This week in Neo4j – Building a fashion knowledge graph, Carrefour basket dataset challenge, community detection on Game of Thrones, analysing network traffic


4 min read

Hi graph gang,
There was so much content produced this week that I couldn’t fit it all in! Don’t worry though, we’ll cover the rest next week.
In this week’s video from the NODES 2019 conference, Luanne Misquitta explains why the most popular graph modeling advice is ‘It depends’.
Tomaz Bratanic demonstrates the seed property feature of community algorithms, Alex Woolford analyses traffic on his home network, and Jesus Barrasa’s builds a fashion knowledge graph.
And finally, Rik has started a series of blog posts exploring data from the Carrefour Basket Data Challenge.
Enjoy!
Mark Needham, Karin Wolok, and the Developer Relations team
Featured community member: Polley Wong
Our featured community member this week is Polley Wong, CTO at Swade Inc, VIU.SPACE Co-founder & CEO and wecreate.group Co-founder. Polley is using a cool combination of technologies at her company, including Go, Node, GraphQL, Neo4j and Hyperledger.
Polley Wong – This Week’s Featured Community Member

She’s been hooked on Neo4j since the beginning of the year and loves the stack so much that she developed and is teaching classes. Most recently her first group of students (>50% women!) finished the 8 sessions of her course at openupsummit just this weekend. Polley also joined our Neo4j speakers program to present about the power of graphs at conferences. She’s also planning to stream live coding with GraphQL and graphs, which we’re very excited about.
Thanks so much Polley for spreading the graph love
NODES 2019: It depends and why it’s the most frequent answer to modelling questions
This week’s video from the NODES 2019 conference is by Luanne Misquitta about graph data modelling.
In the talk Luanne shows four different ways of modelling the movies graph that ships with Neo4j. Luanne goes through each of the models, explaining the use case where that model would make sense, and then concludes with a handy cheat sheet of modeling advice.
Game of Thrones: Community detection through time using the seed property
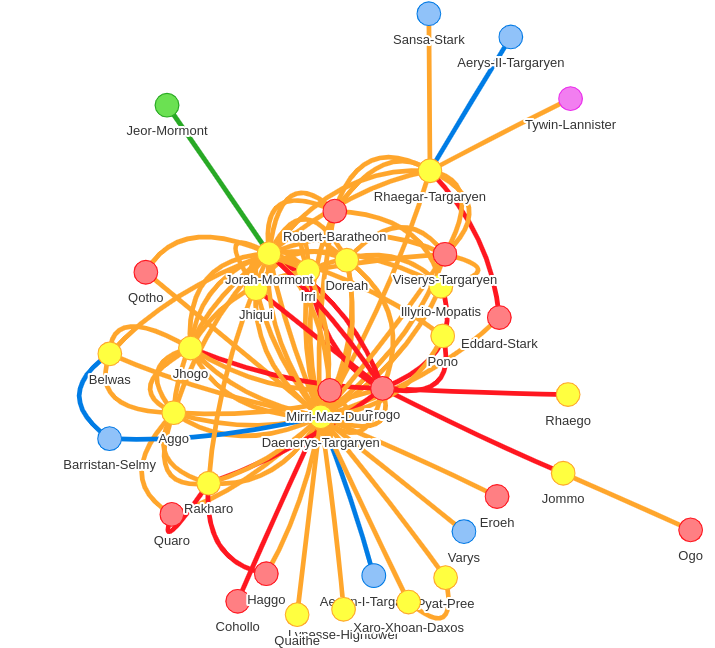
Tomaz Bratanic continues his series of posts about new features in the graph algorithms library.
In the latest post he explains how to use the seed property parameter supported by the community detection algorithms, with the help of a Game of Thrones graph.
Analysing network traffic, new NeoSemantics release, Decision Trees with Neo4j
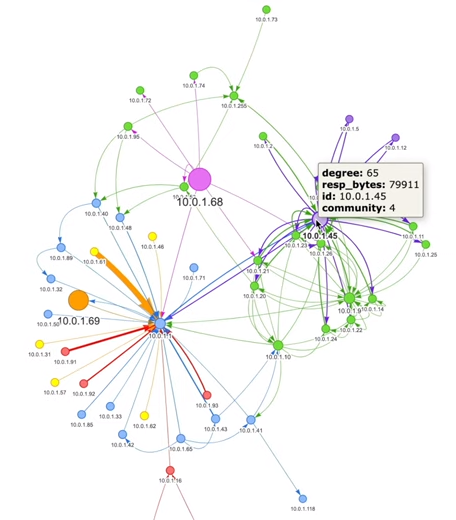
- I really enjoyed Alex Woolford‘s short video showing how to use Zeek, Kafka, and Neo4j to analyse the traffic on your home network. It’s certainly given me some ideas for a new weekend project.
- Aaron Fenwick has been using Neo4j and Scapy to visualise PCAP network traffic files. Aaron shared a GitHub Gist that contains a script to parse these files into a graph.
- Jesús Barrasa released version 3.5.0.4 of neosemantics, a plugin that enables the use of RDF in Neo4j. This release Includes a number of additional procedures and functions, including utility methods and others that complete the existing import/delete capabilities when RDF is passed as-payload instead of by-reference.
- We created a new developer guide this week showing how to deploy a GRANDstack application onto Neo4j AuraDB, a fully-managed cloud database developed by the same people that built Neo4j.
- I came across Manoj Mahalingam‘s thepill, a decision tree evaluation plugin for Neo4j. The latest release adds support for step by step traversal of trees.
QuickGraph #9: The fashion Knowledge Graph. Inferencing with ontologies in Neo4j

In the latest post of Jesus Barrasa’s popular QuickGraph series, we learn how to build a fashion knowledge graph.
In this post Jesus shows how to build a graph containing both a product catalogue from a popular UK retailer and a clothing materials ontology. By connecting these two graphs, Jesus teaches us how to run multilingual semantic searches on the product catalogue.
Carrefour Graph: Part 1 – Playing with shopping receipts

Rik has started a new series of blog posts based on data from a coding challenge for Carrefour, a big French retailer.
In the first post Rik explains how he wrangled the data into shape, and then provides step by step instructions for using various APOC procedures to import the data into Neo4j. The scripts used in the blog post are available in a GitHub gist.
Tweet of the week
My favourite tweet this week was by Geoffrey Mahugu:
In ❤️ with #Neo4j queries pic.twitter.com/nmFEg088gN
— G-Overwatch ?? (@GeoffreyMahugu) November 24, 2019
Share Article



Explore
Related Articles

This Week in Neo4j: Knowledge Graph, Life Sciences, GraphRAG, NODES, Startups and more

This Week in Neo4j: GraphAware, Architecture, Knowledge Graph, AI Agents and more



