


BambooHR to Neo4j Integration

Customer Success Engineer, Neo4j
5 min read


BambooHR software collects and organizes all the information you gather throughout the employee life cycle, and then helps you use it to achieve great things. Whether you’re hiring, onboarding, preparing compensation, or building culture, BambooHR gives you the tools and insights to focus on your most important asset – your people.
That company information is often just provided and shown as tables or individual records, but it inherently forms a graph – your organizational structure together with its locations, teams, departments, and more.

BambooHR does provide a REST API as documented, which means we can use Neo4j Cypher along with APOC to extract data from Bamboo and load into a graph.
The examples below will demonstrate how to extract the Employee records from BambooHR and effectively build the graph equivalent of an organization chart.
And once it’s loaded, the data can either be visualized with Neo4j Browser or Neo4j Bloom. With Bloom – and specifically with its usage of Hierarchical Graph Layout – the result will be a traditional Organization Chart layout. It should be noted that BambooHR natively offers a similar visual Organization Chart layout. But in Neo4j you cannot just visualize the data in one way, you can also query, explore, and extend it in myriad ways.
For a graph model we would use these nodes
- Employee
- Location
- Department
And these relationships
- (Employee)-[:SUPERVISES]->(Employee)
- (Employee)-[:LIVES_IN]->(Location)
- (Employee)-[:WORKS_IN]->(Department)
Here is a visual graph model with example data
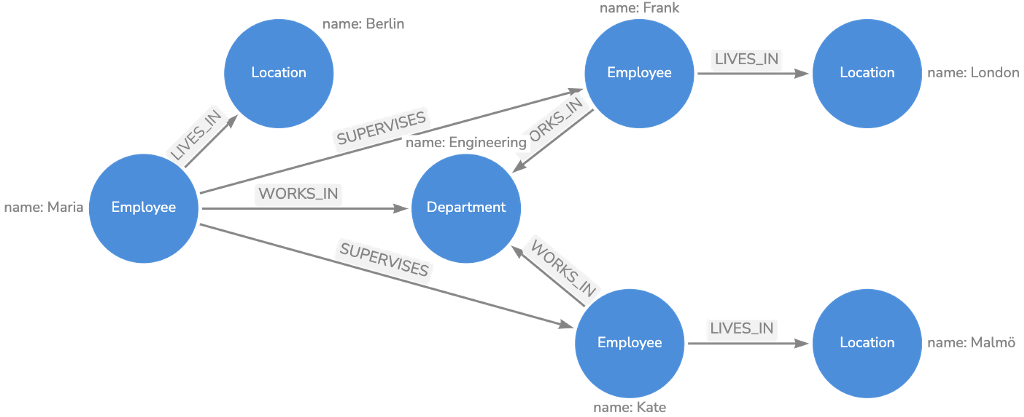
The purpose of the examples below are not to just extract data from BambooHR but also to possibly build out relationships to other data from other sources (email, Slack, etc.).
The example below was constructed using the following software:
- Neo4j version: 4.4.3
- APOC version: 4.4.0.1
- Bloom version: 2.0.0
And for the most part, I suspect Cypher will work with prior Neo4j versions with little to no modifications.
// create schema indexes
create constraint on (e:Employee) assert e.id is unique;
create index on :Employee(name);
create constraint on (l:Location) assert l.name is unique;
create constraint on (d:Department) assert d.name is unique;
Load the data from Bamboo and insert into the Graph Model as shown before. For each piece of data, it creates the nodes uniquely (using MERGE) and the relationships, too. The supervisor field from the API doesn’t contain an id but the display-name of the supervisor, so it might trip up if you have duplicate names.
// consult employee directory
with ‘https://api.bamboohr.com/api/gateway.php/neo4j/v1/employees/directory' as uri,
‘Basic ODI4ZDZmYjViYjNlNmVkYzQ0YmZkNzEyM2Q2YTc0OTlkMzIwOng=’ as bamboo_identifier
CALL apoc.load.jsonParams(uri,
{Authorization: bamboo_identifier, Accept: ‘application/json’},null)
YIELD value
UNWIND value.employees as row
MERGE (e:Employee {id:row.id})
SET e.firstName=row.firstName, e.lastName=row.lastName,
e.workEmail=row.workEmail, e.name=row.displayName,
e.jobTitle=row.jobTitle
MERGE (l:Location {name:row.location})
MERGE (e)-[:LIVES_IN]->(l)
MERGE (d:Department {name:row.department})
MERGE (e)-[:WORKS_IN]->(d)
MERGE (boss:Employee {name:row.supervisor})
MERGE (boss)-[:SUPERVISES]->(e);
If we want to, we can fetch additional information, e.g. the hire-date.
