


Discover AuraDB Free: Week 32 – Marvel API Data

Head of Product Innovation & Developer Strategy, Neo4j
13 min read

Over the weekend I was watching the first few (very short) episodes of the new Groot series with my daughter and thought we could revisit the Marvel Data API in our livestream.

If you rather watch the stream recording than reading the article, here you go:
If you want to see our past episodes, check out the recordings.
If you are interested to provide feedback on the new Workspace experience in Neo4j Aura, that we also presented at GraphConnect, sign up here: https://neo4j.com/workspace
We already had an awesome presentation of the Marvel Data Model and all it’s complex challenges that required to treat it as a graph by Peter Olson, VP Web & App Dev at Marvel, presented at GraphConnect in 2013.
GraphConnect Videos 2013 – Graphing the Marvel Universe- Peter Olson @ GraphConnect NY 2013
My colleague Jennifer Reif had already explored the Marvel API in a 10 part series on our developer blog building a full stack app with Spring Data Neo4j.
As part of that series she also published a repository with import code for the Marvel API, which we are going to reuse today.
graph-demo-datasets/marvel-api.cypher at main · JMHReif/graph-demo-datasets
We first have to create an account and get API keys from: https://developer.marvel.com
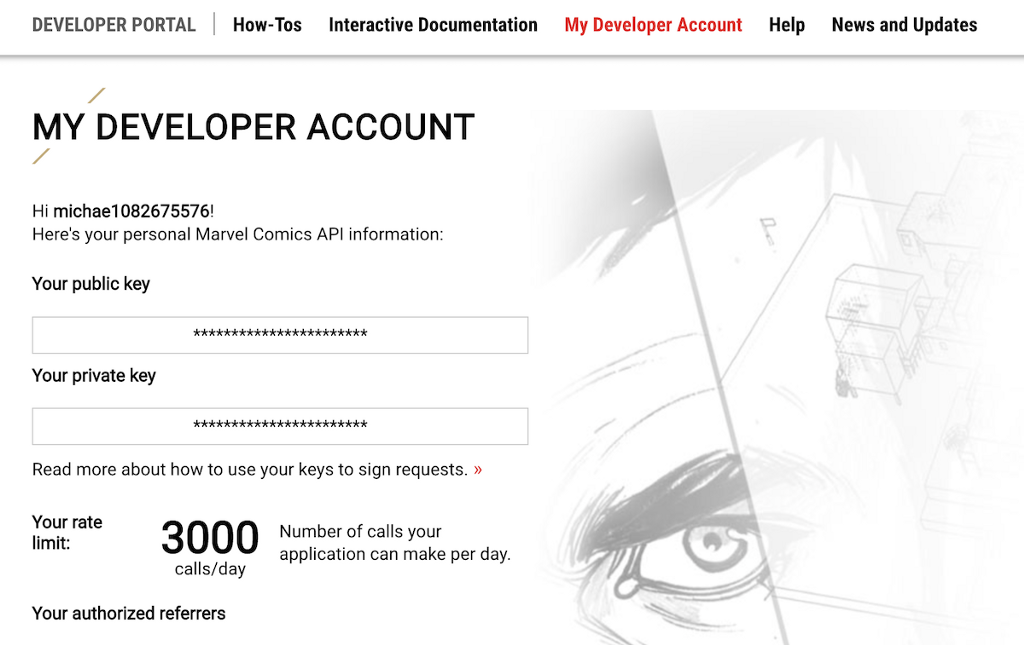
There is a public API key and also private API key that you have to hash with a current timestamp to make API requests. There is also a limit of 3000 API calls per day which is not a lot, given that there are more than 40,000 comics available in the Marvel API.
The Marvel API is a REST API with endpoints for
- Characters
- Comics
- Creators
- Series
- Events
- Stories
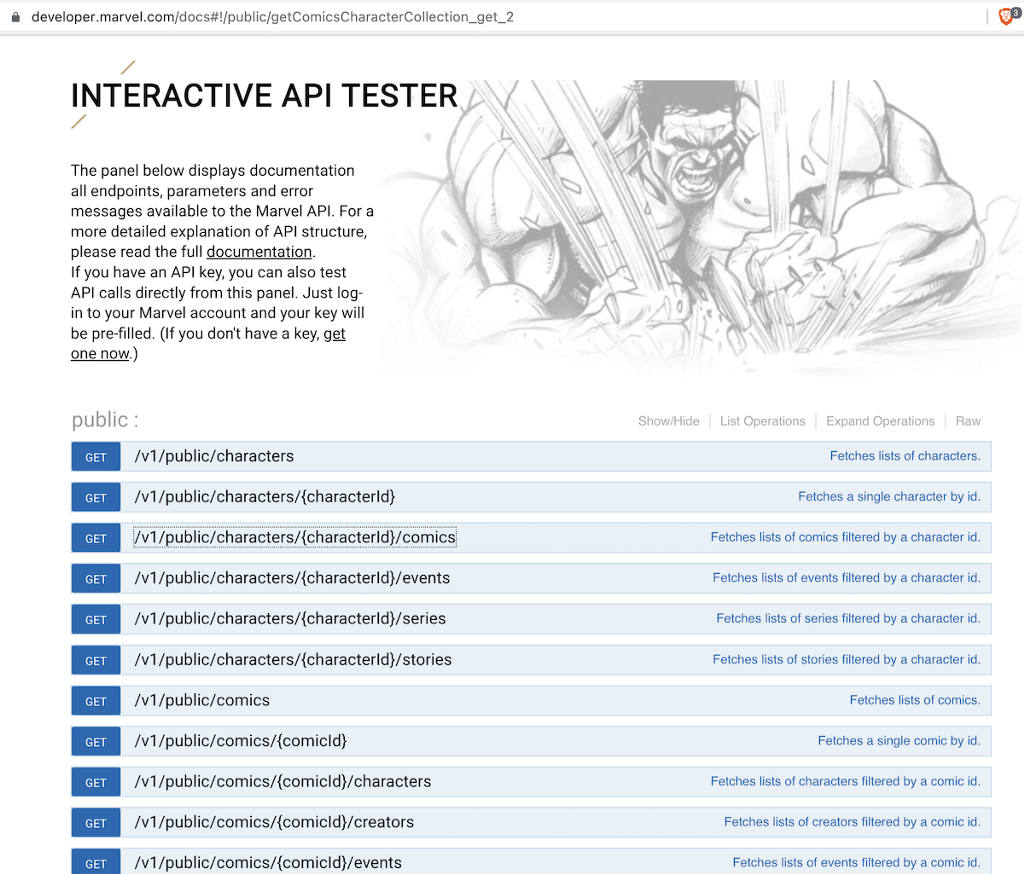
It’s also not really fast and you need to throttle your requests to not be blocked.
