
This Week in Neo4j: Batch vs. Stream, UX Survey, Kafka Example, Jupyter/Docker for Data Science, Deep Learning

Curriculum Developer at Neo4j
4 min read

Hello, everyone!
We at Neo4j are working to continually improve the UX experience for our users. If you have the time, please consider meeting with us to discuss your experience with our products and what you would like to see in future releases.
In this week’s episode, Neo4j’s David Allen shares his experience around batching vs. streaming data into Neo4j. Neo4j’s Alex Woolford and Rob Martin developed a quick and easy example for demonstrating how to move data from Kafka to Neo4j, and Clair Sullivan posted a blog that describes how easy it is to use Jupyter Labs and Docker to set up your data science environment for Neo4j. Ana Arias from Kineviz posted a blog about the work done in creating the DreamScape application at UCCS.
In addition, we have included a link to the recorded presentation that Giuseppe Villani and Davide Fantuzzi from LARUS did at NODES 2020 entitled Lightning Fast Zero to Production with Spring, Neo4j and jHipster.
Cheers,
Elaine and the Developer Relations team
Featured Community Member: Camilla Dal Rio
This week’s featured community member is Camilla Dal Rio.

Camilla Dal Rio – This Week’s Featured Community Member
Camilla has worked for Moviri in Italy for more than three years as an analyst and consultant.
Camilla will be presenting this year at NODES 2021 with a session entitled Set your Graph in Hyperdrive with Machine Learning and MLOps.
She has done much in the area of data science. In her own words:
“I’ve always been fascinated by nature’s mathematical order. There’s a model to explain almost every phenomenon, whatever the field. I pursued the Bachelor in Statistics and the Master in Quantitative Finance with the aim of collecting the tools to understand and study this divine-mathematical