// now GET each employee
MATCH (e:Employee) WHERE e.hireDate IS NULL
WITH e,
'https://api.bamboohr.com/api/gateway.php/neo4j/v1/employees/' + e.id + ‘/?fields=hireDate’ AS uri,
‘Basic ODI4ZDZmYjViYjNlNmVkYzQ0YmZkNzEyM2Q2YTc0OTlkMzIwOng=’ AS bamboo_identifier
CALL apoc.load.jsonParams(uri,{Authorization: bamboo_identifier, Accept: ‘application/json’},null)
YIELD value
set e.hireDate=value.hireDate;
NOTES:
There are 2 references to Basic ODI4ZDZmYjViYjNlNmVkYzQ0YmZkNzEyM2Q2YTc0OTlkMzIwOng= AS bamboo_identifier represents my Bamboo API key. This key is generated from within BambooHR upon clicking on your Profile, in the upper right corner of the BambooH UI, and selecting API Keys.
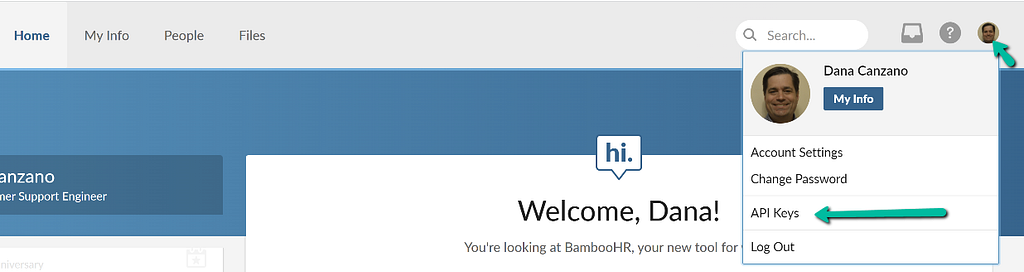
Using the generated key, you then need to base64 encode and append a :x to the key. For example, if the generated key was 828d6fb5bb3e6edc44bfd7123d6a7499d320 then you would need to run:
echo -n 828d6fb5bb3e6edc44bfd7123d6a7499d320:x | base64
And this would result in:
ODI4ZDZmYjViYjNlNmVkYzQ0YmZkNzEyM2Q2YTc0OTlkMzIwOng=
There are 2 references to neo4j https://api.bamboohr.com/api/gateway.php/neo4j/v1/employees/.
That company name or id will need to be updated to the domain of your organization.
Now that the data is loaded into Neo4j what types of queries might we want to run?
How many people work in the “customer support” department?
MATCH (:Employee)-[:WORKS_IN]->(d:Department)
WHERE d.name = ‘Customer Support’
RETURN count(*);
Find all employees who are at most 2 relations from the Chief Executive Officer:
MATCH path=(boss:Employee)-[:SUPERVISES*..2]->(e:Employee)
WHERE n.jobTitle=’Chief Executive Officer’
RETURN path;
Shortest path between me and another employee:
MATCH path=shortestPath(
(me:Employee)-[:SUPERVISES*..100]-(other:Employee) )
WHERE me.name = 'My Name' AND other.name = 'Jane Doe'
RETURN path;
In these days of COVID, find all employees from a given location:
MATCH (e:Employee)-[:LIVES_IN]->(l:Location)
WHERE l.name STARTS WITH ‘San Mateo’
RETURN e.name, n.workEmail;
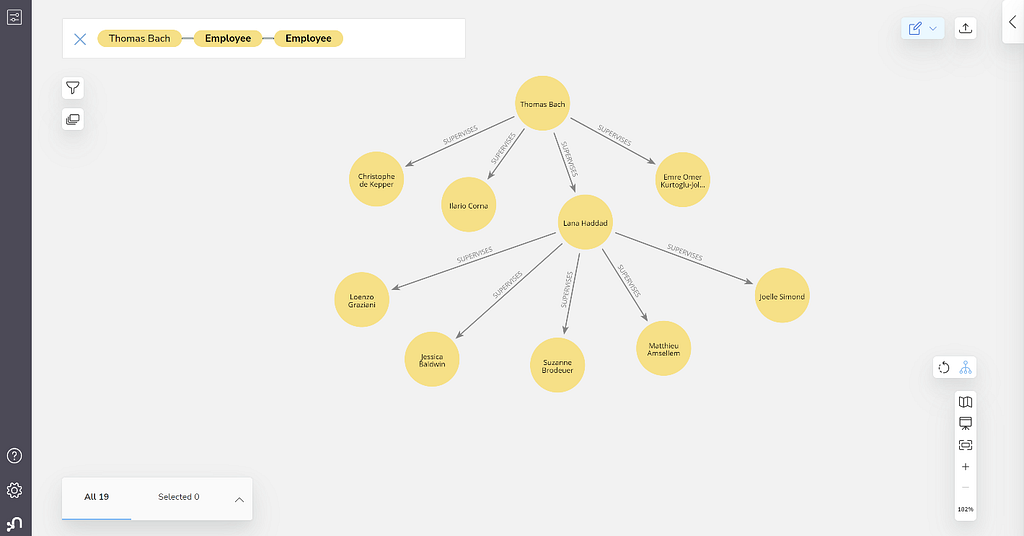
And to demonstrate how the data would appear visually in both Neo4j Browser and Neo4j Bloom – and when using a common dataset – I will effectively use the International Olympic Committee data. I’ve chosen to use this common dataset, as internal employee data cannot be shared.
