for supplying this metadata to every single session that you create and use in your application.

From the session factory, you get your session, which is the thing that you use for querying, loading and saving, which is the scope I covered earlier in SDC. We also have HTTP Session scope, which you can change. And the scope and life cycle of that session will be managed for you.
And now we have completed all the code we need to produce the following application! Watch the below video to see how it works in action:
Additional Resources
Need help?
- Go to Stack Overflow and post questions with the tags
spring-data-neo4j-4andneo4jogm - Join the #neo4j-sdn channel on Slack
- E-mail the SDN team
- Raise issues in JIRA
- Follow us on Twitter
- Follow the GraphAware Blog
Inspired by Luanne’s talk? Click below to register for GraphConnect San Francisco and see even more presentations, talks and workshops from the world’s leading graph technology experts.
Until July 31st, Early Bird tickets are just $99!
Share Article



Explore
Related Articles

Getting Started With Neo4j Aura: A Guide to the Leading Cloud Graph Database