But fortunately apoc.load.json can help us with accessing the API and retrieving results, and apoc.periodic.iterate can handle batching of our operations so that we don’t have to do it all manually.
Both functions are also available in Aura, according to the AuraDB APOC docs.
So let’s get started.
Create a Neo4j AuraDB Free Instance
Go to https://dev.neo4j.com/neo4j-aura to register or log into the service (you might need to verify your email address).
After clicking Create Database you can create a new Neo4j AuraDB Free instance. Select a Region close to you and give it a name, e.g. Marvel.
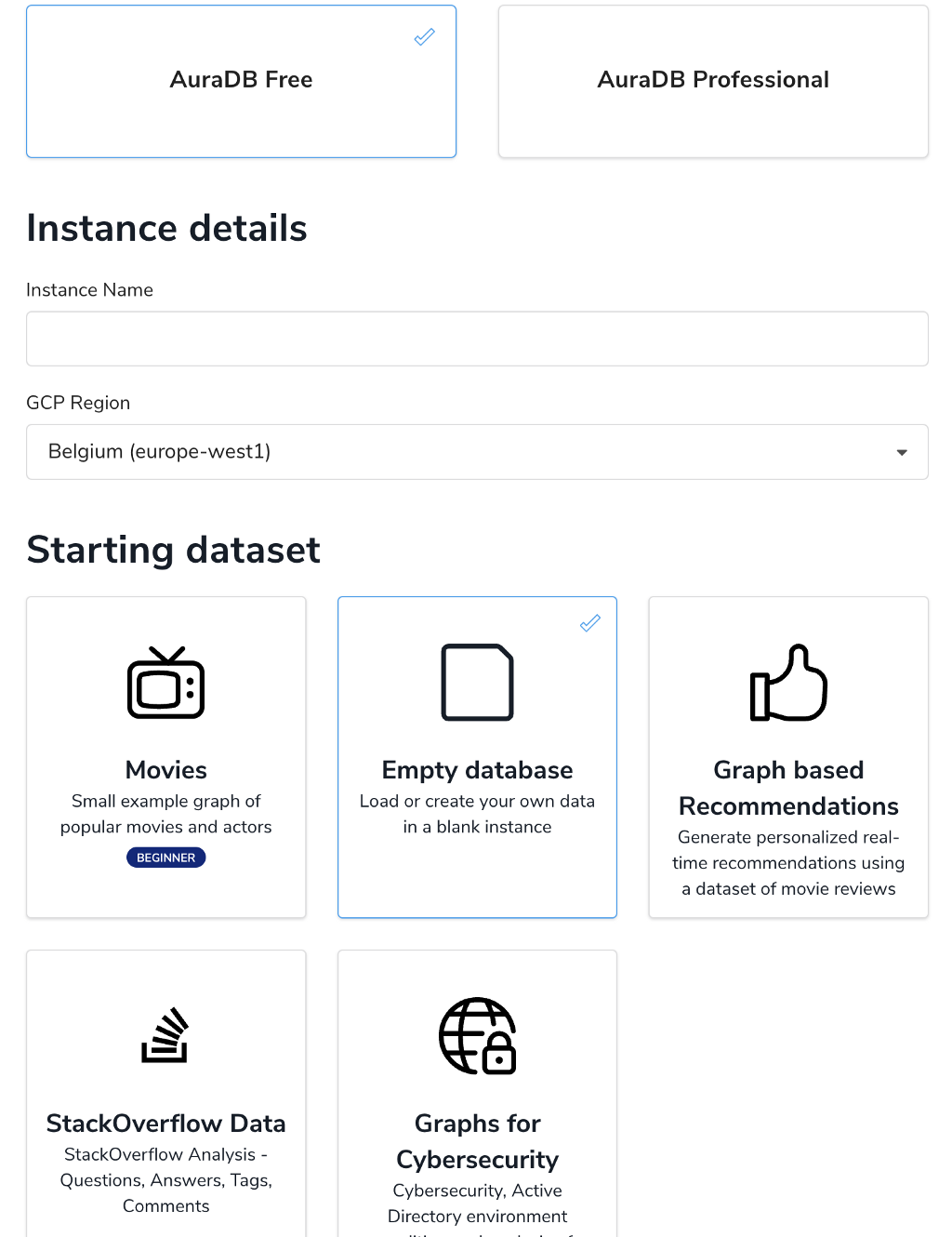
Choose the “blank database” option as we want to import our data ourselves.
On the Credentials popup, make sure to save the password somewhere safe, best is to download the credentials file, which you can also use for your app development.