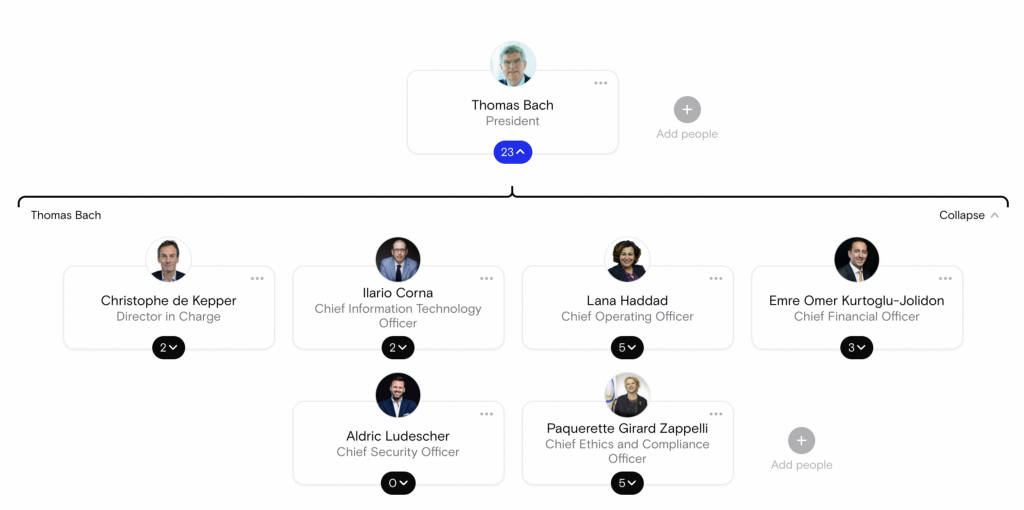
This is what that org chart would look like in a default graph representation in:
Neo4j Browser:
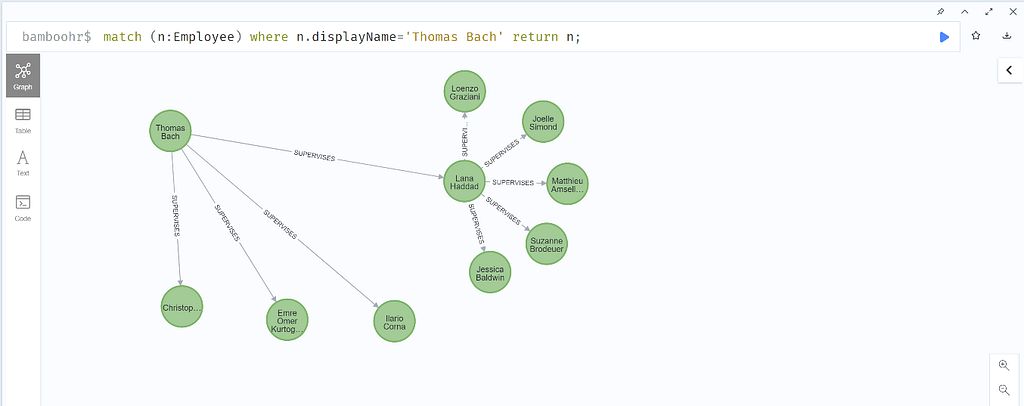
and Neo4j Bloom:
Hope that was helpful. If you are running BambooHR, try it out with your own company’s data and surprise your colleagues with some new insights or visualizations that you could create.
BambooHR to Neo4j Integration was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




