GraphRAG in (almost) pure Cypher

Director of Engineering, Neo4j
8 min read

In my previous blog, A GenAI-Powered Song Finder in Four Lines of Code, we used vector search to find a song based on a description of the song. We used the vector embeddings just to find a document, but with Retrieval-Augmented Generation (RAG), we use the results of the search as context to a chatbot (like ChatGPT) to provide a grounded answer, thereby avoiding hallucinations, providing source references, and being able to ask questions about things the chatbot doesn’t know about.
With standard RAG, we use vector search to find a relevant document from a data source. We then provide that to the chatbot, asking it to give us the answer to the question based on the content of that document.
With GraphRAG, we also use vector search to find a document, but we use the power of the knowledge graph to expand from it and find more relevant documents to provide.
The movie graph
To demonstrate this, I have built a graph of movies, TV series, video games, etc., and the people working on those as of February 2024. The graph contains about 10 million titles and about 13 million people. There are also about 106 million relationships. About 1.3 million of those titles have a synopsis attached. The data model of this graph looks like the following image.
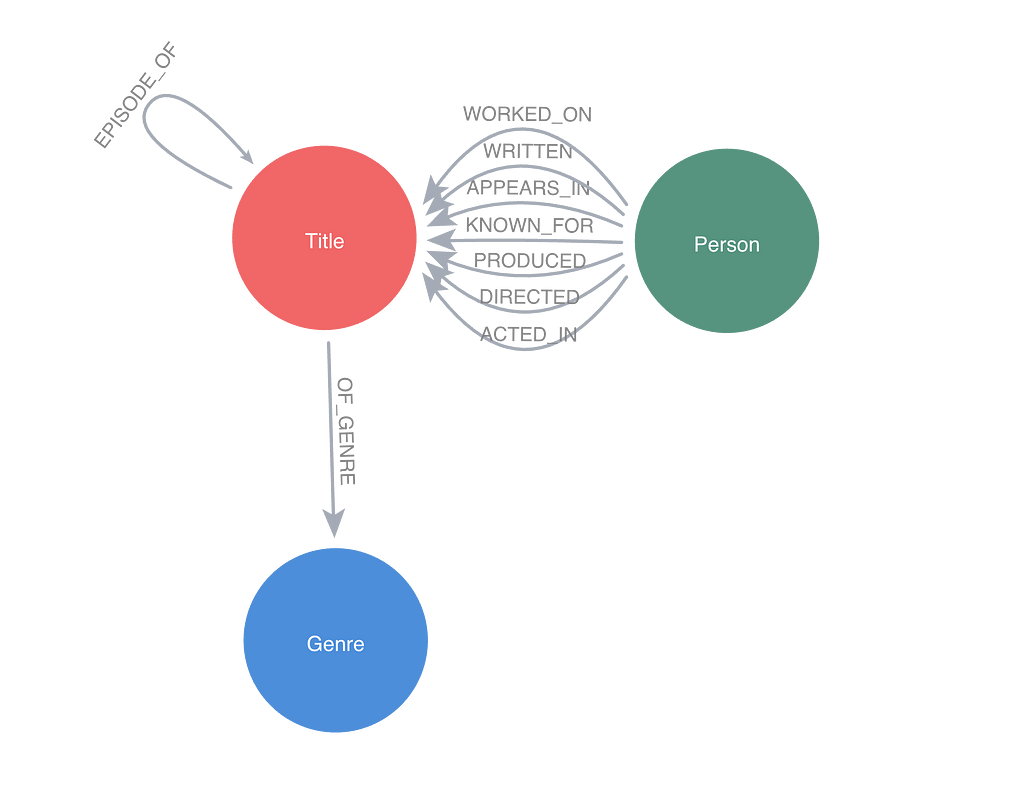
The graph was created using the public non-commercial dataset from the Internet Movie Database (IMDB) and The Movie Database (TMDB); the data was fetched on February 22, 2024.
Just like in my previous blog post, we will do a vector index and a vector embedding, this time on the synopsis property of the titles. Let’s start with creating the index:
CREATE VECTOR INDEX synopsis_embeddings IF NOT EXISTS
FOR (t:Title) ON (t.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}
And now we do the embeddings. In the music blog, we could just simply provide all properties to the batch embedding, but OpenAI only supports 2,048 properties in a batch — and we have 1.3 million. So I created a script that ran this query until it returned 0:
MATCH (title:Title)
WHERE title.synopsis IS NOT NULL AND title.embedding IS NULL
WITH title LIMIT 2048
WITH collect(title.synopsis) AS synopsis, collect(title) AS titles
CALL genai.vector.encodeBatch(synopsis, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(titles[index], "embedding", vector)
RETURN COUNT(index) AS embedded
Note that for the query above and all queries to follow, we need an API key from OpenAI that we can set as a parameter:
:params
{
apiKey: "*****"
}
The question
In the music blog, we used vector search to search for one song based on a description. But for this case, we phrase a question that we want ChatGPT to answer based on the synopses in the movie database and also provide a reference to where it found the answer. So the question we want to have answered is this:
With what family does Robb Stark start a war?
