Webinar follow-up: RDBMS to graph

Head of Product Innovation & Developer Strategy, Neo4j
10 min read

First of all thanks so much for attending the webinar or now reading up on what I spoke about. We got an overwhelming number of questions which we couldn’t all answer in the short time.
That’s why we want to follow up here, answering those questions and also providing access to the webinar recording and the slides of the presentation.
Introduction to Neo4j & graph use-cases
In the webinar Ryan quickly introduced Graph Databases and Neo4j as well as common use-cases. He spoke about the differences to relational systems and how graph databases address many pain points of a relational database like join-performance, data modeling complications and schema evolution, while keeping important attributes like the transactional model, fine grained, flexible data model and a fast, declarative query language for ad-hoc and programmatic database interaction (in our case Cypher).
Neo4j browser
Ryan demonstrated the Neo4j Web interface which is an interactive, modern web-application a nice difference from usual database UIs. It allows you both to query the database and visualize the results as well as to visually navigate the graph.
The new live examples for both the Movies Graph but also the relational classic Northwind make it easy to get started.

NorthWind example
Using the Northwind example Ryan explained how to transform the existing relational model into a graph model that we then can import data into.
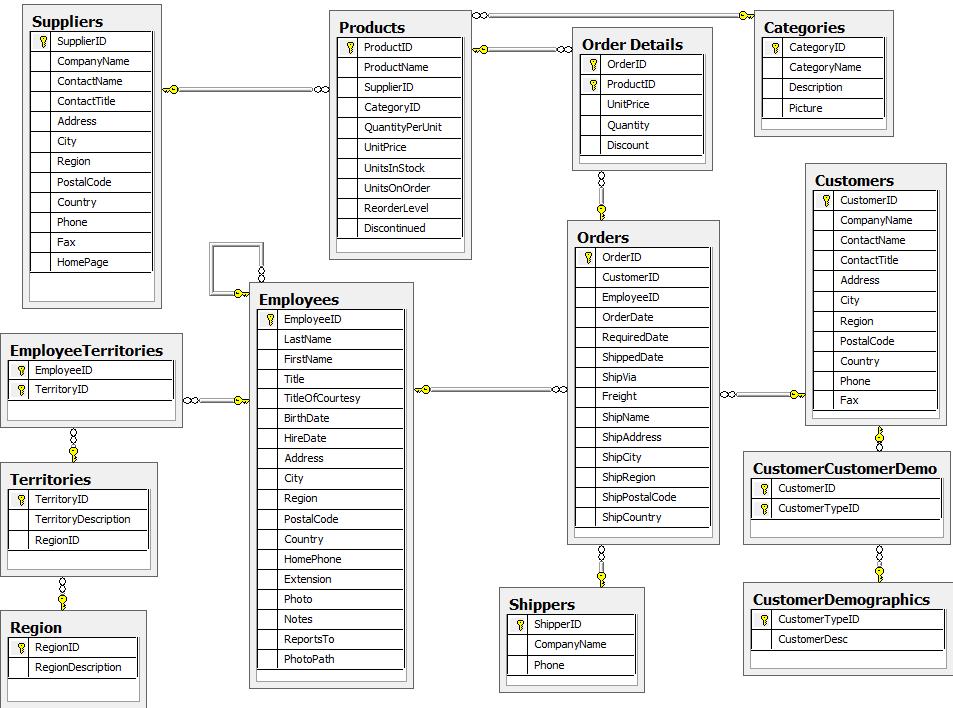
NorthWind Relational Database Model
For the import Ryan demonstrated the LOAD CSV facilities of our Cypher query language, that allow you to create nodes and relationships from the data provided in CSV dumps.
After importing the data and setting up a few indexes for faster lookups, Ryan demonstrated how you can run interesting and more complex graph queries on that well known dataset to retrieve new and surprising insights.
Your questions
Question: Is Neo4j ACID database?
Answer: Yes Neo4j is fully transactional as the graph model is a fine grained datamodel like the relational model.
Question: Can you please explain a bit on Bulk data upload via command line? what’s the data format it accept?
Answer: It is CSV data which might be split across multiple files and compressed. See the Manual for more details.
Question: Are there any graph analysis algorithms pre-built queries in cypher ?
Answer: In cypher we currently bundle shortest-path algorithms, more are planned for the future as well as user-defined-functions which will be suitable for iterative algorithms. There are also libraries for SNA and neo4j on GitHub from the Java-API.
Question: What are the best ways for saving dates in Neo4j – For example the since property for Dan Drives Car
Answer: There are some options: you can store it as long value (seconds or ms since epoch) or as ISO formatted string. We plan to introduce real date, datetime, time types and functions in one of the next versions of Neo4j.
Question: Strikes me graph structures & concepts would be a lot easier to explain to a non-technical audience (e.g. clinicians in my case). Do you find that to be true? Any examples?
Answer: Yes that’s true as you have no mental model difference between the whiteboard model, queries, query results. Oftentimes non-technical people can easily point out insights, issues in the models or queries because they naturally understand them.
Question:Is there any best practices for architecture design (or any patterns, eg to mix analytics and operational relationships) ?
Answer: Yes, we have a classroom course on graph data modeling which goes into detail. You can also check out the free ebook “graph databases” on graphdatabases.com
Question: How does the learning curve for Graph Databases/Neo4j compare to SQL or noSQL databases?
Answer: With our easy to understand data-model, and query language as well as the interactive Web-UI online resources getting up and running is really quick, it shouldn’t take more than a few hours. For deeper understanding and support our active community can help you to come
Question: I am not sure how i would get data into the graph database. Is it only through the API or is there a facility in the management panel for doing CRUD
Answer: As Ryan said there are CSV loading mechanisms, there is also a simple form based tool in the Neo4j browser.
Question: How does Neo4j deal with RDF data and why use it instead of a “real” Triple store? (assuming that integrating in a semantic web system is not needed, because it should be used in enterprises)
Answer: The property graph model is closer to the object model and the real-world, as it models attributes as properties and only semantic relationships as connections. So RDF is a fully normalized form which is often an overkill and harder to understand / slower to query.
Question: How would a data model as well as the data import look like to support historical dimensions?
Answer: There are a number of ways handling historical data, we have some examples in the manual but also for instance at iansrobinson.com we also teach this in our data modeling class. One example is to store time information or versions on nodes and relationships and use that when you retrieve the data.
Question: How about .NET drivers?
Answer: See the Neo4j DotNet Page there are also newer ones in development.
Question: Where/Who should I look to to get info on this spatial functionality feature and timeline plan?
Answer: Neo4j spatial is currently a separate project, hosted at neo4j-contrib but to be integrated into Neo4j. We can’t make definite statements about the timeline but we want to get it in as soon as possible.
Question: Is there any plan or timetable for support of Neo4J-Spatial?
Answer: We have a plan of integrating spatial functionality into core Neo4j and Cypher including spatial types and functions.
Question: Hi Ryan, Do we have any Certifications available for Graph Databases Neo4j Cypher?
Answer: We offer classroom trainings for Cypher, Graph Modeling, Data Import and more. If you attend one of those you’ll be certified.
Question: How it supports replication?
Answer: Neo4j supports clustering for Master-Slave replication and High-Availability failover.
Question: Hi Ryan, great presentation? Any classroom training scheduled to take place in London in near future? Thank you.
Answer: Yes we have regular training classes in London, check out our GraphAcademy page for upcoming courses or ping us.
Question: I have a node, properties are serial number , description node can have a couple of labels Product MasterProduct SupplierProduct All nodes will be labeled Product Most will also be labelled MasterProduct Some will be labelled SupplierProduct (can not be labelled both Supplier and Master) How would I index my model?
Answer: You would create an index or constraint on :Product(serialNumber)
Question: Can you query from and export data to a separate Java application?
Answer: Yes, we have drivers for all languages including Java and Spring.
Question: Can you integrate the graph viewer into an application?
Answer: Not yet, we’re working on that for the future. There are also other tools as Ryan mentioned.
Question: Is Neo4J available as a built-in service in any cloud providers like MySql is? Is this on the roadmap? This is a barrier to adoption.
Answer: We have partners like graphstory.com and graphenedb.com providing Neo4j as a service as well as cloud formation templates and docker images, listed on our developer pages. If you have more questions there just drop us an email
Question: How would you use the Cypher language commands to rename a relationship. For example, can you show us how to rename the the “order detail” relationship to “contains”.
Answer: There is no direct renaming facility. You could recreate the relationship with the new name and copy the properties over.
MATCH (a)-[old:`order detail`]->(b)
CREATE (a)-[new:contains]->(b)
SET new = old
DELETE old
Question: Could we have the sample data used in this demo, to work with ourselves please?
Answer: It is actually part of the Neo4j Browser (:play northwind graph) you see the source CSV urls as part of the cypher statements.
Question: Can the ‘Chocolade’ check be made in a Where clause? If so, what are the decisions in placement/use?
Answer: Yes, actually internally it’s rewritten into a WHERE clause. The curly brace syntax is just a shorthand
Question: Any example code for the bulk loader ?
Answer: There are detailed examples in the Neo4j Manual.
Question: Can we change the style of the graph?
Answer: Yes you can change the style (size, color, caption) per node-label and relationship type visually. If you want to edit the stylesheet (open viewer with :style) you can do even more.
Question: Does it work well for storing pictures?
Answer: No, binary data is not handled (yet) you’d usually store in in a key value store, filesystem or s3 and store the URI to the resource. This will be addressed in one of the future releases.
Question: Is it possible to create relationships visually using the Neo4j browser. I think it would be more intuitive to create relationships visually rather than write relationships using cypher statements.
Answer: There is a small form based tool integrated in the browser, we plan for a more interactive tool in the future. There are other third party tools that allow visual data creation (e.g. linkurio.us)
Question: Does Neo4j support substring search within text properties (similar to “like ‘%cat%’ in SQL)?
Answer: Neo4j’s Cypher supports regular expression search (which is not yet index powered) and full-text search via manual lucene indexes. We plan to add full index powered ILIKE search in one of the next versions of Neo4j
Question: Can we get a sense of the enterprise pricing model?
Answer: Please see our Subscription page and contact us for details and a tailored solution for your use-case.
Question: Could the property value by used to store JSON/XML for serialize/deserialzing objects?
Answer: You can store XML and JSON as strings and deserialize in your client. Oftentimes people actually deconstruct documents into graph structures for easier querying and projections.
Question: Just noticed the answer stating binary data not supported. What is the capacity of a value in the name-value property pairs?
Answer: Binary data is supported (byte arrays) but not large volumes, so data representing for instance 10 to 100k is no problem but it is not as efficiently handled as other data.
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles



SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


