How to improve multi-hop reasoning with knowledge graphs and LLMs

Graph ML and GenAI Research, Neo4j
20 min read

Retrieval-augmented generation (RAG) applications excel at answering simple questions by integrating data from external sources into LLMs. But they struggle with multi-part questions that require connecting the dots across several pieces of related information. That’s because RAG applications require a database designed to store data in a way that makes it easy to find all the pieces needed to answer these types of questions.
Knowledge graphs are well-suited for handling complex, multi-part questions because they store data as a network of nodes and the relationships between them. This connected data structure allows RAG apps to navigate from one piece of information to another efficiently, accessing all related information. The technique of combining RAG with knowledge graphs is known as GraphRAG.
In this blog post, you’ll learn about:
- The inner workings of RAG applications
- How knowledge graphs improve retrieval via GraphRAG
- Techniques for combining structured graph data and unstructured text
- How LLMs can be used to automatically generate and expand knowledge graphs
- Frequently asked questions around using knowledge graphs with LLMs
How RAG works
Retrieval-augmented generation (RAG) is a technique for enhancing LLM responses by retrieving relevant information from external databases and incorporating it into the generated output.
The RAG process is simple. When a user asks a question, an intelligent search tool looks for relevant information in the provided databases:
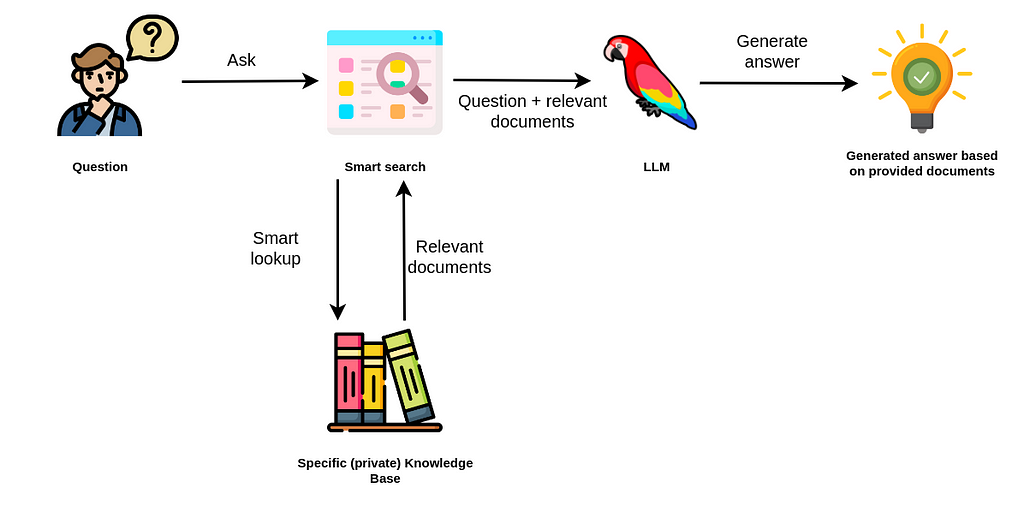
You’ve likely used tools like Chat with Your PDF that search for information in a provided document. Most of those tools use vector similarity search to identify the chunks of text that contain data similar to a user’s question. The implementation is straightforward, as shown in the diagram below.

How vector similarity search works in a RAG application
To prepare documents for retrieval-augmented generation (RAG), you’d typically follow these major steps:
- Chunk the text: PDFs or other documents are split into multiple chunks. You can use different strategies depending on how large the text chunks should be and whether there should be any overlap between them.
- Generate embeddings: The RAG system uses a text embedding model to generate vector representations of the text chunks.
- Encode the user query: The system encodes the user’s input (the question) as a vector at query time.
- Perform similarity search: The system applies similarity algorithms like cosine to compare the distance between the user input and the embedded text chunks to find the most semantically relevant matches.
- Retrieve top matches: The RAG system returns the three most similar documents to provide context to the LLM, which enhances its ability to generate accurate answers.
This similarity search approach works fairly well when the vector search can identify relevant chunks of text. However, this approach may not provide all the information you need if the context resides in multiple documents or even multiple chunks of text. For example, consider the question:
Did any of the former OpenAI employees start their own company?
This question is multi-part in that it contains two questions:
- Who are the former employees of OpenAI?
- Did any of them start their own company?

