
This Week in Neo4j – Graph Embeddings, Reddit, jQAssistant, Helidon, Corporate Data, Query Tuning

Curriculum Developer at Neo4j
2 min read

Hello, everyone!
In this week’s episode, Tomaz Bratanic teaches you how to visualize graph embedding algorithm results in NEuler. Ümit Kaan Usta has developed a Reddit Detective Python application that can be used to discover potentially problematic data in Reddit. Dirk Mahler has developed the jQAssistant application where Neo4j helps to identify problems in your software architecture. Paul Parkinson from Oracle published a blog that shows how to use Neo4j as a datasource in a Helidon Microservice. Rebecca Rabb posted a blog about how graph data models are necessary for corporate data.
In addition, we have included a link to the Advanced Query Tuning training session that Mark Quinsland presented last year.
Cheers,
Elaine and the Developer Relations team
Featured Community Member: Chris Hay
This week’s featured community member is Chris Hay.
Chris Hay – This Week’s Featured Community Member
Chris has developed and architected applications for IBM and has discovered Neo4j. He has created this excellent 30 minute video to get you started using Neo4j. In the video, he shows how easy it is to download and create a Docker instance of Neo4j. He steps you through how to create nodes, relationships , and properties in the graph, as well executing queries. Then, he goes further by showing you how easy it is to create a data model in Neo4j that supports a software supply-chain application. You can definitely use some of the points in this video to imagine how you could model a financial application where fraud detection is necessary. We like how Chris shows how easy it is to get started modeling your data with Neo4j.
Thank you Chris for creating such a great video!