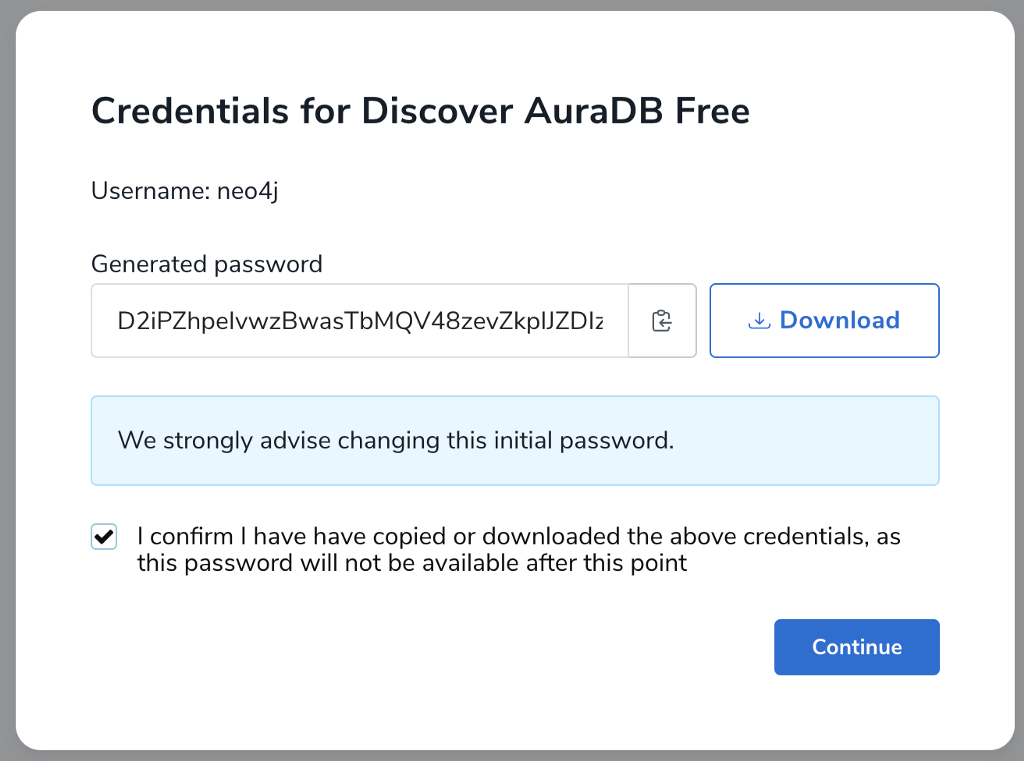
The default username is always neo4j.
Then wait 2–3minutes for your instance to be created.
Afterwards you can connect via the Query button with Neo4j Browser (you’ll need the password), or Import to Data Importer and Explore with Neo4j Bloom.
On the database tile you can also find the connection URL: neo4j+s://xxx.databases.neo4j.io (it is also contained in your credentials env file).
If you want to see examples for programmatically connecting to the database go to the “Connect” tab of your instance and pick the language of your choice.
The Data Model
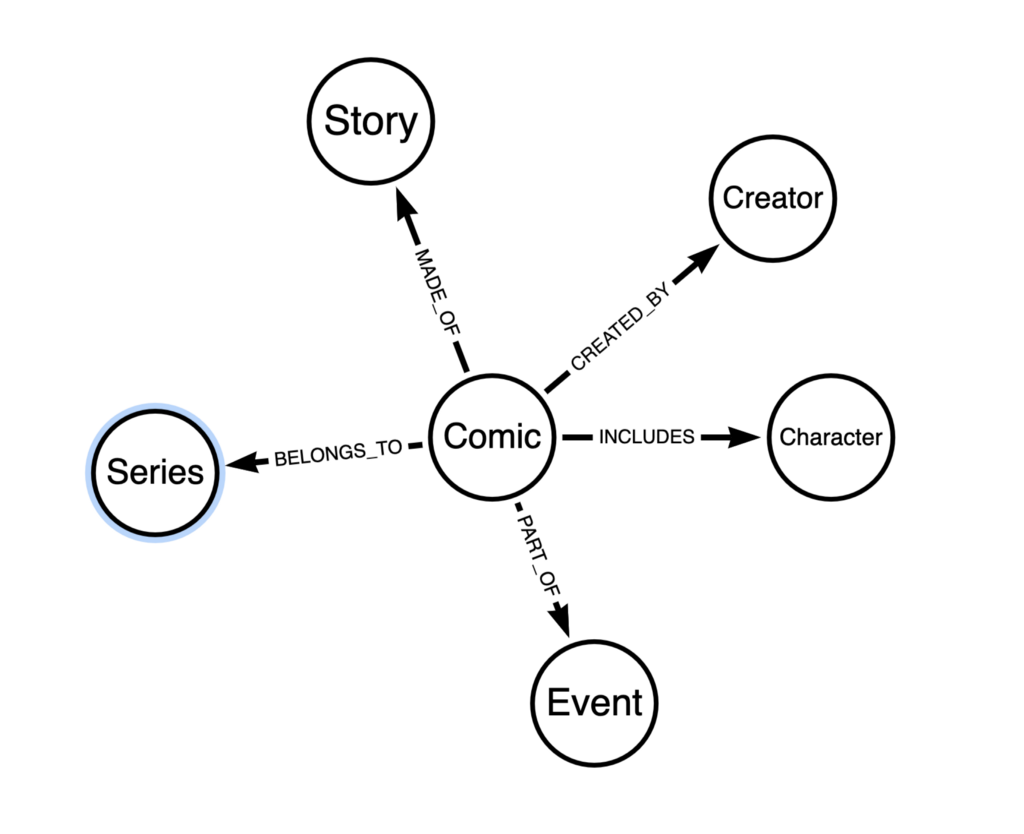
The data model centers around the ComicIssue node, it is connected to Creator, Character, Story, Event, and Series.
Loading the Data
Initially we can create the required constraints and indexes to allow fast lookup of nodes, to see if they already exist or to connect them.
CREATE CONSTRAINT ON (char:Character) ASSERT char.id IS UNIQUE;
CREATE CONSTRAINT ON (cre:Creator) ASSERT cre.id IS UNIQUE;
CREATE CONSTRAINT ON (issue:ComicIssue) ASSERT issue.id IS UNIQUE;
CREATE CONSTRAINT ON (series:Series) ASSERT series.id IS UNIQUE;
CREATE CONSTRAINT ON (story:Story) ASSERT story.id IS UNIQUE;
CREATE CONSTRAINT ON (event:Event) ASSERT event.id IS UNIQUE;
CREATE INDEX ON :Character(name);
CREATE INDEX ON :Creator(name);
CREATE INDEX ON :ComicIssue(name);
CREATE INDEX ON :Series(name);
CREATE INDEX ON :Story(name);
CREATE INDEX ON :Event(name);
As Jennifer described in part 2 of her marvel data series, for importing the data from the API we’d use apoc.load.json.