Answering these types of questions is a multi-hop question-answering task. A single question can be broken down into multiple sub-questions. Getting an accurate answer requires the system to retrieve several documents.
Simply chunking and embedding documents in a database and then using plain vector similarity search won’t hit the mark for multi-hop questions. Here’s why:
- Repeated information in top N documents: The provided documents aren’t guaranteed to contain all the information required to answer a question fully. For example, the top three similar documents might all mention that Shariq worked at OpenAI and possibly founded a company—all while ignoring all the other former employees who became founders.
- Missing reference information: Depending on the chunk sizes, some chunks might not contain the full context or references to the entities mentioned in the text. You can mitigate the problem of missing references by overlapping the chunks. When the references point to another document, you can use a co-reference resolution or a pre-processing technique.
- Hard to define the ideal N number of retrieved documents: Some questions require more documents for an LLM to be accurate, while in other situations, a large number of documents would only increase the noise (and cost).
In some instances, the similarity search will return duplicated information while other relevant information is ignored due to a low K number of retrieved information or embedding distance.

It’s clear that plain vector similarity search falls short when answering multi-hop questions that require connecting information across multiple chunks or documents. While techniques like overlapping chunks or adjusting the number of retrieved documents can help, they don’t fundamentally address the limitations of treating content as isolated text blocks.
To overcome these challenges, we need a more structured way to represent and navigate relationships between pieces of information—one that allows us to “connect the dots” across entities, events, and concepts. This is where GraphRAG comes in.
What is GraphRAG?
GraphRAG is a retrieval-augmented generation (RAG) technique that uses a knowledge graph to improve the accuracy, context, and explainability of LLM-generated responses.
RAG architectures are highly effective at helping language models answer straightforward questions using external data, but they often struggle with more complex queries that involve multiple topics or require reasoning across several pieces of information. This limitation is largely due to their reliance on traditional vector search, which retrieves semantically similar content but lacks awareness of how facts are connected. This makes it difficult for the model to support multi-hop or multi-entity questions.
GraphRAG addresses this challenge by combining RAG with a knowledge graph — a connected data structure representing real-world entities (like people, products, or events) and their relationships. GraphRAG enhances context by using multiple types of retrievers, such as those designed to navigate documents, domains, or graph-based structures, to pull in the most relevant information for a given query. This more connected context allows GraphRAG to produce more accurate, trustworthy, and traceable results, which provides a strong foundation for enterprise use cases where context, accuracy, and explainability are essential.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

The GraphRAG pipeline
GraphRAG follows the core RAG architecture, consisting of three stages:
- Retrieval: The system identifies relevant content from external sources — documents, databases, or knowledge graphs — using techniques like vector similarity, structured queries, or hybrid approaches. These results are ranked and filtered based on their relevance to the user’s query.
- Augmentation: The retrieved information is combined with the original query, along with any task-specific instructions or contextual signals. This augmented prompt forms the input to the language model, grounding its response in authoritative, query-specific data.
- Generation: The language model generates an answer based on the augmented prompt. Because the model generates responses only from the retrieved context, the output is more accurate, aligned to source material, and can include references to original sources or metadata for added transparency.
This process enhances the model’s performance by integrating retrieval and reasoning, delivering responses that are not only fluent (as we expect from a language model), but also factually grounded and domain-aware.
How GraphRAG enhances retrieval
A GraphRAG retrieval can begin with vector, full-text, spatial, or other types of search to find the most relevant pieces of information in the knowledge graph. From there, it follows relevant relationships to gather additional context needed to answer the user’s query. The context of the user and task is considered to increase relevance. All captured nodes, relationships, and their attributes can be filtered and ranked before being returned as context in the augmentation phase.
This approach offers several key advantages over vector-only RAG systems:
- Broader context: By navigating the graph and following relationships, GraphRAG can uncover information not explicitly mentioned in the top retrieved chunks.
- Task-aware relevance: Filtering and ranking based on user context helps prioritize the most pertinent data.
- Improved explainability: GraphRAG captures how retrieved pieces are connected, making it easier to trace the reasoning behind a generated response.
- Richer grounding: The graph structure supports integration of structured, unstructured, and computed signals, enabling more nuanced and trustworthy outputs.
These retrieval improvements contribute to GraphRAG’s ability to generate responses that are more accurate, relevant, and traceable than those produced by traditional, vector-only RAG approaches.

