
This Week in Neo4j – GDS 1.7 Features, Knowledge Graph with Spark and Neo4j, Digital Nomad Travel Logs, Link Predictions, Load Data Into AuraDB

DevOps Engineer, Neo4j
3 min read

Hello, everyone!
As we begin a new quarter – and enter the spookiest month of the year – Twin4j brings you both tricks and treats from the past week in the world of Neo4j.
In this issue, we will see Link Prediction pipelines in focus as we release the new version of GDS.
Read about the new features in Neo4j GDS 1.7 and learn how link prediction pipelines can be used to discover travel patterns of digital nomads.
Michael Hunger shows us how to load dump files into Neo4j AuraDB from different sources, and we also have an in-depth article about Neo4j performance architecture, as well as some tuning tricks by Benjamin Guegan.
And for those readers interested in knowledge graphs with Spark and Neo4j, we have a good article by Emre Varol demonstrating how you can get started.
Finally, we also launched a new course on our GraphAcademy learning platform. You can learn Graph Data modeling best practices, refactoring, and better understand how modeling works in your graph databases.
Cheers,
Max Andersson
Featured Community Member: Sixing Huang

Sixing Huang – This Week’s Featured Community Member
Dr. Sixing Huang is a German bioinformatician who lives in Shenzhen and works at MGI(BGI).
Originally from China, he studied and got his PhD in Germany and continued to work for different research institutions.
Though he started out as an application developer, he moved more and more into cloud and architecture topics, becoming interested in Microservices and deep into DevOps. He then expanded his knowledge into data science, machine learning, graphs, and data engineering.
When not working he loves to travel the world (hopefully again soon) and is learning Japanese.
As a Neo4j Certified Professional, Sixing has written a number of informative articles about using graphs and Neo4j.
The topics span from using Genome Clustering, Disease Analytics, and Enzyme GraphQL APIs all the way to exploring the Bollywood movieverse.
Thank you so much Sixing for all your amazing articles! Please keep them coming, and good luck on your well-advanced journey into the analytics space.
New Features in GDS 1.7.0