Create a Data Marvel: Develop a Full-Stack Application with Spring and Neo4j — Part 2
We set both API keys as parameters in Query (Neo4j Browser) with the following code
:params "marvel_public": "<your public API key here>", "marvel_private": "<your private API key here>"
One particularity of the API is that you also have to pass a timestamp and a hash which is computed from the public api key, private apic key, and the timestamp with each API request, so that’s a suffix of URL parameters that we have to pass with each request.
Fortunately, apoc.date.format and apoc.util.md5 help us here too.
WITH apoc.date.format(timestamp(), "ms", 'yyyyMMddHHmmss') AS ts
WITH "&ts=" + ts + "&apikey=" + $marvel_public + "&hash=" + apoc.util.md5([ts,$marvel_private,$marvel_public]) as suffix
We will mostly use two API endpoints, the one for characters themselves and one for the comics of a character.
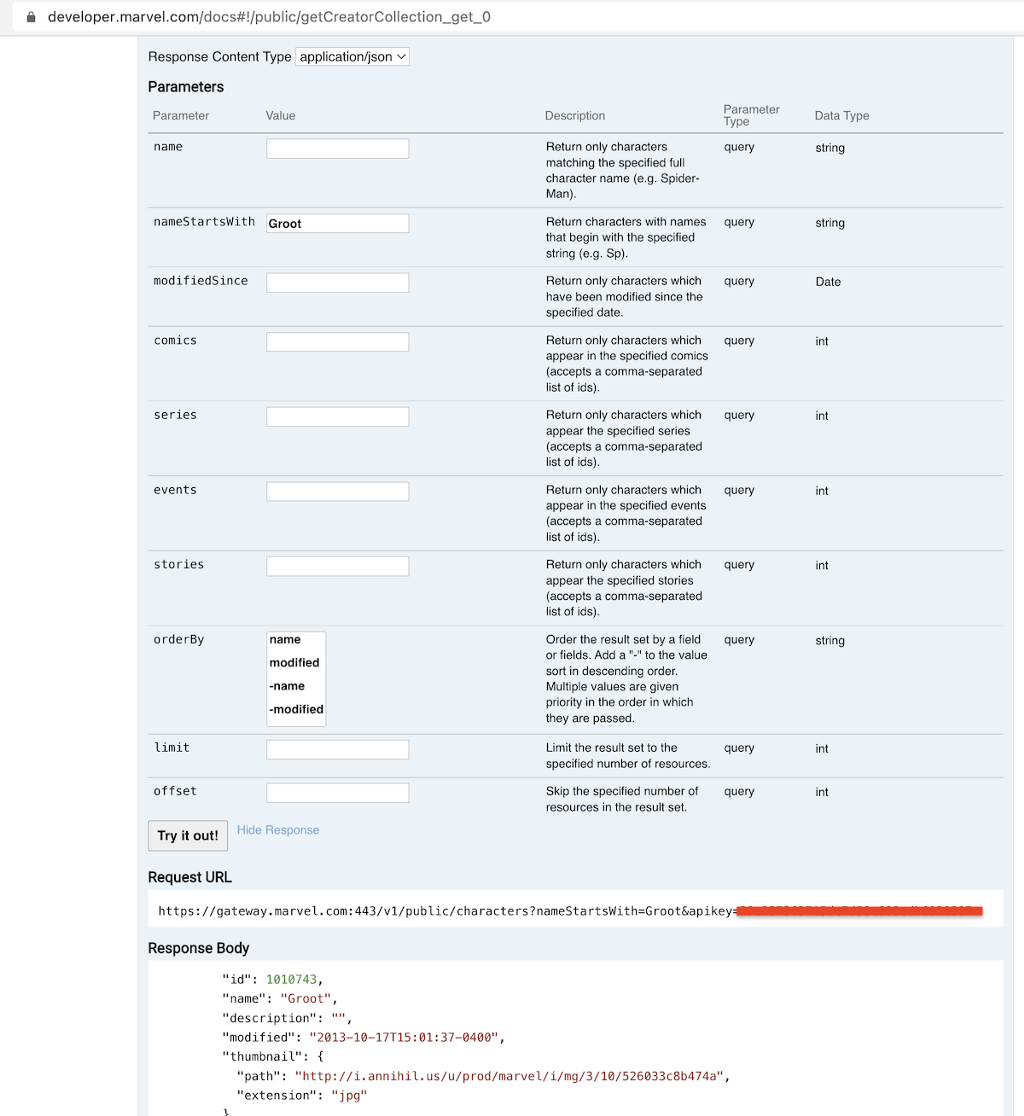
Jennifer loaded the characters by first letter, i.e. A-Z , fetching all characters for a letter at a time.
But as we wanted to look at the MCU we can just use the character names we’re interested in.
I found the page for teams and groups on the Marvel site which gave us The Avengers and Guardians of the Galaxy besides many others.