Retrieval strategies and graph construction in GraphRAG
GraphRAG retrieval is highly adaptable. It changes based on the domain and the specific information the user is trying to find. Different retriever types, such as vector-based semantic search, structured graph queries (e.g., Text2Cypher), or hybrid combinations, can be orchestrated together. These retrievers may run in sequence or be selected dynamically by an LLM acting as an agent, passing parameters and refining results until the necessary information is gathered.
This flexible architecture allows GraphRAG to surface not just isolated facts but connected, contextual insights drawn from a broader network of relationships, improving accuracy, trustworthiness, and explainability.
Effective retrieval, however, starts with a well-modeled knowledge graph. Building this foundation involves two key steps:
- Model the domain by defining the relevant entities and relationships.
- Create or compute the graph by importing structured data, extracting from unstructured sources, or enriching with computed signals.
These steps can be repeated iteratively to refine the graph over time, ensuring it remains aligned with evolving data and use cases.
New to GraphRAG?
Use this guide to build a GraphRAG application that can answer complex questions.
Why use a knowledge graph to ground LLM responses
LLMs excel at generating fluent, coherent answers, but without accurate context, they can easily produce misleading or incorrect information. This is especially risky in enterprise settings where factuality, traceability, and completeness matter. If you’re building with LLMs, retrieval-augmented generation (RAG) lets you ground responses in external data instead of relying on pretraining alone.
Most RAG systems today use vector search to find semantically similar documents based on the user’s question. This works well for retrieving individual facts or matching snippets of text. But when the goal is to surface a complete, connected, and explainable answer, vector search alone can fall short. This is where knowledge graphs come in. Knowledge graphs ground LLMs in structured data and explicit relationships. They organize information into a network of entities (people, companies, concepts, or events) and the connections between them. Instead of treating documents as isolated blobs of text, they represent the underlying meaning and context that link those facts together.

By combining the strengths of semantic similarity (via vector search) with structured, connected reasoning (via graph queries), GraphRAG enables the LLM to deliver answers that are not only relevant but also richer, deeper, and easier to trace back to source data.
Neo4j’s native integration of graph and vector search makes this seamless. Developers can traverse the graph to follow relationships, retrieve metadata, apply filters, or aggregate results—all while maintaining access to the unstructured content embedded in the nodes.
One reason this approach is so powerful is that it complements newer LLM strategies with a well-established technique: the information extraction pipeline. The information extraction pipeline has been around for some time. It’s the process of extracting structured information from unstructured text, often in the form of entities and relationships. The beauty of combining it with knowledge graphs is that you can process each document individually. When the knowledge graph is constructed or enriched, the information from different records gets connected.
In the example above, the first document provided the information that Dario and Daniela used to work at OpenAI, while the second document offered information about their Anthropic startup. Each record was processed individually, but the knowledge graph representation connects the data, making it easy to answer questions that span multiple documents.
Most of the newer LLM approaches to answering multi-hop questions focus on solving the task at query time. The truth is many multi-hop question-answering issues can be solved by preprocessing data before ingestion and connecting it to a knowledge graph. You can use LLMs or custom text domain models to perform the information extraction pipeline.
In the sections that follow, we’ll explore why this approach is so powerful, with examples of how knowledge graphs:
- Support reasoning across tools and data sources through chain-of-thought workflows
- Condense and summarize data for faster, more efficient retrieval
- Link structured entities with unstructured content for richer context
Knowledge graph as condensed information storage
LLMs often struggle with overly long or noisy context. One solution is to preprocess and condense information during ingestion, so the model receives only what’s relevant at query time. Knowledge graphs enable this method by capturing key entities and relationships up front.
Instead of embedding entire documents or large text chunks, you can extract structured facts, like who founded a company, or what products are related to an event, and represent them in a graph. This dramatically reduces the volume of data that needs to be searched or passed into the prompt, while preserving critical meaning.
Because graphs connect facts across different documents, you don’t need to manually stitch context together during retrieval. Relationships do the work for you.
Using knowledge graphs in chain-of-thought flow
Another fascinating development around LLMs is the chain-of-thought question answering, especially with LLM agents.
LLM agents can separate questions into multiple steps, define a plan, and draw from any of the provided tools to generate an answer. Typically, the agent tools consist of APIs or knowledge bases that the agent can query to retrieve additional information.
Let’s again consider the same question:
What’s the latest news about the founders of Prosper Robotics?
In this example, you’d want the LLM to identify the Prosper Robotics founders using the knowledge graph structure and then retrieve recent articles that mention them.

