


Introducing Your New Cypher Co-Pilot

Product Manager for Neo4j Developer Tools, Neo4j
7 min read


ℹ️ Update: You now need to enable the copilot for your organisation before it becomes available, see an example of how to do this for console preview. Similar settings apply for the regular console.

This summer, we’re pleased to announce the launch of a new Cypher co-pilot available in Neo4j Aura to all Workspace users. When you land in the Workspace Query tab, you’ll notice a new sparkling icon (✨) to the right of the main query editor. That’s where you want to be.

Who’s This For?
Our hope is that this early version of the co-pilot is useful to new and experienced users alike. It will help beginners generate and learn the Cypher constructs that can be used to accomplish different tasks and save time for experienced users by generating a good initial statement to work from.
We’ve been testing the co-pilot over the past few months, and we’ve found it to be simultaneously very capable of generating useful and sometimes quite sophisticated queries — but also sometimes getting the simplest things wrong. So it’s really important to check your queries carefully before executing them, especially if they write or update data.
How to Use It
If you come to Query via the Aura console, you’ll be authenticated and ready to go. If you haven’t visited Workspace for a while, you might be prompted to log in to Aura again to get going.

How Does It Work?
The co-pilot currently uses a base LLM from OpenAI with a task-focused system prompt. While the model hasn’t yet been fine-tuned to expertly generate Cypher (see limitations later), it keeps the LLM primed with the context of your current database schema. This means every request should have a reasonable understanding of your current database. The prompt also includes few-shot examples and guidelines for generating correct Cypher.
You input your natural language question, and the LLM generates a Cypher candidate, which you can edit and adjust (or adjust your question and re-generate) before execution:
Let’s Take It for a Spin
One way to use a co-pilot is to help you build a graph. We willlook at a small analysis project I recently completed to analyze event data.
This small project started with Data Importer to quickly load a CSV file of User and Event data with the following model.