I think most of us know that this is from Game of Thrones, but let’s assume we don’t know. We just want this question answered. We can’t provide 1.3 million synopses to ChatGPT, so we need to find where it would most likely find the answer to this question.
Let’s start by setting the question as a parameter:
:params
{
question: "With what family does Robb Stark start a war?",
apiKey: "*****"
}
And now we do a vector search, just like we did in the music blog:
WITH genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
RETURN title
This gives us “The Watchers on the Wall” from Season 4, Episode 9 of Game of Thrones. So out of 1.3 million titles, it found the correct TV series, which I think is really impressive, and it found it in less than a second. However, the synopsis of this episode would not help ChatGPT find the answer to the following request:
Jon Snow and the Night’s Watch face a big challenge.
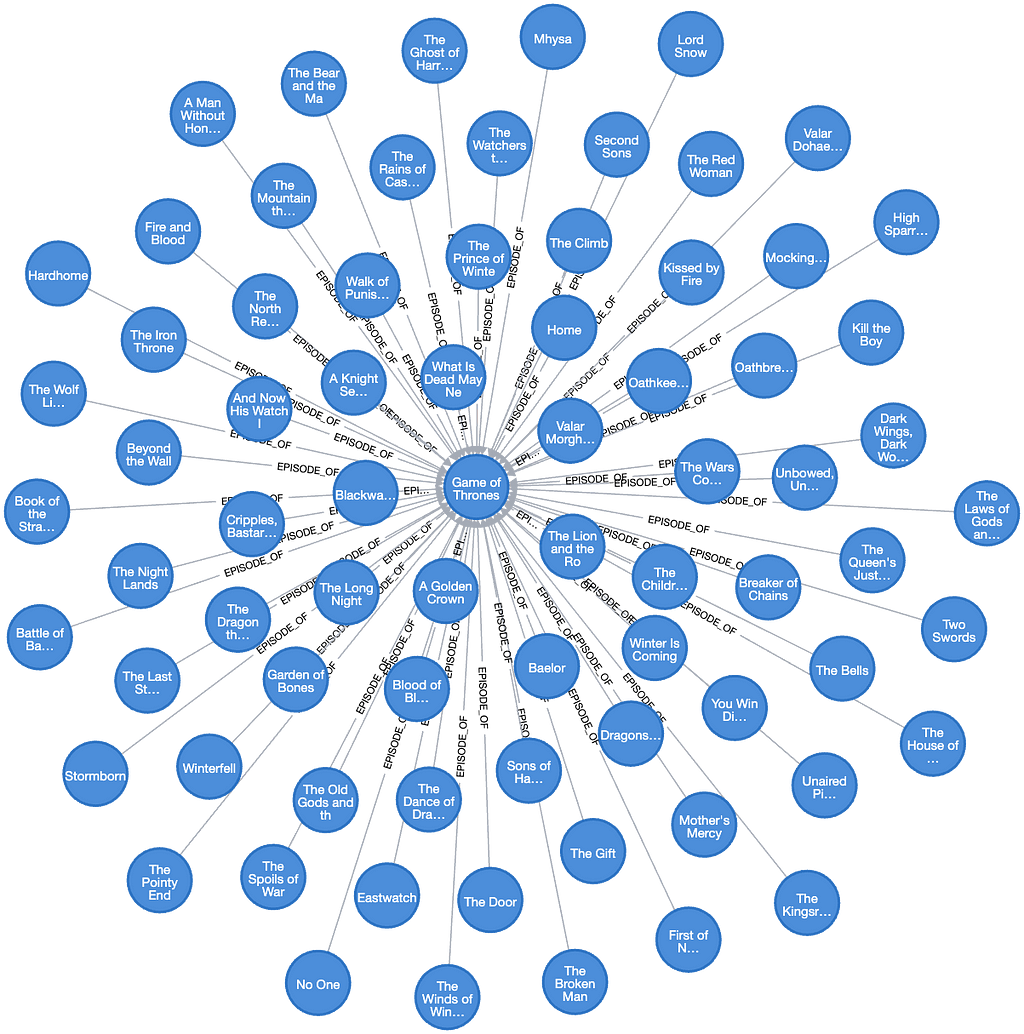
This is where we’ll use the power of the knowledge graph. We’ll expand the query so that it not only returns the title from the vector search but if the title is a TV series, it also includes all episodes, and if it is an episode (as in this case), it includes the series and all other episodes:
WITH question, genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
OPTIONAL MATCH (title)-[:EPISODE_OF]->(series:Title)
OPTIONAL MATCH (title)<-[:EPISODE_OF]-(other1:Title)
OPTIONAL MATCH (series)<-[:EPISODE_OF]-(other2:Title)
WITH collect(title)+collect(series)+collect(other1)+collect(other2) AS allTitles
UNWIND allTitles AS titles
RETURN DISTINCT titles
This gives us the following result.