Suppose you don’t have explicit connections between articles and the entities they mention, or the articles and entities are in different databases. An LLM agent using a chain-of-thought flow would be very helpful in this case. First, the agent would separate the question into sub-questions:
- Who is the founder of Prosper Robotics?
- What’s the latest news about the founder?
Now the agent can decide which tool to use. Let’s say it’s grounded on a knowledge graph, which means it can retrieve structured information, like the name of the founder of Prosper Robotics.
The agent discovers that the founder of Prosper Robotics is Shariq Hashme. Now the agent can rewrite the second question with the information from the first question:
- What’s the latest news about Shariq Hashme?
The agent can use a range of tools to produce an answer, including knowledge graphs, vector databases, APIs, and more. The access to structured information allows LLM applications to perform analytics workflows where aggregation, filtering, or sorting is required. Consider these questions:
- Which company with a solo founder has the highest valuation?
- Who founded the most companies?
Plain vector similarity search has trouble answering these analytical questions since it searches through unstructured text data, making it hard to sort or aggregate data.
While chain-of-thought demonstrates the reasoning capabilities of LLMs, it’s not the most user-friendly technique since response latency can be high due to multiple LLM calls. But we’re still very excited to understand more about integrating knowledge graphs into chain-of-thought flows for many use cases.

How to generate a knowledge graph using an LLM
Turning unstructured data into structured insights is a major challenge, but also one of the biggest opportunities in AI, because so much valuable information lives in documents, transcripts, and other raw formats. With Neo4j’s LLM Knowledge Graph Builder, large language models (LLMs) are now used not just to consume knowledge graphs, but to create them — automatically extracting entities, relationships, and meaning from raw text and mapping them to a connected graph.
This section breaks down how that works under the hood.
What does the LLM knowledge graph builder do?
The Neo4j LLM Knowledge Graph Builder is an online application that transforms unstructured content, PDFs, documents, URLs, YouTube transcripts, and more, into structured knowledge graphs stored in Neo4j. It does this by combining LLMs such as OpenAI, Gemini, Claude, Diffbot, and others with Neo4j’s graph-native storage and retrieval capabilities.

The extraction turns the documents into a lexical graph of documents and chunks (with embeddings) and an entity graph with nodes and their relationships, both stored in your Neo4j database. You can configure the extraction schema and apply clean-up operations after the extraction.
You can use different retrieval-augmented generation (RAG) approaches (GraphRAG, vector, Text2Cypher) to ask questions about your data and see how the extracted data constructs the answers. The frontend is a React application, and the backend is a Python FastAPI application running on Google Cloud Run, but you can deploy it locally using Docker Compose. It uses the llm-graph-transformer module that Neo4j contributed to LangChain and other LangChain integrations (e.g., for GraphRAG search). See the Features documentation for details.
How it works: From text to graph in eight steps
- Upload sources are stored as Document nodes in the graph.
- Document (types) are loaded with LangChain loaders.
- The content is split into Chunks.
- Chunks are stored in the graph and connect to the document and to each other for advanced RAG patterns.
- Highly similar chunks are connected with a SIMILAR relationship (with a weight attribute) to form a k-nearest neighbors graph.
- Embeddings are computed and stored in the chunks and vector index.
- The llm-graph-transformer or diffbot-graph-transformer extracts entities and relationships from the text.
- Entities and their relationships are stored in the graph and connect to the originating chunks.
Key features of the LLM Knowledge Graph Builder
The LLM Knowledge Graph Builder supports a range of features designed to simplify the process of building knowledge graphs from unstructured data. These include:
- Multimodal ingestion: Upload PDFs, HTML, transcripts, and more – or point to URLs and cloud buckets.
- Schema configuration: Choose from preset schemas, reuse an existing Neo4j schema, or let the LLM infer one dynamically.
- Integrated vector and graph retrieval: Embeddings are stored alongside graph data for hybrid search.
- Visualization and chat: Explore the graph via the in-app viewer or Neo4j Bloom; use GraphRAG to chat with your data.
Flexible deployment: Use the hosted version (on Neo4j Aura) or deploy locally with Docker Compose. - Traceable outputs: Every graph element is linked to its source text and chunk for full explainability.
The Neo4j LLM Knowledge Graph Builder gives you a fast, flexible way to turn unstructured content, like PDFs, transcripts, or webpages, into structured graphs that power retrieval-augmented applications.
Automating the extraction of entities and relationships helps you reduce manual graph modeling and accelerate development. As LLMs and graph-based search continue to evolve, tools like this make it easier to combine text and structured data in a single, queryable framework, ready for use in GraphRAG and beyond.
Frequently asked questions
What are knowledge graphs in LLMs?
Knowledge graphs represent real-world entities and the relationships between them in a structured, connected format. When used with LLMs, a knowledge graph grounds the model in your own data, organizing both structured and unstructured information into a connected data layer. This enables deeper, more accurate, and explainable AI insights.
Can LLMs generate graphs?
Yes. LLMs can extract entities and relationships from unstructured text and convert them into a graph structure. This process, often called LLM-driven knowledge graph construction, is used to automate graph building at scale using tools like the Neo4j Knowledge Graph Builder.
What is the purpose of a knowledge graph?
The purpose of a knowledge graph is to organize data in a way that captures both the content and the context, connecting people, places, events, and other entities through meaningful relationships. This makes it ideal for powering search, recommendation, reasoning, and GenAI applications.
What is GraphRAG in the LLM world?
GraphRAG is a retrieval-augmented generation (RAG) that incorporates a knowledge graph to enhance language model responses, either alongside or in addition to traditional vector search. Unlike basic vector-based RAG, GraphRAG combines semantic search and structured graph traversal so the model can access not only relevant facts but also the relationships between them. This makes the output more accurate, complete, and easier to trace back to the source.
What is the difference between RAG and a knowledge graph?
GraphRAG combines retrieval-augmented generation with a knowledge graph to give language models access to connected, structured context. While basic RAG techniques retrieve isolated pieces of relevant information using vector search, GraphRAG taps into a knowledge graph to understand how facts are linked.
Because knowledge graphs are structured data representations — built from entities and their relationships — they allow for more precise retrieval and transformation of information. This structure helps the model navigate the information space more intelligently, enabling it to generate more accurate and explainable answers. In this approach, the knowledge graph isn’t just a data store; it’s a semantic backbone that makes the model’s reasoning more grounded and transparent.
GraphRAG for multi-hop reasoning
RAG applications often require retrieving information from multiple sources to generate accurate answers. While text summarization can be challenging, representing information in a graph format offers several advantages.
By processing each document separately and connecting them in a knowledge graph, we can construct a structured representation of the information. This approach makes it easier to traverse and navigate interconnected documents, enabling multi-hop reasoning to answer complex queries. Constructing the knowledge graph during the ingestion phase also reduces the workload at query time, improving latency.
Read through our documentation on this project on the new GitHub repository.
Ready to dive deeper?
Explore The developer’s guide to GraphRAG for a complete guide to designing, building, and scaling GraphRAG applications.
Additional learning resources
To learn more about building smarter LLM applications with knowledge graphs, check out the other posts in this blog series.
- What Is GraphRAG?
- LLM Knowledge Graph Builder: Back-End Architecture and API Overview
- Video: Building Knowledge Graphs with LLMs and Neo4j
- GraphRAG Pattern Catalog
- Selecting a Database for Enterprise GenAI
- Neo4j GraphRAG Python Package
- LangChain Library Adds Full Support for Neo4j Vector Index
- Harnessing Large Language Models With Neo4j
- Construct Knowledge Graphs From Unstructured Text
- Using a Knowledge Graph to Implement a RAG Application
- The Developer’s Guide: How to Build a Knowledge Graph
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



