
Behind the Scenes of Creating the World’s Biggest Graph Database

Chief Architect, Neo4j
6 min read

Trillion Entity Demo in Numbers
- 1128 forum shards, 1 person shard, 3 Fabric processors
- Each forum shard contains 900 million relationships and 182 million nodes – the person shard contains 3 billion people and 16 billion relationships between them
- Overall, the full dataset is 280 TB, and 1 trillion relationships
- Took 3 weeks from inception to final results
- Costs about $400/h to run at full scale
“100 machines isn’t cool. You know what’s cool? One trillion relationships.”
I’m not saying that someone actually uttered these exact words, but I’m pretty sure we all thought them. That was a month ago, when we’d decided to try and build the biggest graph database that has ever existed.
We managed to do it in three weeks.
Motivation
When we introduced Fabric, we also created a proof of concept benchmark that was presented at FOSDEM. It showed that, for a 1TB database, throughput and latency improve linearly with the number of shards that it’s distributed across. More shards, more performance. The results looked good and confirmed that we had a very good understanding of the approach to scaling a graph database. Development of Fabric continued toward making it an integral part of Neo4j. New technologies were created and improved upon (server-side routing is a good example) and made useful for non-Fabric setups as well.
But, that 1TB dataset from FOSDEM was always nagging us. 1TB is not big, at least for Neo4j. We routinely have production setups with 10TB or more and, although they run on considerably large machines, Neo4j scales up pretty well. We didn’t really need a solution for that; we needed a solution for really big databases. That’s why we had created Fabric, but we hadn’t yet found its limit.
And what would that scale be? A year ago we built clusters of 40 machines, and they worked out pretty well. Going to 100 machines didn’t seem like that much of a challenge. Billions of nodes, perhaps? Well, billions of nodes is the same as a few TB of data. Plus, the richness of a graph schema comes from relationships between nodes, not the nodes themselves. Remember: We’re trying to see how far we can push Neo4j, not just make ourselves feel or look good.
Every now and then the same discussion would come around, and it was becoming clear that we were looking for an opportunity, a lightning rod, that would ground us in a realistic goal.
Turns out, that opportunity was NODES 2021.
Scale That Demands Attention
We decided that we needed to show the world what we mean when we talk about scale. Not just that Neo4j can retain or even improve performance when scaled horizontally, but to show how far we can go while still retaining performance.
We’re going to need bigger numbers. Something that demands attention. Not hundreds of machines or billions of nodes.
Trillions.
A trillion relationships would do it, right?
Where do you even find a database with a trillion relationships? Using a production setup would present logistics problems – the data transfer itself would be complicated, not to mention obfuscating the data so it’s appropriate for public view. We needed to generate it for ourselves, from a known model. And we knew we needed to start with the data model, since that would give us the number and size of machines, the queries we’d run, and the tests we’d create. In short, start with the data model to get a sense of the effort it would take.
LDBC is a good candidate. It is a social network that contains people, forums, and posts. It’s easy to understand and explain, and we are very familiar with it. We decided on 3 billion people, surpassing the largest social network on the planet. The degree of social connectivity was chosen so that the person shard would come out 850GB, and every forum shard would come at 250GB with about 900 million relationships each. To get to the target of 1 trillion relationships we’d need about 1110 forum shards in total, each its own machine.
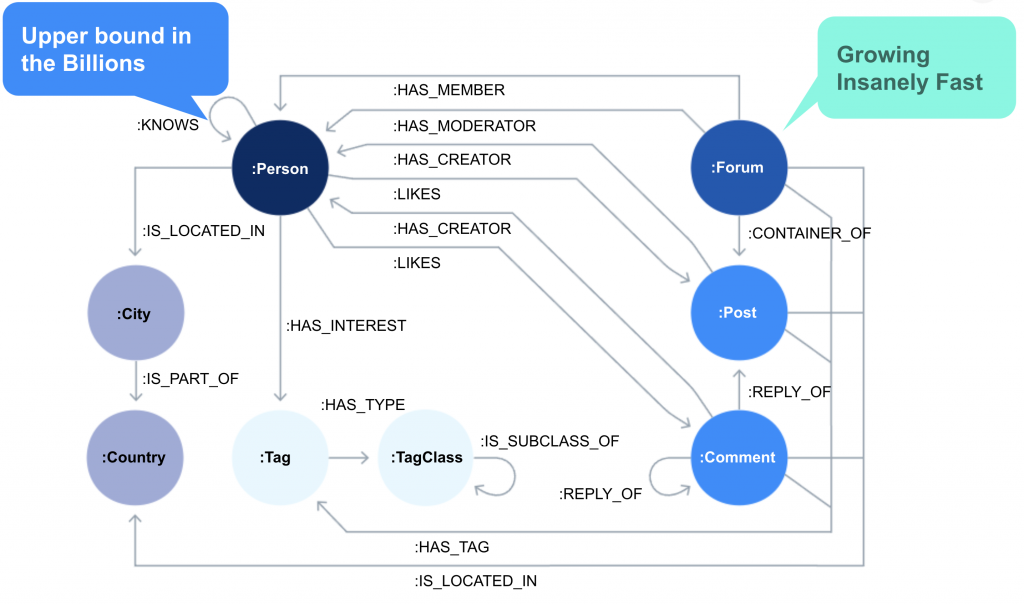
That’s 1110 forum shards, plus a few more for redundancy, each of which will need to have a store generated for it. We also wanted 3 Fabric proxies connecting to 10, 100, and all the shards to see how the system scales as data sizes grow. And, with the clock ticking, we needed a plan to orchestrate all these machines.