Neo4j’s GDS 1.7 release introduces machine learning pipelines for graph native link prediction. Link prediction is valuable, but we heard you when you said it was hard! In this release, we made things easier for you by adding the ability to define link prediction pipelines. A pipeline lets you define all the steps you want to take to build your predictive model, assembles them into a workflow, and then enables you to apply those defined steps to data to train your best model.
Neo4j introduces link prediction pipelines to make model-building more accessible and less error-prone. We added progress logging and system monitoring to make it easier to monitor the status of your workloads and the utilization of your instances.
System monitoring is a new enterprise feature that takes observability to the next level – a simple command to reveal your team’s utilization of resources on a shared system.
As of GDS 1.7, you can query your graph projection with Cypher! String Support for Graph Export (both for exporting CSVs and creating new databases) Approximate Maximum K-Cut is an assignment of nodes in a graph into k-disjoint communities. The idea is that you want to maximize the number of relationships across communities – the opposite of a typical community detection algorithm.
Travel Pattern Discovery of Digital Nomads
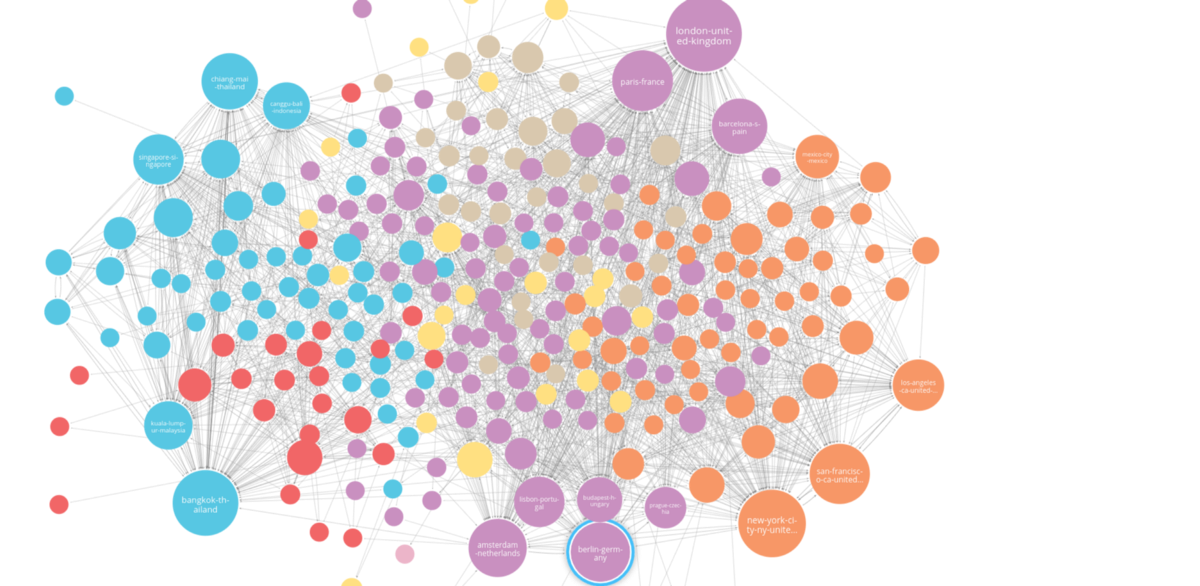
Being a digital nomad myself, this article written by Tomaz Bratanic about travel patterns of digital nomads stood out to me. Digital nomads are a group of people who travel to different places in the world and take their job with them, allowing them to have an exciting work-life balance. But where do they go?
By analyzing travel logs of digital nomads with Neo4j Graph Data Science, we can find some patterns in the dataset provided by Nomadlist. The data is available for the top 50 cities per continent. The next step is to use the new Link Prediction Pipeline to predict new connections in a graph.
New Course: Graph Data Modeling
This week, we are happy to announce our new course: Graph Data Modeling. Perhaps you had some experience with Cypher or have already taken our Cypher fundamentals course, but you are not sure how to use it to build a graph database model. Then this course is for you.
The course covers the concepts of graph modeling and how to refactor an already existing graph database model.
Start Learning – Graph Data Modeling
Neo4j Performance Architecture and Tuning

Benjamin Guegan wrote about how Neo4j performance architecture works and shared some tricks on tuning your graph to optimize performance. He digs deep into concepts like the query processor, execution engine, and how the physical structure of nodes affects performance.
If you’re interested in understanding more about Neo4J performance and architecture, then this is something you should read.
Learn About Performance Architecture
Creating Clinical Knowledge Graph with Spark NLP & Neo4j