order of things. I’ve been working within the data science field for years now in Moviri, having the possibility to develop modeling procedures in telco, marketing, finance, and more, and having a first-hand touch on all steps of data science, from data ingestion, ETL, modeling, visualization, and flow automation.
“It’s been a hard, challenging, and enthusiastic experience that’s still teaching me how this world is endless and magnificent. I would like to share my experience with graphistas and data scientists in general, to share our passion and learn from each other by real experiences and use cases.
“Last but not least, I’d been a professional swimmer for some years, and I preserved my motto also in my current job: ‘Hard work pays off.’ Let’s keep pushing and learning for greater and greater achievements!”
Batch vs. Streaming Data into Neo4j
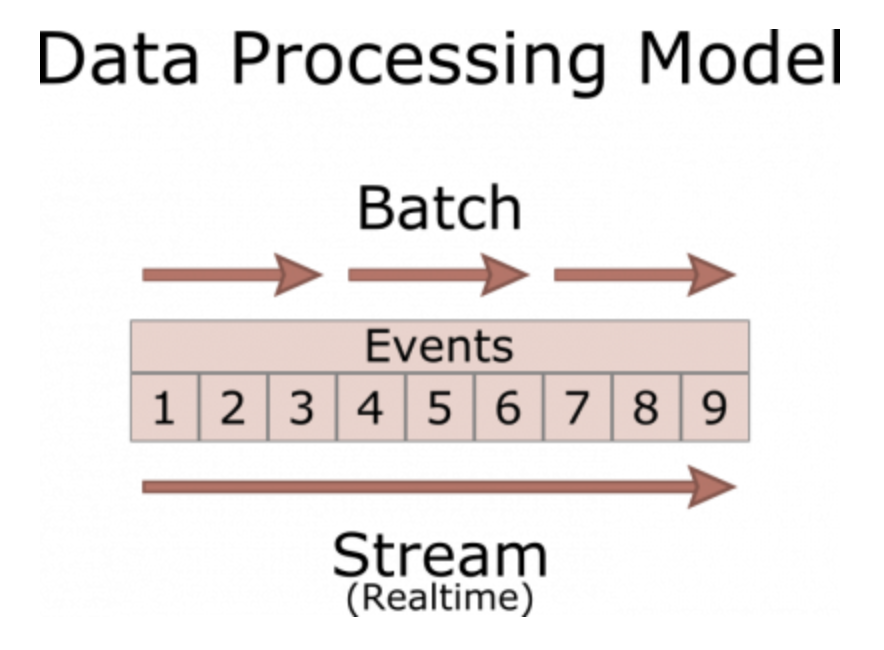
Our colleague David Allen has posted a thread of tweets that can help you understand the challenges of ingesting data into Neo4j. There are benefits and trade-offs with batching and streaming. You can get a lot of “lessons learned” tidbits from what David has to say here. For example, he shares why streaming is so resource-intensive and why you may choose “mini-batches” instead.
Neo4j Developer and Data Scientist UX – We Need Your Input!
Help Neo4j improve the user experience for developers and data scientists. We ask you to spend an hour a month for feedback sessions with us, and we will compensate you for your time. If you’re interested, please fill out the form and we’ll get back to you when we can.
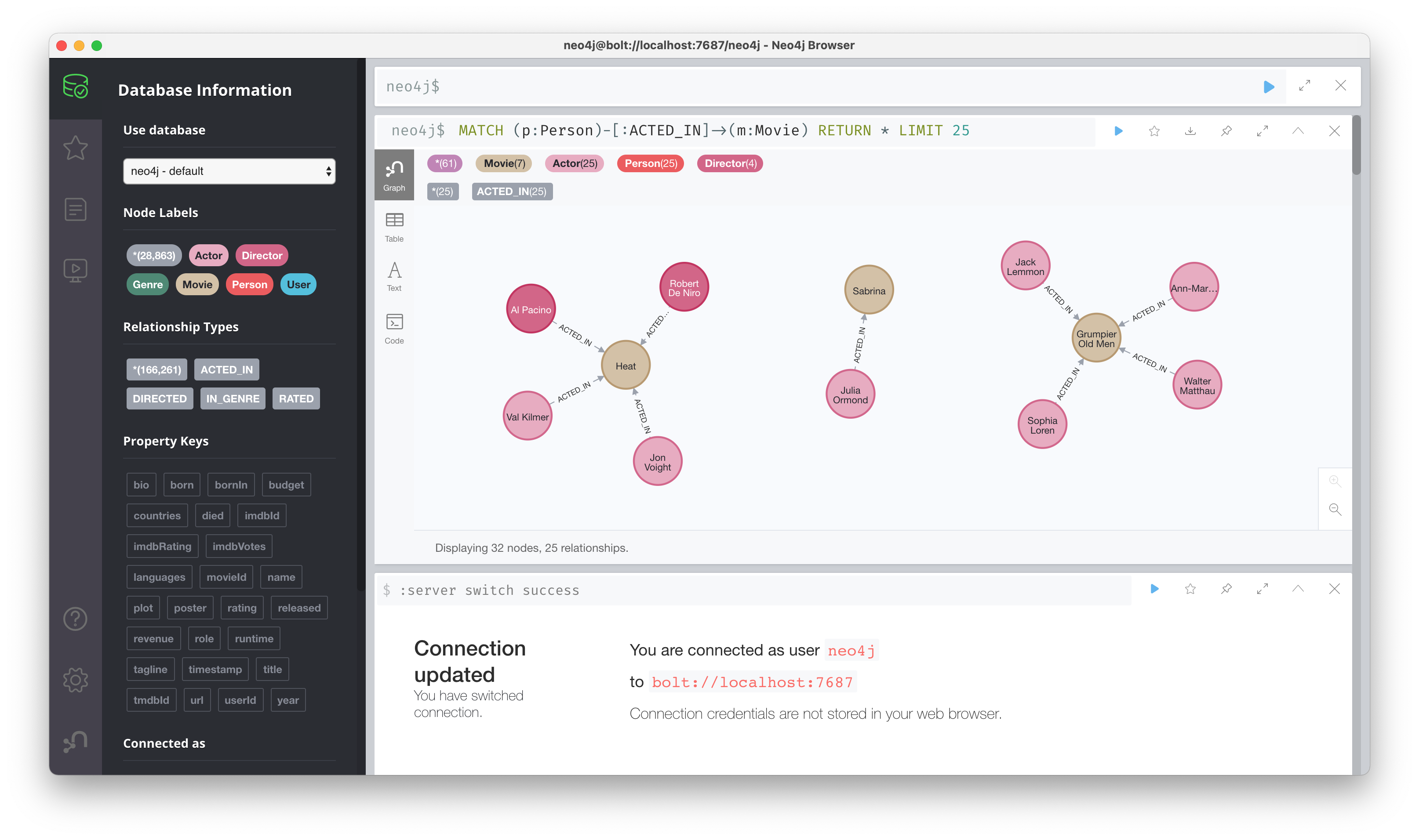
Practical Example: Kafka → Neo4j
Alex Woolford and Rob Martin created an example that shows how to sink data from Confluent Cloud to Neo4j, by running Kafka Connect in a Docker container.
Get Going with Neo4j and Jupyter Lab through Docker