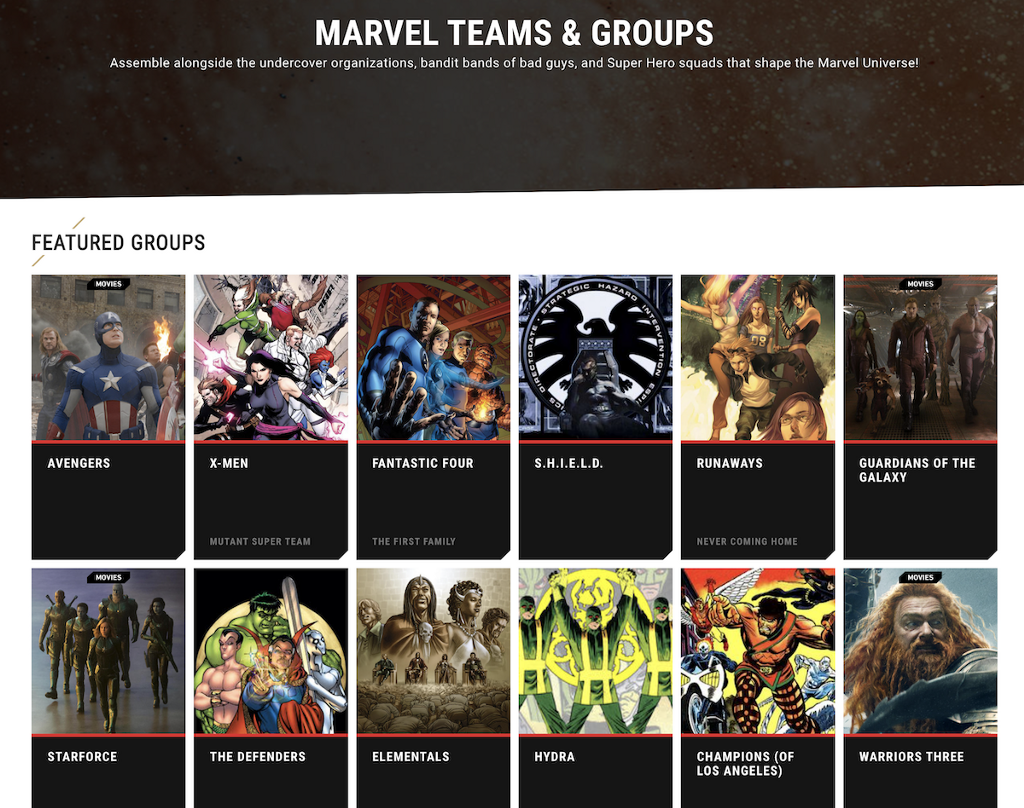
So we could just use their names (or prefixes) to fetch the character information from the API.
// compute api key url parameter suffix
WITH apoc.date.format(timestamp(), "ms", 'yyyyMMddHHmmss') AS ts
WITH "&ts=" + ts + "&apikey=" + $marvel_public + "&hash=" + apoc.util.md5([ts,$marvel_private,$marvel_public]) as suffix
// iterate over input, batch in 1 element at a time per tx
CALL apoc.periodic.iterate('
// iterate over list of character names
UNWIND ["Thor","Groot","Rocket","Iron","Captain","Hulk","Hawkeye","Drax","Gamora","Star Lord","Mantis","Ant","Vision","Black","Wanda","Black","Nick","War"] AS prefix
RETURN prefix',
// load each character API-URL it its separate transaction
'CALL apoc.load.json("https://gateway.marvel.com/v1/public/characters?nameStartsWith="+prefix+"&orderBy=name&limit=100"+$suffix) YIELD value
// iterate over result rows
UNWIND value.data.results as results
// only for characters with comics
WITH results, results.comics.available AS comics
WHERE comics > 0
// get-or-create character node, set attributes incl. resource-url
MERGE (char:Character {id: results.id})
ON CREATE SET char.name = results.name, char.description = results.description, char.thumbnail = results.thumbnail.path+"."+results.thumbnail.extension,
char.resourceURI = results.resourceURI
',{batchSize: 1, iterateList:false, params:{suffix:suffix}})
// yield results from batched updates
YIELD batches, total, timeTaken, committedOperations, failedOperations, failedBatches , retries, errorMessages , batch , operations, wasTerminated
RETURN batches, total, timeTaken, committedOperations, failedOperations, failedBatches , retries, errorMessages , batch , operations, wasTerminated;
This gives us our Characters in the database:
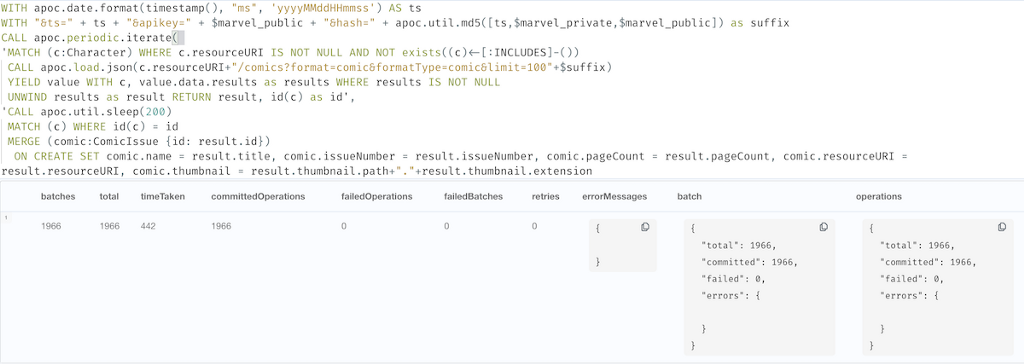
Now we can fetch additional data for each Character through their Comics.
We use the resourceUI from the Character and append the /comics?format=comic&formatType=comic&limit=100 suffix to fetch the comics details.
For each comic there is also information on their creators, related series, events, and stories.
We use the returned information to create nodes for each of them and connect them to Character and ComicIssue, see the Cypher statement below.
It looks complicated but is fetching the data for each character and then iterate over all comics and creating (get-or-create) the nodes and their relationships in the same pattern.