This blog post will show you how to create a basic Knowledge Graph using Spark NLS using Neo4J.
Spark NLP is an open-source NLP library under the hood of Apache Spark and Spark ML. It provides a unified solution for all NLP needs by an easy API to integrate with ML Pipelines.
Getting Dumps and Example Projects Into AuraDB Free
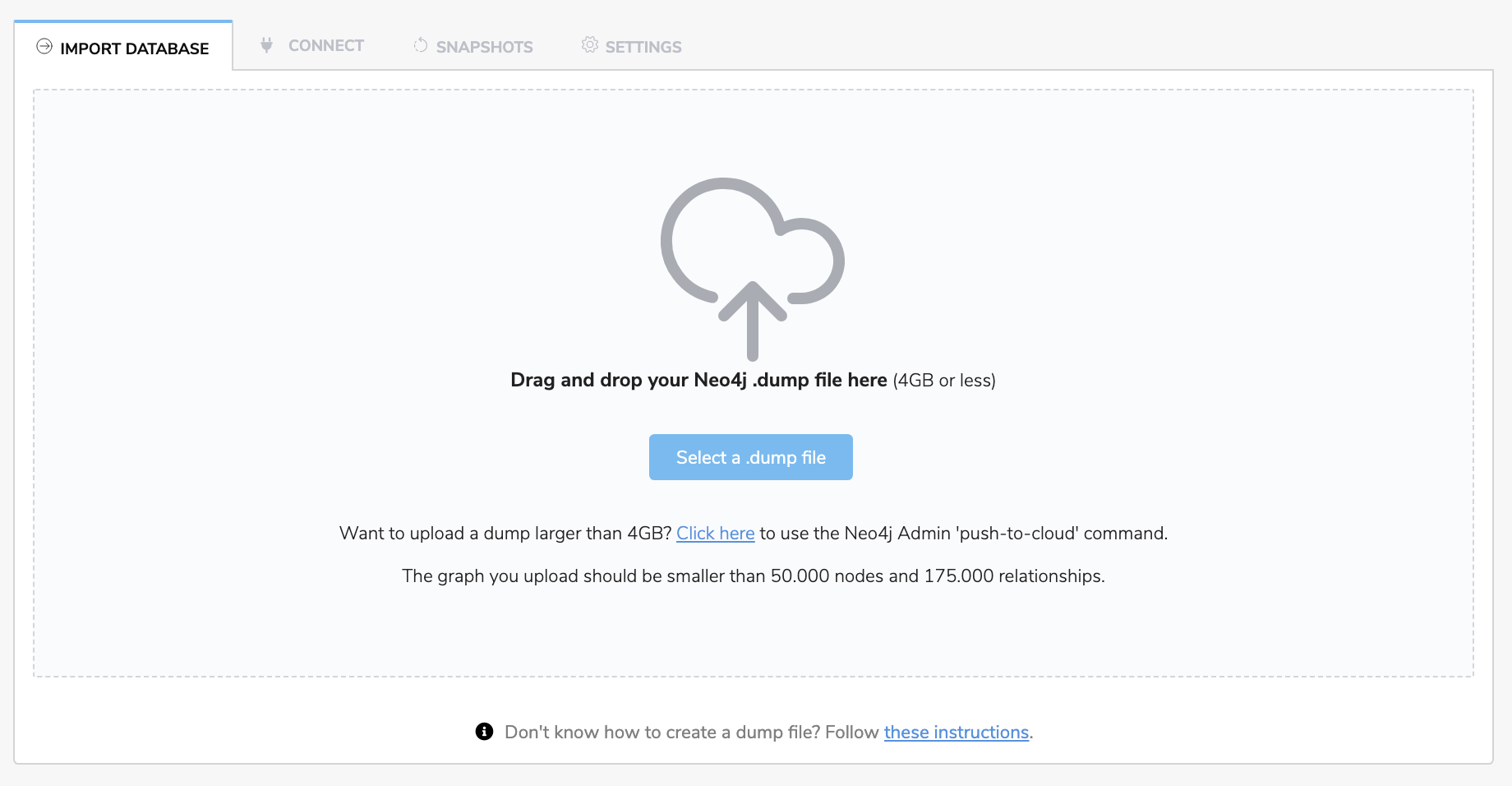
Regardless of where you start your graphista-journey, moving your data into AuraDB Free is a great way to move on to the next step towards a production solution with managed Neo4j in AuraDB.
Michael Hunger will show you how to get your dump files loaded into AuraDB from Sandbox, Neo4j desktop, or an example dataset in this blog post.

A Deep Dive into Neo4j Link Prediction Pipeline and FastRP Embedding Algorithm
Learn how to train and optimize Link Prediction models in the Neo4J Graph Data Science library to get the best results.
Link Prediction pipeline combines node properties to generate input features of the Link prediction model.
In this blog post, we get to explore FastRP node embeddings to define initial node features.
Tweet of the Week
Pandora Papers continues to make a difference in the world.
My favorite tweet this week was by Neo4j:
600 journalists & the @ICIJorg continue to rely on Neo4j for the world’s largest-ever journalistic collaboration — the #PandoraPapers. https://t.co/LeKFDHutij
? Please join us in congratulating the valued contributors and investigative journalists. pic.twitter.com/DSlMc5n7Gn
— Neo4j (@neo4j) October 5, 2021
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