RAG
And now comes the actual RAG part, where we collect all those synopses and ask ChatGPT to give us an answer to the question based on those. To do this, we need to make a REST call to OpenAI. This is (currently) not a built-in procedure in Neo4j, so we either need to do it in our own application or if we host our own instance of Neo4j and have the possibility to run APOC Extended, we can use a procedure there, which is what I will do.
The question we will ask ChatGPT looks like this:
Answer the following Question based on the Context only and provide a reference to where in the context you found it. Only answer from the Context. If you don't know the answer, say 'I don't know'. The context is a list of titles followed by a synopsis, separated by colon. Context: [All titles and synopsises separated by colon] Question: [Our original question]
This is what the full Cypher query looks like, with that question handled with the APOC Extended procedure:
WITH question, genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
OPTIONAL MATCH (title)-[:EPISODE_OF]->(series:Title)
OPTIONAL MATCH (title)<-[:EPISODE_OF]-(other1:Title)
OPTIONAL MATCH (series)<-[:EPISODE_OF]-(other2:Title)
WITH collect(title.primaryTitle + ":" + title.synopsis)+collect(series.primaryTitle + ":" + series.synopsis)+collect(other1.primaryTitle + ":" + other1.synopsis)+collect(other2.primaryTitle + ":" + other2.synopsis) AS allTitles
UNWIND allTitles AS titles
WITH DISTINCT titles
WITH apoc.text.join(collect(titles), "n") AS context
CALL apoc.ml.openai.chat([
{role:"user", content:"Answer the following Question based on the Context only and provide a reference to where in the context you found it. Only answer from the Context. If you don't know the answer, say 'I don't know'. The context is a list of titles followed by a synopsis, separated by colon.nnContext: " + context + "nnQuestion: " + $question}
], $apiKey) yield value
RETURN value.choices[0].message.content AS Title
The answer we get back is The Lannisters: “The North Remembers:As Robb Stark and his northern army continue the war against the Lannisters …” — free from hallucination and with source reference provided.
Next level
When I showed this to a colleague, he said: “That’s cool, but ChatGPT knows about Game of Thrones and could have provided the answer anyway. How would it work with a title that didn’t exist when ChatGPT was trained?”
At the time, ChatGPT was last trained in April 2023. So I had to find something that was released between April 2023 and February 2024 that I had seen so I could phrase a question about it. What I came up with was the movie Argyle. The question I came up with was:
What is the name of Elly Conway’s cat?
To begin with, I asked ChatGPT in a plain prompt without any RAG, and the answer I got back was: “Elly Conway’s cat is named Lucy. Elly Conway is a pseudonym for the Australian author Liane Moriarty, known for her works such as ‘Big Little Lies’ and ‘Nine Perfect Strangers.’ Lucy is often mentioned in interviews and social media posts related to the author.”
It seems we got struck with a case of hallucination here. Not only didn’t ChatGPT know because the movie was released later, but it came up with a false answer instead of saying “I don’t know.” I couldn’t find any information about Liane Moriarty ever using the pseudonym Elly Conway.
But running it with the same RAG query as I used above, I instead got this completely accurate answer: “Alfie (Context: When the plots of reclusive author Elly Conway’s fictional espionage novels begin to mirror the covert actions of a real-life spy organization, quiet evenings at home become a thing of the past. Accompanied by her cat Alfie and Aiden, a cat-allergic spy …).”
There we go. We have done GraphRAG with (almost) pure Cypher.
Further reading
As I mentioned initially, Neo4j is integrated with several dedicated AI technology stacks to help write GraphRAG applications. Here are some articles that talk more about those.
- Get Started With GraphRAG: Neo4j’s Ecosystem Tools
- LLM Knowledge Graph Builder: From Zero to GraphRAG in Five Minutes
- GenAI Ecosystem – Neo4j Labs
GraphRAG in (Almost) Pure Cypher was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