Visualizing Graph Embedding Algorithm Results in NEuler
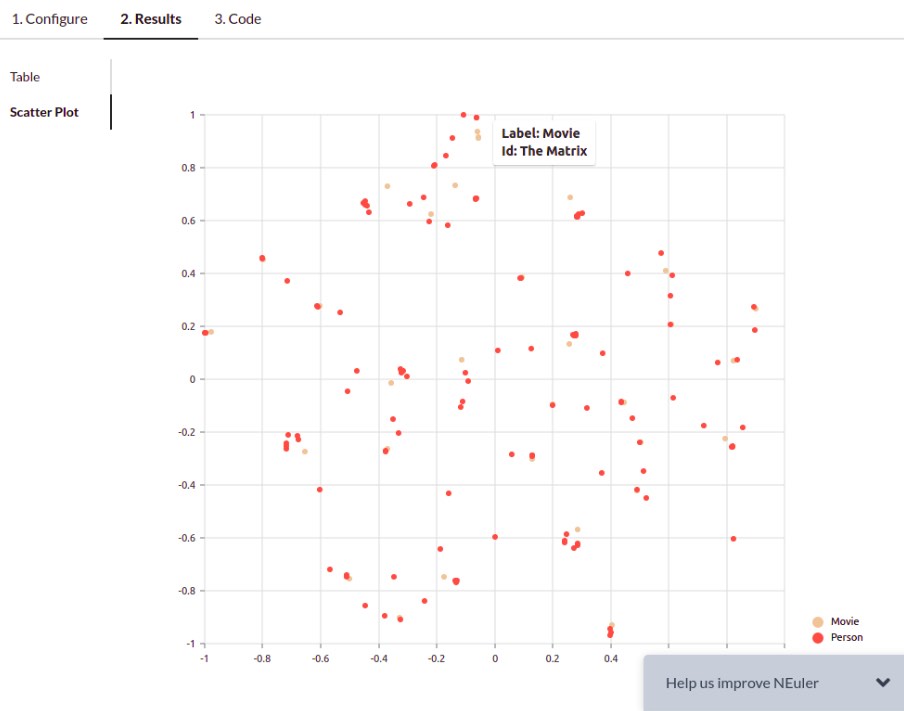
Tomaz Bratanic published a tutorial that teaches you how to execute and visualize graph embedding algorithm results in Neo4j’s Graph Data Science Playground application, NEuler. NEuler is an excellent tool for data scientists that can be used with Neo4j Desktop or a Neo4j Sandbox. In this tutorial, he steps you through loading the data through visualizing graph embedding results with the t-SNE scatter plot.
Play Detective on Reddit
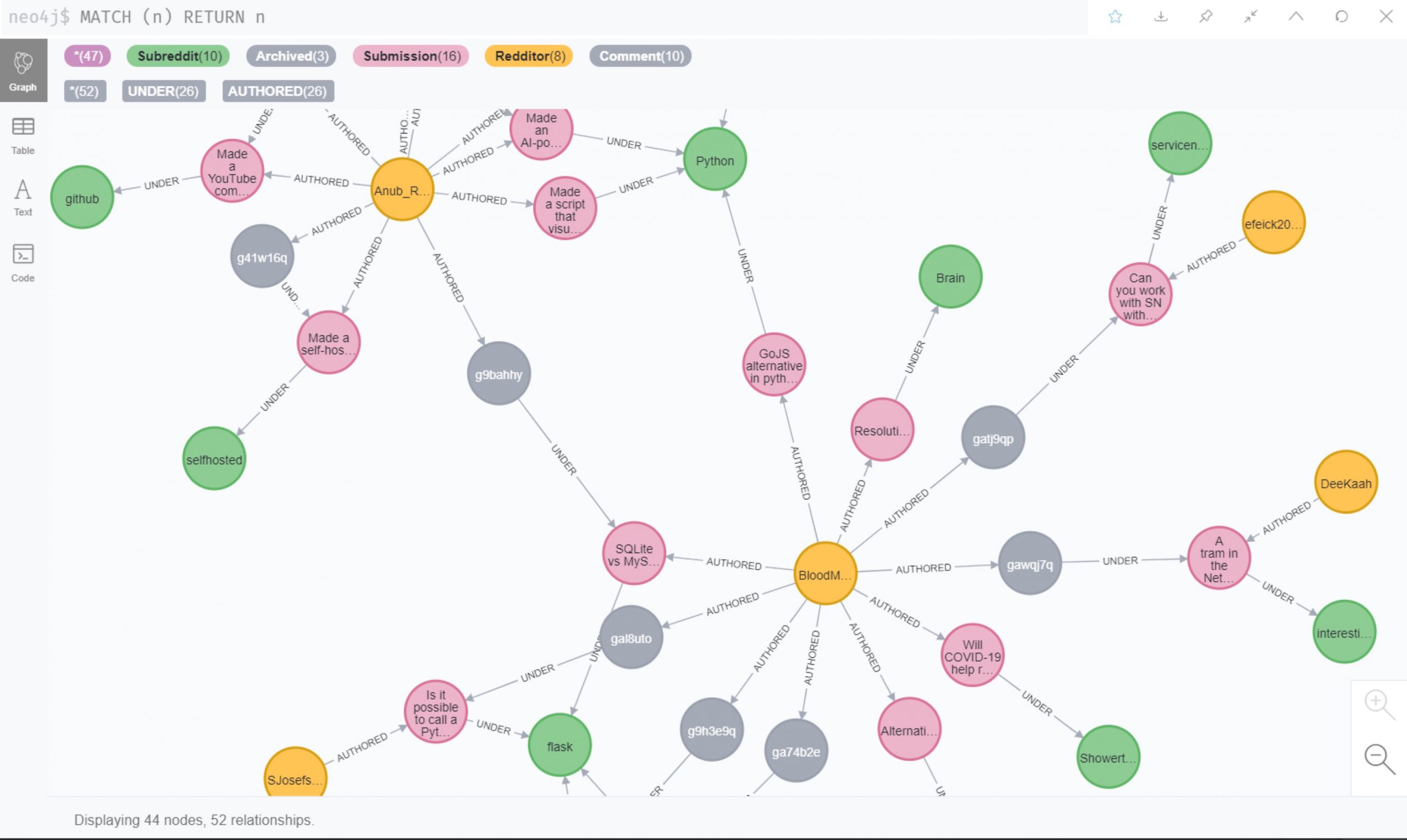
Ümit Kaan Usta created a Python application that loads a graph with Reddit data and enables you to look for political disinformation campaigns, secret influences, and more. With this application, you can:
- Detect political disinformation campaigns.
- Find trolls manipulating the discussion.
- Find secret influencers and idea spreaders (it might be you!).
- Detect “cyborg-like” activities.
jQAssistant to Improve your Software Projects
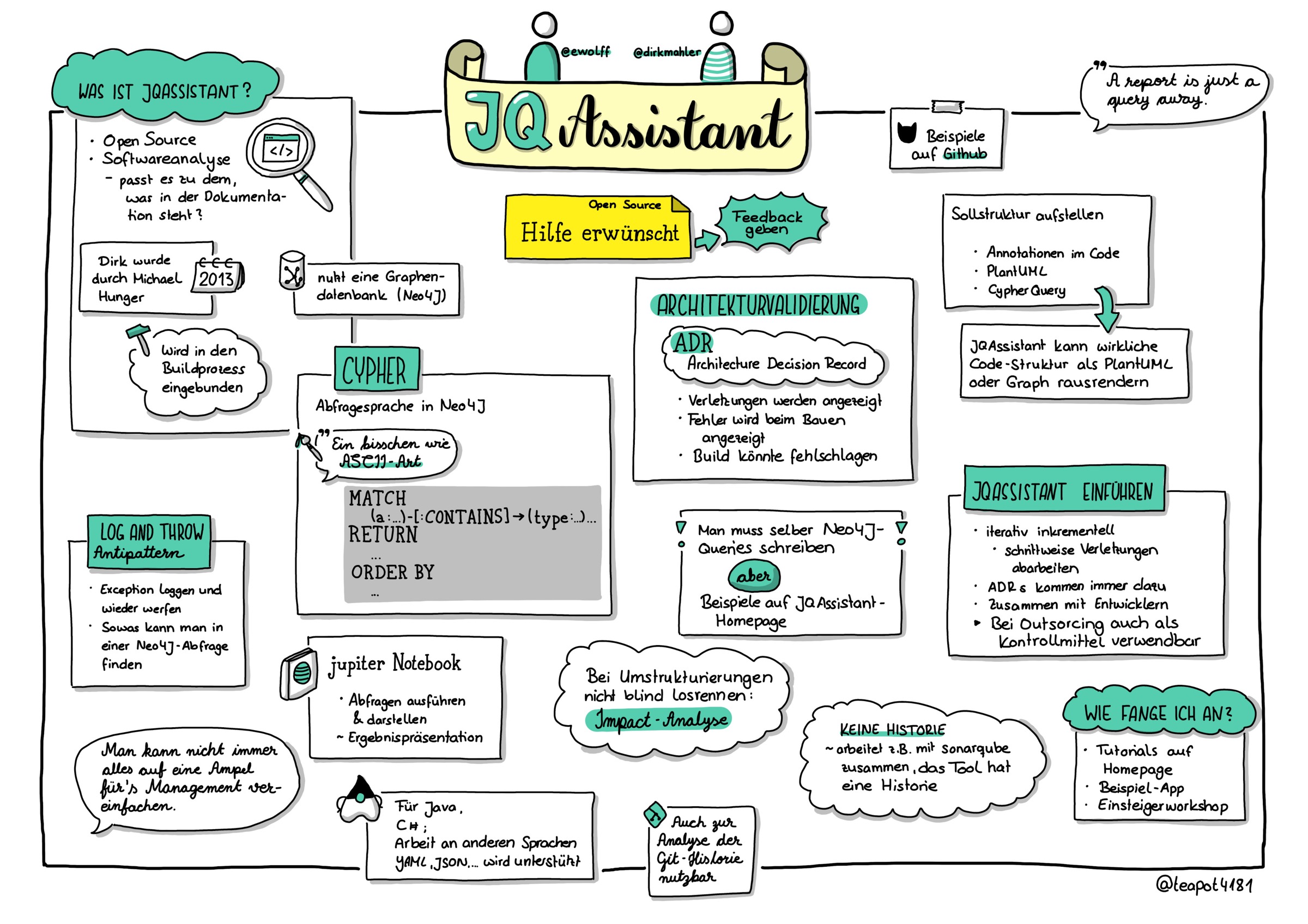
Dirk Mahler and a group of other developers have been working on an open-source project called JQAssistant.
jQAssistant is a QA tool, that allows the definition and validation of project specific rules on a structural level. It is built upon the graph database Neo4j and can easily be plugged into the build process to automate detection of constraint violations and generate reports about user defined concepts and metrics.
Example use cases include:
- Enforce naming conventions, e.g. EJBs, JPA entities, test classes, packages, Maven modules etc.
- Validate dependencies between modules of your project
- Separate API and implementation packages
- Detect common problems like cyclic dependencies or tests without assertions
Using Neo4j as a Data Source in the Oracle Helidon Microservices Platform