Clair Sullivan, a data scientist here at Neo4j, wrote a blog post that teaches you how easy it is to set up your Docker and Jupyter environments to use Neo4j for your data science projects.
DreamCatcher: Deep Learning and Graph Analytics for the Dreamscape
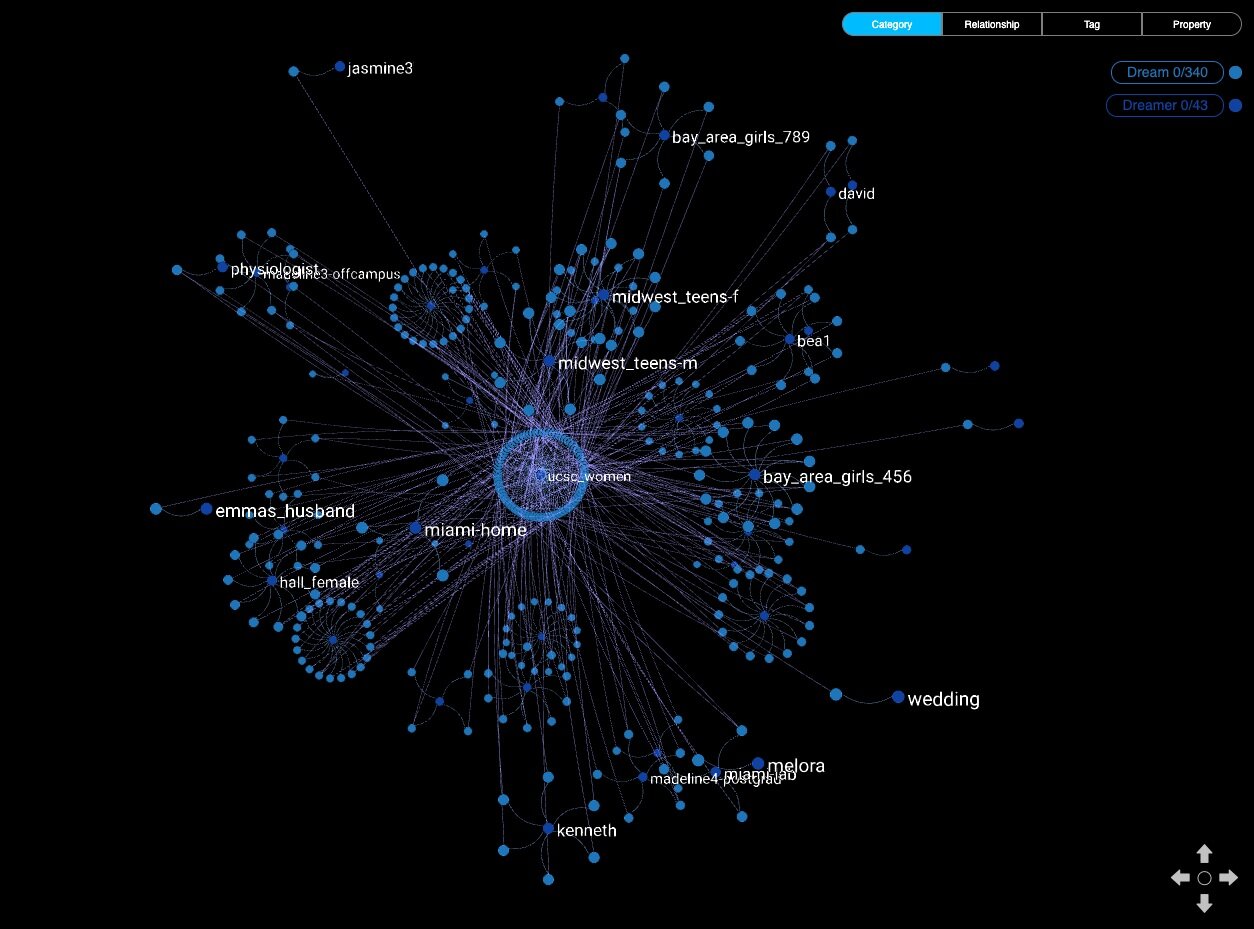
Ana Arias, from Kineviz, wrote an interesting blog about the work that University of California, Santa Cruz researchers have done to analyze dreams by creating a dream graph. They used GraphXR and Neo4j to implement their deep learning application that created a dream similarity graph. It uses NLP from dream transcripts to generate the content for the graph.
Read the Blog Post
NODES 2020 Video of the Week (recording): Lightning Fast Zero to Production with Spring, Neo4j and jHipster

Last year, at NODES, Giuseppe Villani and Davide Fantuzzi from LARUS Business Automation showed us how to develop an application with JHipster and integrate it with Neo4j. In their application, they use these client-side technologies:
- Npm or yarn
- Webpack
- Browsersync
- Jest
On the server-side, they used:
- Spring Boot with Spring MVC + Jackson
- Spring Data JPA
- Spring Security
- Netflix Oss (for microservice)
- JUnit
Nodes 2021: The Largest Graph Dev Conference Is Back!

Reserve your spot now for NODES 2021, an event designed for developers to bring their graph database skills to the next level. This is a free event that will be held on June 17th.
You can register here.
Tweet of the Week
My favorite tweet this week was by Adam Cowley:
I have spent years writing complicated order/collect/unwind statements to create linked lists between nodes.
Today I found out about the https://t.co/jcR1EMdqws procedure ??♂️https://t.co/hJ0Y4K3ZqV pic.twitter.com/rd7S1pSVYU
— Adam Cowley (@adamcowley) May 19, 2021
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