// suffix
WITH apoc.date.format(timestamp(), "ms", 'yyyyMMddHHmmss') AS ts
WITH "&ts=" + ts + "&apikey=" + $marvel_public + "&hash=" + apoc.util.md5([ts,$marvel_private,$marvel_public]) as suffix
CALL apoc.periodic.iterate(
// for each character which isn't connected to a comic yet
'MATCH (c:Character) WHERE c.resourceURI IS NOT NULL AND NOT exists((c)<-[:INCLUDES]-())
// load all their comics
CALL apoc.load.json(c.resourceURI+"/comics?format=comic&formatType=comic&limit=100"+$suffix)
// iterate over the comics in the update statement
YIELD value WITH c, value.data.results as results WHERE results IS NOT NULL
UNWIND results as result RETURN result, id(c) as id',
// short sleep for API safety
'CALL apoc.util.sleep(200)
// look up character again
MATCH (c) WHERE id(c) = id
// get-or-create comic
MERGE (comic:ComicIssue {id: result.id})
ON CREATE SET comic.name = result.title, comic.issueNumber = result.issueNumber, comic.pageCount = result.pageCount, comic.resourceURI = result.resourceURI, comic.thumbnail = result.thumbnail.path+"."+result.thumbnail.extension
WITH c, comic, result
// connect comic to character
MERGE (comic)-[r:INCLUDES]->(c)
WITH c, comic, result WHERE result.series IS NOT NULL
// for all series of the comic
UNWIND result.series as comicSeries
// get-or-create series
MERGE (series:Series {id: toInteger(split(comicSeries.resourceURI,"/")[-1])})
ON CREATE SET series.name = comicSeries.name, series.resourceURI = comicSeries.resourceURI
WITH c, comic, series, result
// connect series to comic
MERGE (comic)-[r2:BELONGS_TO]->(series)
WITH c, comic, result, result.creators.items as items WHERE items IS NOT NULL
// for all creators of the comic
UNWIND items as item
// get-or-create creator
MERGE (creator:Creator {id: toInteger(split(item.resourceURI,"/")[-1])})
ON CREATE SET creator.name = item.name, creator.resourceURI = item.resourceURI
WITH c, comic, result, creator
// connect creator to comic
MERGE (comic)-[r3:CREATED_BY]->(creator)
// for all stories of the comic
WITH c, comic, result, result.stories.items as items WHERE items IS NOT NULL
UNWIND items as item
// get-or-create story
MERGE (story:Story {id: toInteger(split(item.resourceURI,"/")[-1])})
ON CREATE SET story.name = item.name, story.resourceURI = item.resourceURI, story.type = item.type
WITH c, comic, result, story
// connect story to comic
MERGE (comic)-[r4:MADE_OF]->(story)
// for all the events of the comic
WITH c, comic, result, result.events.items AS items WHERE items IS NOT NULL
UNWIND items as item
// get-or-create-event
MERGE (event:Event {id: toInteger(split(item.resourceURI,"/")[-1])})
ON CREATE SET event.name = item.name, event.resourceURI = item.resourceURI
// connect event to comic
MERGE (comic)-[r5:PART_OF]->(event)',
// small batch
{batchSize: 1, iterateList:false, retries:2, params:{suffix:suffix}})
YIELD batches, total, timeTaken, committedOperations, failedOperations, failedBatches , retries, errorMessages , batch , operations, wasTerminated
RETURN batches, total, timeTaken, committedOperations, failedOperations, failedBatches , retries, errorMessages , batch , operations, wasTerminated;
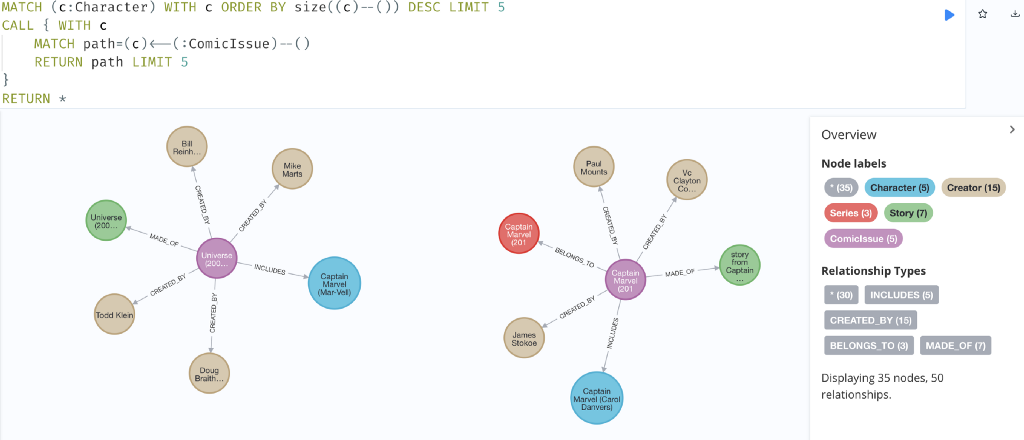
We can now visualize a few of their characters, comics, and related information:
MATCH (c:Character) WITH c
ORDER BY size((c)--()) DESC LIMIT 5
CALL { WITH c
MATCH path=(c)<--(:ComicIssue)--()
RETURN path LIMIT 5
}
RETURN *
Exploring in Query (Neo4j Browser)
In Neo4j Browser we can now query for instance through which series two characters are connected.