It was all about managing risk. We expected that, if trouble found us, it would be either during store generation or something glitching badly in the network. As it turned out, we were half right.
Making It Reality
The main sources of complexity came from two places. One was the large number of machines that would host the shards. The other was generating the shard data, which we knew needed to happen in parallel and would, therefore, also need to orchestrate a lot of machines.
We needed a two-step approach. The first step would be full-sized stores but a small number of Neo4j processes. That would let us test the parallel store creation, the generators, the installation of the stores from the buckets to the shards, and also test the MVP of the latency-measuring client. It wouldn’t put any stress on our orchestration tools (that would come later), and allowed us to focus on getting everything wired properly for our proof of concept. Things worked out pretty well, and we had all the pieces in place. Everything seemed to work together, and now we could hold our breath and go for the second phase – full size.
With two weeks left, we moved to step two: We pulled out all the stops and braced for impact.
The first issue that came up was that AWS instance provisioning started failing unpredictably at around 800 machines. Some detective work led us to discover that we have a vCore limit on our AWS account that didn’t let us create any more machines. AWS Support lifted it promptly and we continued creating instances only to hit a more serious limitation:
“We currently do not have sufficient x1e.4xlarge capacity in zones with support for ‘gp2’ volumes. Our system will be working on provisioning additional capacity.”
Hmm. It would seem Amazon had run out of capacity. This left us with two options. Either go for multiple Availability Zones or for smaller instance types. We decided that there’s more complexity and unknowns going for multi AZ, so we’d do smaller instances for now, and if performance was a problem, we’d deal with it later. Getting to the full number of instances was the most important goal.
Using smaller instances did the trick, and the next day we had the full contingent of shards up and running. The latency measuring demo app was almost ready so we decided to take some measurements to see where we stood.
But it wasn’t going to be that easy.
The complete Fabric proxy, the one pointing to all 1129 shards, was timing out. Neo4j log files didn’t have any relevant error messages, just the timeouts. No GC pauses, no firewall misconfigurations; none of the usual suspects were to blame. Each individual shard was responding normally, and the Fabric proxy didn’t show any problems either. It took an evening of investigative work to find that the issue was DNS query limiting. As AWS documentation points out:
“Amazon provided DNS servers enforce a limit of 1024 packets per second per elastic network interface (ENI). Amazon provided DNS servers reject any traffic exceeding this limit.”
Yup. That should do it. Our Fabric configuration was using DNS names for the shards, so that limit was reached immediately on every query we submitted. The solution was quite simple – just make the DNS entries static on the Fabric instance and no longer depend on DNS.
And that was the last limit we had to overcome. Our initial latency numbers were looking very nice and we decided there was no reason to move to larger instance types, which would also help keep the costs reasonable. Overall, we built tools that allowed us, at the press of a button, to set up a 1129 shard cluster hosting 280 TB of data, with 3 Fabric proxies, in under 3 hours. And it took us 16 days to get there.
We spent the rest of the time fine-tuning the configurations and the queries, and trying out the latency measuring app. We also played around with the graph itself and created new ad hoc queries to get a feel of working with such a large setup. The results of this work can be seen at the NODES 2021 Keynote, or you can try it yourself by using the trillion-graph repository.
Parting Thoughts
This is just the first step in a long journey. We have a lot more work to do to understand how large graph databases behave, how network variations aggregate as noise, and how we should improve the system to scale beyond the numbers we achieved for this demo.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