Paul Parkinson who is the Data and Transaction Processing Development Lead for the Helidon Microservices Cloud Platform at Oracle has written a blog about using Neo4j as a data source for a microservice. Helidon is an open source project funded by Oracle. It is a collection of Java libraries for writing microservices that run on a fast web core powered by Netty. This blog illustrates some of the ways you can integrate with the microservices architecture, including using Neo4j as a datasource.
The Power of Storing Corporate Data in a Graph Database

Consultant Rebecca Rabb for Graphable.io, posted this blog which describes how corporate data is much better served from a graph database, rather than other types of databases. Companies execute their business operations because of their connections to other companies. The only way to reasonably represent these connections is a graph. Rebecca presents two different use cases where graphs are the best solution. You can follow Graphable at @Graphable1.
Training Session (recording): Advanced Cypher Query Tuning

Last year, we held virtual advanced hands-on training sessions for our Certified Neo4j Professionals. This 4-hour recorded session was given by Mark Quinsland where he presented his tips and tricks for Cypher Query Tuning. Here are the topics in this session that Mark presented:
- Profiling slow-running queries
- Methods for improving Cypher performance
- Data modeling alternatives for improving query performance
- Lesser-known Cypher features for better performance
- Improving speeds for loading CSV files
- How and when to use indexes
Nodes 2021: The Largest Graph Dev Conference Is Back!

Reserve your spot now for NODES 2021, designed for developers to bring their graph database skills to the next level. This is a free event that will be held on June 17th.
You can register here.
Tweet of the Week
My favorite tweet this week was by William Lyon:
Starting to look at protein interactions in #Neo4j
These are the interactions among proteins known to be related to cancer in humans visualized in @neo4j Bloom. pic.twitter.com/G2WsE2FhuV
— William Lyon (@lyonwj) May 13, 2021
Don’t forget to RT if you liked it too!
- Analytics
- application architecture
- corporate knowledge
- cypher
- Cypher Query
- Cypher query tuning
- data modeling
- fraud analysis
- graph algorithms
- graph embedding
- graph visualization
- helidon
- java
- jqassistant
- neo4j
- neo4j docker
- nosql
- Oracle
- social media
- software quality
- streaming data
- supply chain
- twin4j
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