MATCH (c1:Character)<--(:ComicIssue)-->(s:Series)<--(:ComicIssue)-->(c2:Character)
WHERE id(c1) < id(c2)
RETURN c1.name, c2.name, collect(distinct s.name) as series
ORDER BY size(series) DESC LIMIT 2

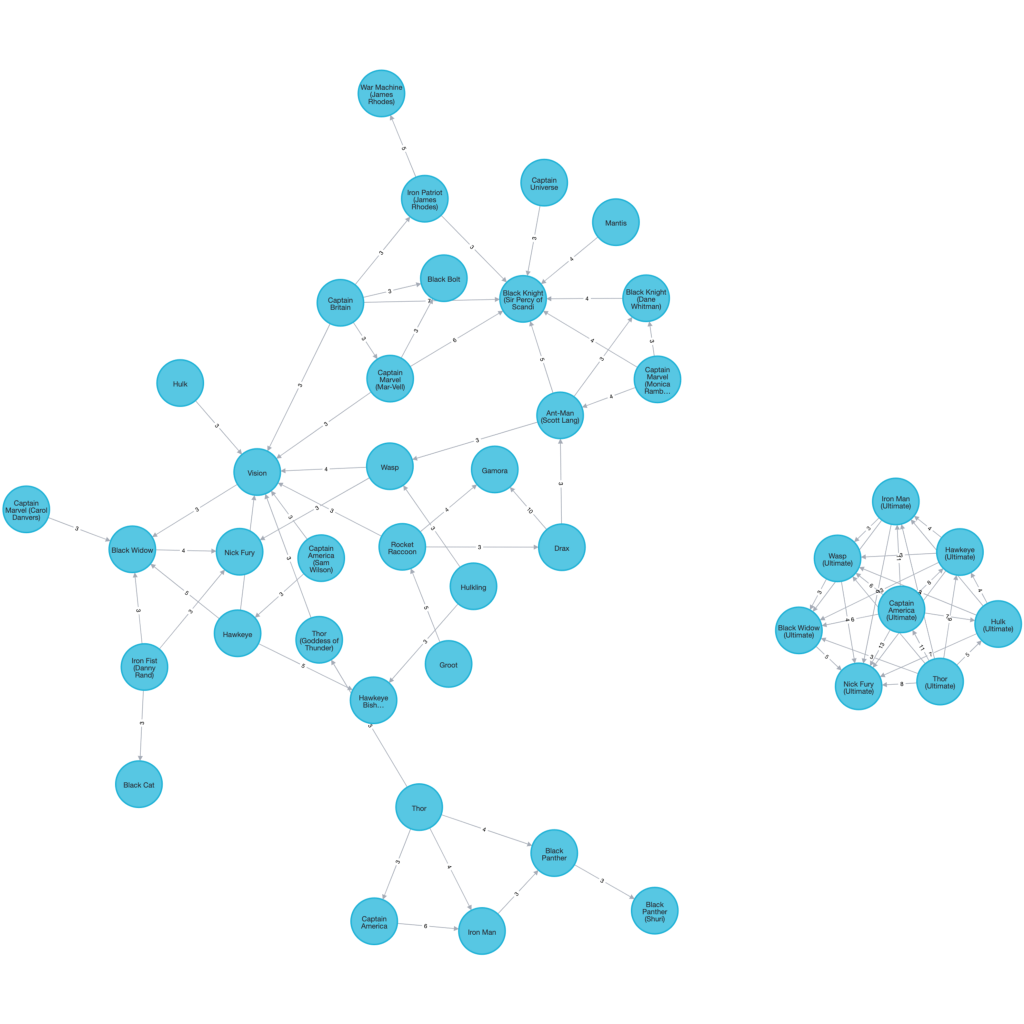
Or visualize a virtual network of character to character connections through these,
MATCH (c1:Character)<--(:ComicIssue)-->(s:Series)<--(:ComicIssue)-->(c2:Character)
WHERE id(c1) < id(c2)
WITH c1, c2, count(distinct s) as freq
WHERE freq > 2
RETURN c1, c2, apoc.create.vRelationship(c1, 'SERIES', {freq:freq}, c2) as rel
which allows us to already visually see clusters.
Exploring with Explore (Bloom)
We can open Explore (Bloom) from the AuraDB UI.
And then run an search phrase like: “Character name Iron Man <tab> Comic <tab> Story”
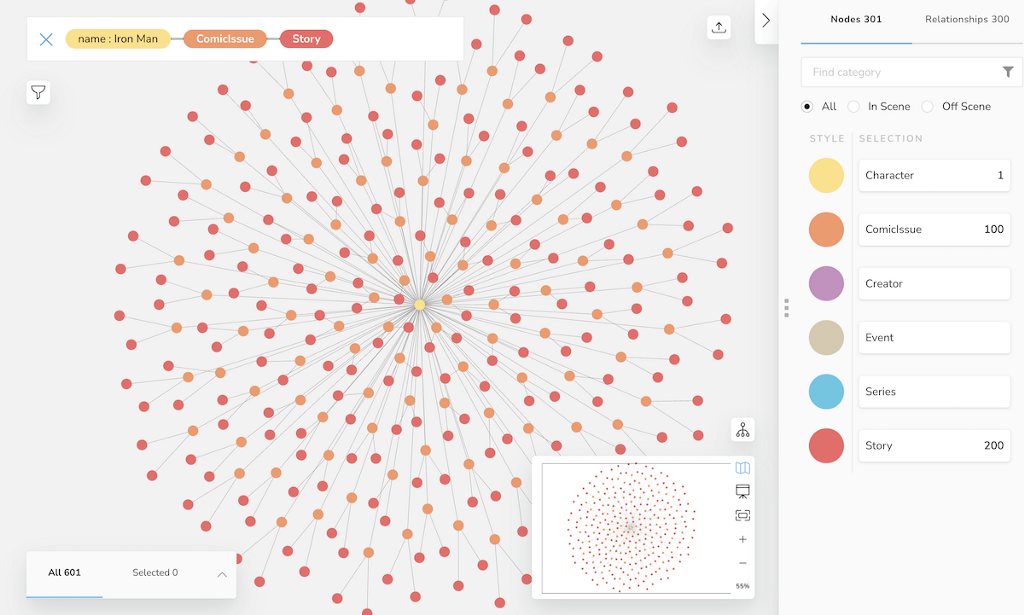
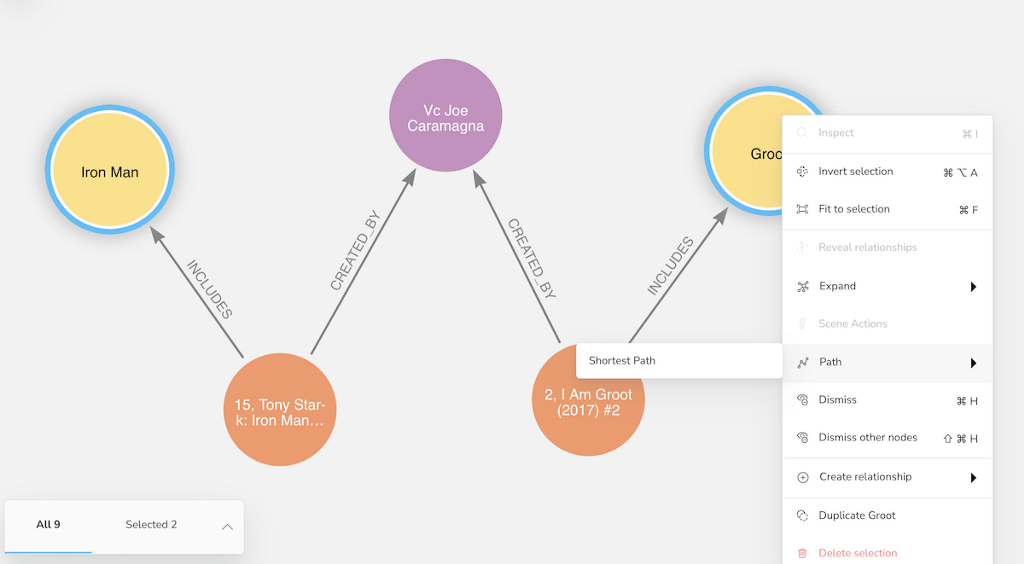
We can also find multiple character nodes in Bloom and look at their connection through other elements of the graph.