However, the data model lacked one important part: a NEXT_EVENT relationship showing chains of events completed in a linear sequence.
My source data didn’t have a nice input defining the set of relationships between Events, so I knew this was something I could achieve as post-processing in Cypher.
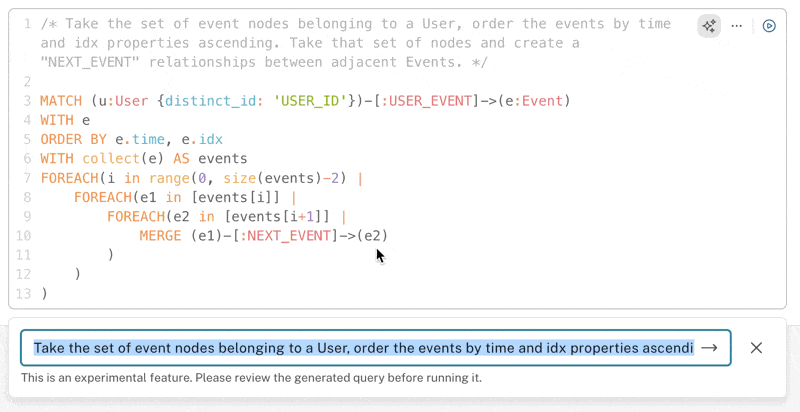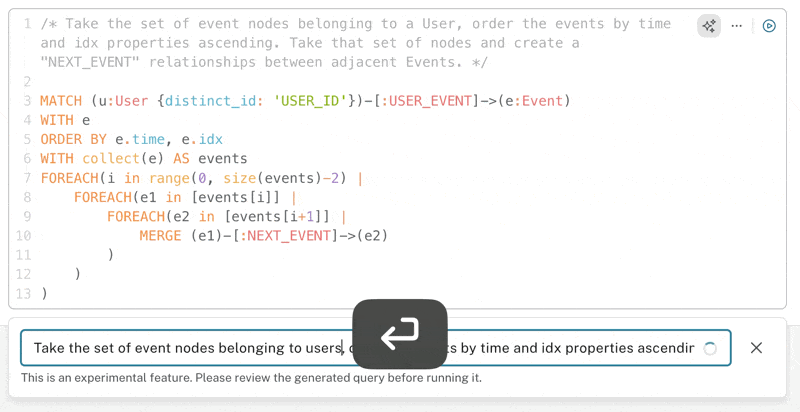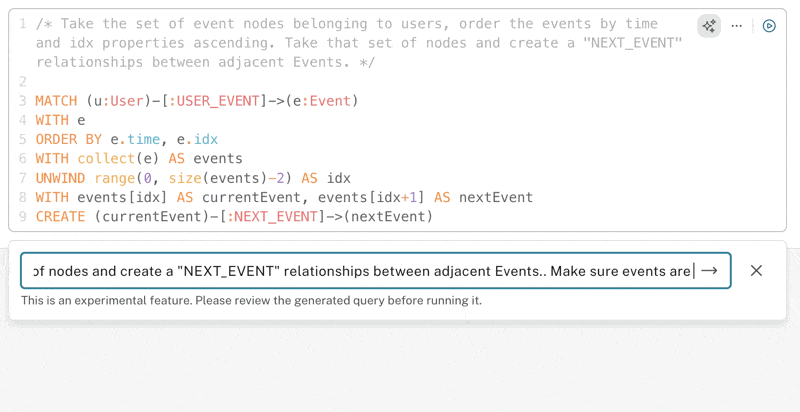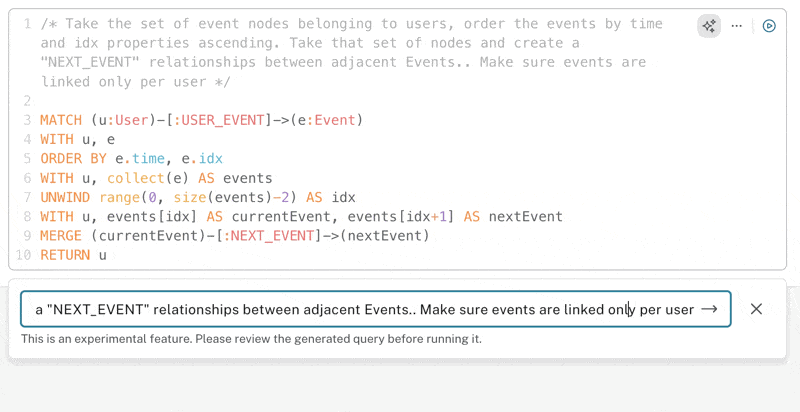
I’ve done this kind of thing numerous times before, but it can sometimes take some Googling to get a refresher on the best query construct. Here was my first attempt assisted by the co-pilot, feeding some detail about properties I knew were needed to complete the task accurately:

Not a bad first attempt. There is more than one way of solving this problem, but the first attempt looked reasonable. Reviewing the query, there was, however, one obvious problem: It was looking for a specific user, whereas I wanted events for all users. While I could quite easily fix up the query myself, I could also try making the prompt clearer and see if that improves the generation.
We don’t currently support requesting tweaks to an existing query in the editor, but we do leave the last prompt in the co-pilot input so you can tweak it to give it more direction.
Below, you can see it takes a couple of attempts to get the right level of grouping, ensuring both users (u) and events (e) are used in the WITH statements:
It’s also interesting to note that the co-pilot switches to a different approach, opting to use collect instead of FOREACH constructs. Both approaches are valid; they are different ways of getting the same result.
Next, I want to see if I can visualize some chains of events originating from a user. Having done a few queries myself beforehand, I quickly realized that my modeling decision to link the user node to every event may not have been the wisest choice.
But I was hacking away a quick project, so there was no time for turning back. Feeding some of my insights into the prompt, this was my first attempt:

Now this isn’t quite right. You’ll notice I’ve again got a result that is looking for a specific user, rather than users generally. You’ll also notice that the new Cypher editor linting (red squiggly underline) is picking up the use of deprecated syntax, but that’s something we can fix quite easily. That great language support is a good help in fixing up the generated statements.
But the generation has set me on the right track, After a few tweaks, I’m heading in the right direction:
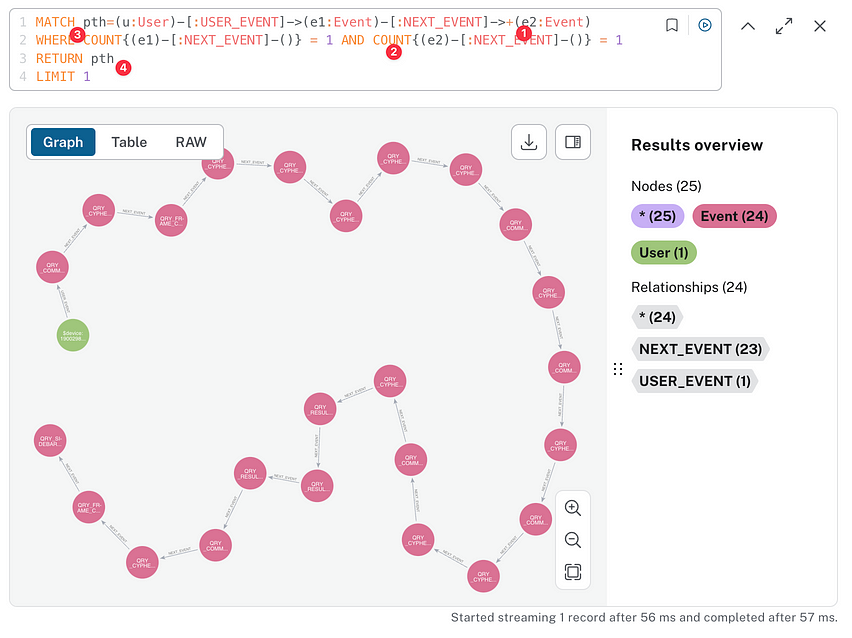
Making tweaks so that the query (1) does variable length traversals, (2) uses a second WHERE condition to make sure we end on a node with just one NEXT_EVENT relationship, and (3) fixes up the deprecated syntax swapping SIZE() out for COUNT{} and returning just a single limited path now that we’re looking across all users. Quite a few changes from the original query, but it gets us an event chain to inspect.
Let’s Try Something Different
Another way of using the co-pilot is to analyze existing databases. Let’s look at the old trusty Northwind dataset in graph form and see how it fares at answering some questions.
Let’s try asking which supplier supplied the most products:
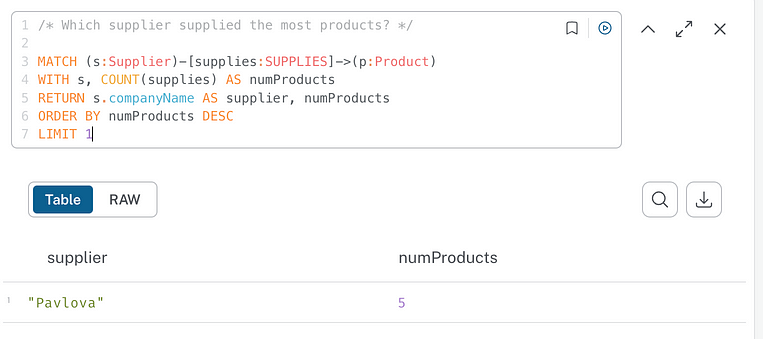
Not bad, but I realize that’s not quite what I had in mind. Let’s try being more precise:
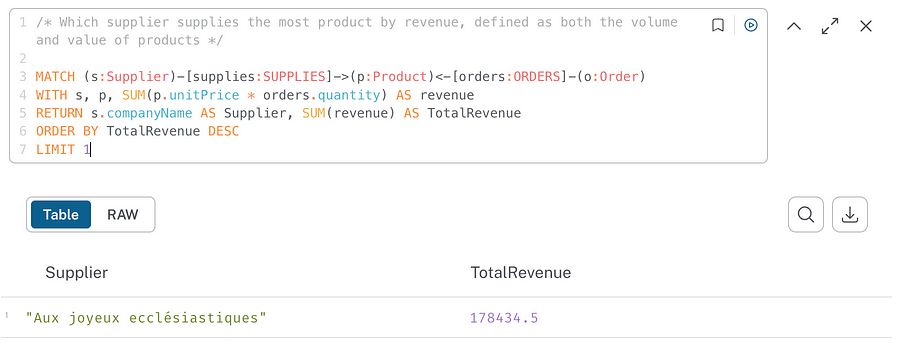
Nice! We can now see a much more nuanced answer, and the logic used looks pretty good.
Let’s try another question, like seeing who supplies dairy products:

OK, there are no results there, but I’m pretty sure the dataset contains dairy products. It turns out that “Dairy” isn’t the right categoryName. The schema we supply only has visibility of the schema and not actual data. So it’s guessed a value — just not the correct one. Once I’ve retrieved the correct category name, we get a result.

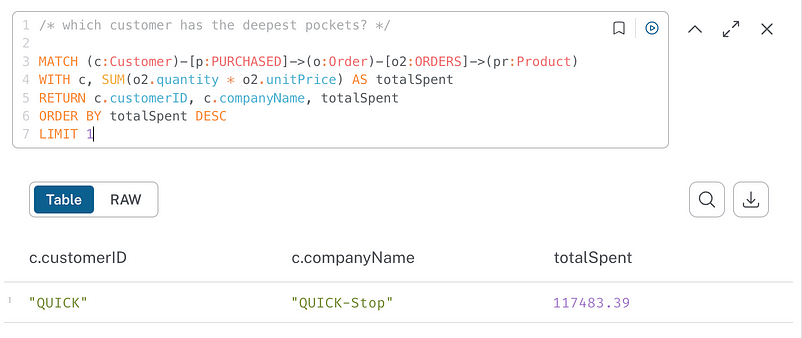
Let’s try one final example: Which customer has the deepest pockets? OK, that‘s not exactly what I asked. I asked, “Which customer bought the most expensive product?”

We get a result here, but it’s also accounting for order quantity. Maybe I wanted that, maybe I didn’t. This is a good reminder of how co-pilots can be great assistants, but they’re no substitute for you understanding what you’re doing and validating the output.
So just for fun, the last question made me wonder what happens if I actually ask, “Which customer has the deepest pockets?”

The query looks reasonable, but the value is 0, which doesn’t look right. It turns out the values it needed were on the ORDERS relationship, so with a quick tweak, we get what looks like a plausible result. Pretty neat!
What to Watch Out For
We’re working on improving the co-pilot generations, and while the above touched on some of the things to watch for, here’s a more complete list:
- Incorrect relationship direction — Your database schema may not always be fully observed. Upon closer inspection, complex path patterns that may look correct can be found to have the relationship direction reversed.
- Hallucinating “model shortcuts” — Even if all the correct node labels and relationship types are used, you can sometimes find that a relationship attempts to link two labels that don’t have such a relationship between them.
- Deprecated syntax — Queries returned can fail to run due to using deprecated syntax. Examples observed include deprecated size functions in WHERE clauses and old graph projection methods for the GDS library.
- Variable naming clashes — LLMs are generally good at choosing concise, meaningful variable names for path elements, such as(a:Address). When the same label exists multiple times in a path, it has been observed that LLMs unintentionally reuse a variable name when this is not the query’s intent, resulting in incorrect results.
- Inefficient queries — Unbounded traversals or unlimited queries can lead to computationally expensive operations. Evaluate the complexity of queries carefully.
- The tendency not to return relationships — Queries are inclined not to include relationships in returns that you intuitively expect, often requiring additional explicit prompting to return relationships. You can also just prefix the pattern with a path = and then return the path.
What’s Next?
We have some ideas about how we can improve the UX of the co-pilot, like allowing you to use it from the reusable frames and being aware of the current query context. But our highest priority is improving the quality of the generations with a custom fine-tuned model. Watch for more on this in the coming months.
We hope you have fun with this initial release and, as always, drop us some feedback over at https://feedback.neo4j.com/query to let us know how it goes.
Introducing Your New Cypher Co-Pilot was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths



