Welcome to the Graph Community, Amazon Neptune!

CEO & Co-Founder, Neo4j, Inc.
5 min read

This post originally appeared on Emil Eifrem’s CEO blog on 1 December 2017.
Graph technology has come a long way, and today the transformative nature of graphs is publicly visible through examples such as financial fraud detection in Panama and Paradise papers, contextual search and retrieval of historical information in NASA’s knowledge graph and the use of conversational ecommerce in eBay’s Shopbot.

The Growing Graph Database Space
When I look back to a decade ago, it was just us and some hobbyists in the graph technology space until five years later when other graph database startups started to emerge. And since then we’ve watched the graph space grow as mega-vendors like Oracle, Microsoft, SAP and IBM introduced graph products of their own.
I always found Amazon’s absence from this list ironic given that their business models in both ecommerce and data centers on tap are graph-based disruptions. Amazon Neptune signals the arrival of graph database technology into mainstream ecosystems, both in the cloud and on prem. As evangelists of the graph database category, we helped pioneer, establish and propel this space, and we are both proud and elated to see it transform and grow this way.
Amazon’s entry into the graph database market adds to an increasingly large palette of choices for end users, and I believe it is part of a rising tide to lift all boats. As with all markets, more competition and more choices will lead to a stronger market and better products. Ultimately, the end users of graph technology will benefit.
The Game Is Only Beginning
Now that all of the major database players have jumped on the graph database bandwagon, you might rightly ask, what’s next?
It’s to me clear that the game is only beginning. Part of this is obvious: While we at Neo4j have invested over a decade in our native graph database, many of today’s offerings are brand new, or (like Neptune) not yet GA.
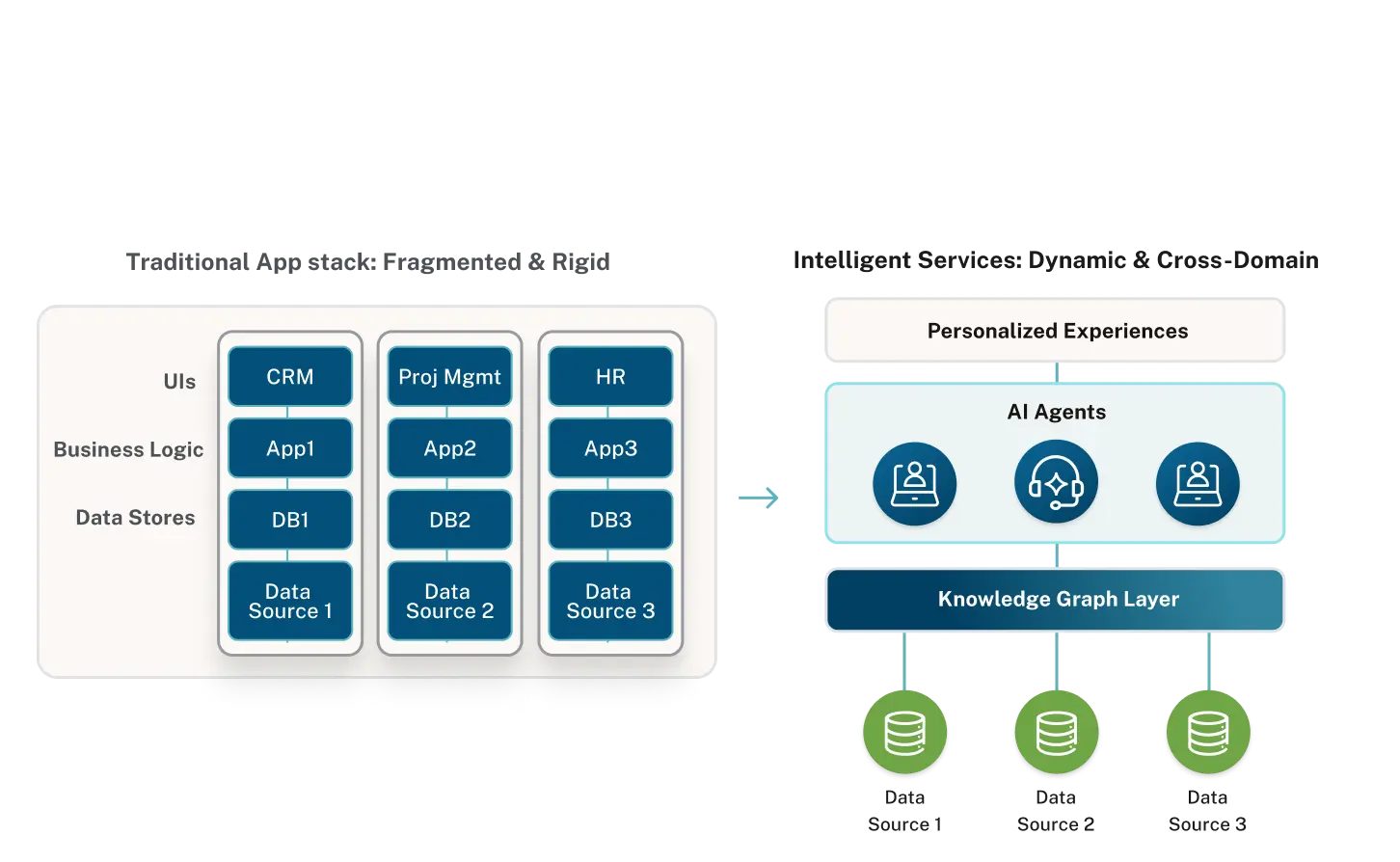
More broadly, it’s clear that we’re still just scratching the surface of what a graph-powered solution is. While a database like Neo4j or Amazon Neptune is a foundational element of a graph technology stack, integration with different types of data sources, comprehensive graph analytics, easy-to-use graph visualization tools and purpose-built graph-based applications will be essential for broadscale adoption.
The Neo4j Graph Platform announced in my GraphConnect New York keynote describes our own efforts to chart the next decade of evolution in the graph technology space by offering a graph platform.
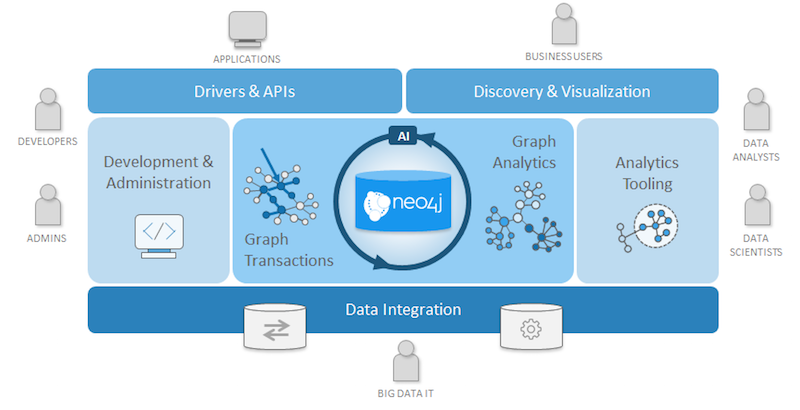
The Neo4j Graph Platform
That’s the first piece.
Coalescing around a Query Language
Second, to achieve adoption that mirrors that of the venerable RDBMS, we also need a standard graph query language analogous to SQL that is simple as well as easy to learn and implement. As more users learn about graph technology and as more tools and vendors enter the graph space, we’re at a time when a shared, declarative graph query language – agnostic of vendor or platform – will be a massive benefit to both vendors and users.
After trying nearly every other approach, I continue to believe that Cypher is this standard. Why? Because in addition to years of real-world validation, it has by far the widest adoption among actual graph end users.
As a quick data point, consider an issue count on Stackoverflow comparing “Cypher” (17,000+) to “Gremlin” (3,300) or “Tinkerpop” (1,200). I believe 80+% of all graph applications today use Cypher. Nothing else comes close.
So our bet is on Cypher as the SQL for graphs. And it’s our strong belief that an open language will lead to the best result for end users: so much so that in 2015 we broke Cypher out of Neo4j and donated it to the openCypher project, whose governance model is open to the community.
The openCypher project makes Cypher available to any technology as the easy, standard graph query language. So far – besides Neo4j – databases like SAP HANA, Redis Graph and AgensGraph, among others, have standardized on Cypher, and more are in the works. This is an area where we’d love to work together with Amazon Neptune, to make sure that their users can leverage the most popular property graph query language on the planet.
Another major donation we recently made was an early version of the Cypher for Apache Spark™ language toolkit to the openCypher project. This will enable big data analysts (or any Spark user) to materialize graph data from their data lakes, incorporate graph querying into their workflows, and make it easier to bring graph algorithms to bear throughout their enterprise data investments, dramatically broadening how they reveal connections in their data.
The Graph Community Is Growing
Last but not least, as a graph community, we need to continue to address the fact that demand to adopt the graph paradigm is growing faster than expertise, yielding a skills shortage.
Over the years an amazing community has grown around Neo4j. It now boasts some 55,000 meetup members across 109 meetup groups. Last year, the community organized and attended more than 400 events about Neo4j. (As a side note: that is a staggering number! Think about it: almost two events per working day!).
The broader graph community needs to build upon this momentum to make sure that every developer, data scientist and data architect is skilled in graph technology. With the entry of larger players like Microsoft and Amazon, I feel confident that we (the community) will continue to develop graph skills necessary for large-scale adoption of this paradigm.
At Neo4j we have a single focus: graphs. To date, we have made the industry’s largest dedicated investment in graph technology: resulting in more than ten million downloads, a huge developer community deploying groundbreaking graph applications around the globe and more than 250 commercial customers, including global enterprises like Walmart, Comcast, Cisco, eBay, and UBS. However our work as a company, a community, and as a movement has only begun.
This year has been a massive year for graphs. We are excited to see Amazon Neptune join the graph community, and we look forward to growing the space together with them and with you, connecting one node at the time.
–Emil
Share Article



Explore
Related Articles



Welcoming Kapil Hetamsaria, Our Chief Business Officer for Strategic Partnerships and Alliances

Introducing Neo4j Fleet Manager: One Control Plane for All Your Neo4j Deployments