GraphQL API
To build a GraphQL API on top of our data we can just launch Neo4j GraphQL Toolbox against our AuraDB database.
By clicking Generate type definitions it will inspect your database and generate already pretty good type definitions from your data. I just went over them and shortened the relationship-field names.
type Character {
comics: [ComicIssue!]! @relationship(type: "INCLUDES", direction: IN)
description: String!
id: BigInt!
name: String!
resourceURI: String!
thumbnail: String!
}
type ComicIssue {
belongsTo: [Series!]! @relationship(type: "BELONGS_TO", direction: OUT)
createdBy: [Creator!]! @relationship(type: "CREATED_BY", direction: OUT)
id: BigInt!
includes: [Character!]! @relationship(type: "INCLUDES", direction: OUT)
madeOfStories: [Story!]! @relationship(type: "MADE_OF", direction: OUT)
name: String!
pageCount: BigInt!
partOfEvents: [Event!]! @relationship(type: "PART_OF", direction: OUT)
resourceURI: String!
thumbnail: String!
}
type Creator {
created: [ComicIssue!]! @relationship(type: "CREATED_BY", direction: IN)
id: BigInt!
name: String!
resourceURI: String!
}
type Event {
comics: [ComicIssue!]! @relationship(type: "PART_OF", direction: IN)
id: BigInt!
name: String!
resourceURI: String!
}
type Series {
comics: [ComicIssue!]! @relationship(type: "BELONGS_TO", direction: IN)
id: BigInt!
name: String!
resourceURI: String!
}
type Story {
comic: [ComicIssue!]! @relationship(type: "MADE_OF", direction: IN)
id: BigInt!
name: String!
resourceURI: String!
type: String!
}
Then with Build Schema the library generates an augmented GraphQL schema that adds filters, limiting, sorting and top-level queries and mutations and runs this as an API in your browser.
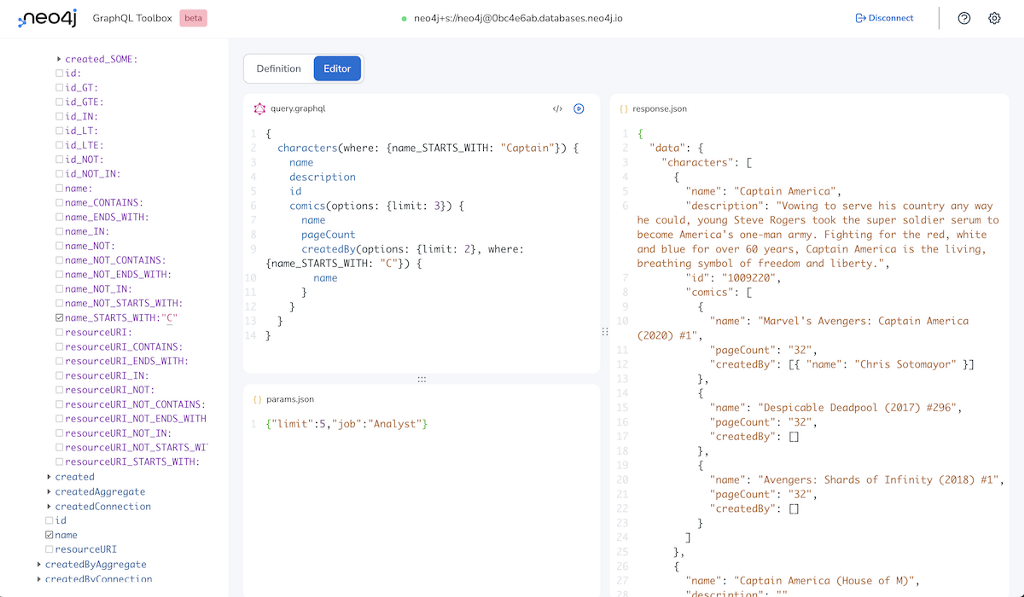
So you can start running GraphQL queries against your database, like this one which fetches 3 comics and 2 creators each for each characters whose name starts with Captain.
{
characters(where: { name_STARTS_WITH: "Captain" }) {
name
description
id
comics(options:{limit:3}) {
name
pageCount
createdBy(options:{limit:2}, where:{name_STARTS_WITH:"C"}) {
name
}
}
}
}
Which gives us this response:
{
"data": {
"characters": [
{
"name": "Captain America",
"description": "Vowing to serve his country any way he could, young Steve Rogers took the super soldier serum to become America's one-man army. Fighting for the red, white and blue for over 60 years, Captain America is the living, breathing symbol of freedom and liberty.",
"id": "1009220",
"comics": [
{
"name": "Marvel's Avengers: Captain America (2020) #1",
"pageCount": "32",
"createdBy": [{ "name": "Chris Sotomayor" }]
},
{
"name": "Despicable Deadpool (2017) #296",
"pageCount": "32",
"createdBy": []
},
{
"name": "Avengers: Shards of Infinity (2018) #1",
"pageCount": "32",
"createdBy": []
}
]
},
...
]}}
To learn more on how to get started quickly with launching a GraphQL API with these type definitions, check out the Getting Started Neo4j GraphQL Docs.
This was it for today! I hope you enjoyed this exploration and you start exploring your own.
Discovering AuraDB Free with Fun Datasets
Discover AuraDB Free: Week 32 — Marvel API Data was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




