Features documentation
Sources
Local file upload
You can drag & drop files into the first input zone on the left. The application will store the uploaded sources as Document nodes in the graph using LangChain Loaders (PDFLoader and Unstructured Loader).
| File Type | Supported Extensions |
|---|---|
Microsoft Office |
.docx, .pptx, .xls |
Images |
.jpeg, .jpg, .png, .svg |
Text |
.html, .txt, .md |
Web Links
The second input zone handles web links.
-
YouTube transcripts
-
Wikipedia pages
-
Web Pages
The application will parse and store the uploaded YouTube videos (transcript) as a Document nodes in the graph using YouTube parsers.
For Wikipedia links we use the Wikipedia Loader. For example, you can provide https://en.wikipedia.org/wiki/Neo4j and it will load the Neo4j Wikipedia page.
For web pages, we use the Unstructured Loader. For example, you can provide articles from https://theguardian.com/ and it will load the article content.
Cloud Storage
LLM Models
The application uses ML models to transform PDFs, web pages, and YouTube video transcripts into a knowledge graph of entities and their relationships. ENV variables can be set to configure/enable/disable specific models.
The following models are configured (but only the first 3 are available in the publicly hosted version)
-
OpenAI GPT 3.5 and 4o
-
VertexAI (Gemini 1.0),
-
Diffbot
-
Bedrock,
-
Anthropic
-
OpenAI API compatible models like Ollama, Groq, Fireworks
The selected LLM model will both be used for processing the newly uploaded files and for powering the chatbot. Please note that the models have different capabilities, so they will work not equally well especially for extraction.
Graph Enhancements
Graph Schema
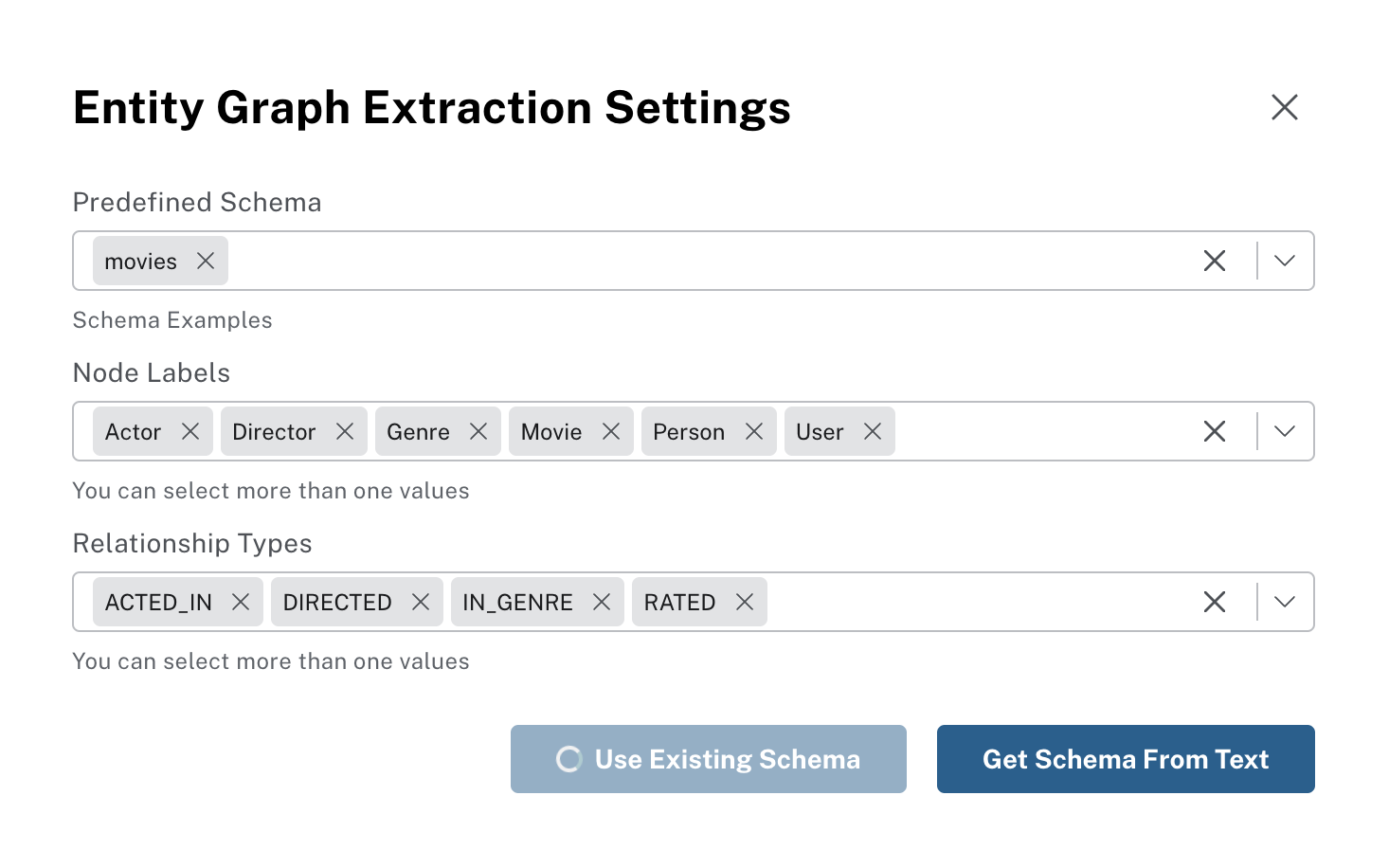
If you want to use a pre-defined or your own graph schema, you can do so in the Graph Enhancements popup. This is also shown the first time you construct a graph and the state of the model configuration is listed below the connection information.
You can either:
* select a pre-defined schema from the dropdown on top,
* use your own by entering the node labels and relationships,
* fetch the existing schema from an existing Neo4j database (Use Existing Schema),
* or copy/paste a text or schema description (also works with RDF ontologies or Cypher/GQL schema) and ask the LLM to analyze it and come up with a suggested schema (Get Schema From Text).
Delete Disconnected Nodes
When extracting entities, it can happen that after the extraction a number of nodes are only connected to text chunks but not to other entities. Which results to disconnected entities in the entity graph.
While they can hold relevant information for question answering they might affect your downstream usage. So in this view you can select which of the entities that are only connected to text chunks should be deleted.
Visualization
You can visualize the lexical, the entity graph or the full knowledge graph of your extracted documents.
Graph Visualization
You have 2 options - either per document with the magifying glass icon at the end of the table or for all selected documents with the "Preview Graph" button.
The graph visualization will show for the relevant files in a pop-up and you can filter for the type of graph you wanto to see:
-
Lexical Graph - the document and chunk nodes and their relationships
-
Entity Graph - the entity nodes and their relationships
-
Full Graph - all nodes and relationships
Explore in Neo4j Bloom
With the button "Explore in Neo4j Bloom" you can open the constructed knowledge graph in Neo4j Workspace for further visual exploration, querying and analysis.
In Bloom/Explore you can run low code pattern based queries (or use the co-pilot) to fetch data from the graph and succesfully expand. If you are running against a GDS enabled instance, you can also run graph algorithms and visualize the results. You can also interactively edit and add to the graph.
In Neo4j Data Importer you can additionally import structured data from CSV files and connect it to your extracted knowledge graph.
In Neo4j Query you can write Cypher queries (or use the co-pilot) to pull tabular and graph data from your database.
Chatbot
How it works
When the user asks a question, we use the configured RAG mode to answer it with the data from the graph of extracted documents. That can mean the question is turned into an embedding or a graph query or a more advanced RAG approach.
We also summarize the chat history and use it as an element to enrich the context.
Features
-
Select RAG Mode you can select vector-only or GraphRAG (vector+graph) modes
-
Chat with selected documents: Will use the selected documents only for RAG, uses pre-filtering to achieve that
-
Details: Will open a Retrieval information pop-up showing details on how the RAG agent collected and used sources (documents), chunks, and entities. Also provides information on the model used and the token consumption.
-
Clear chat: Will delete the current session’s chat history.
-
Expand view: Will open the chatbot interface in a fullscreen mode.
-
Copy: Will copy the content of the response to the clipboard.
-
Text-To-Speech: Will read out loud the content of the response.
GraphRAG
For GraphRAG we use the Neo4j Vector Index (and a fulltext index for hybrid search) with a Retrieval Query to find the most relevant chunks and entities connected to these and then follow the entity relationships up to a depth of 2 hops.
Vectory Only RAG
For Vector only RAG we only use the vector and fulltext index (hybrid) search results and don’t include additional information from the entity graph.
Answer Generation
The various inputs and determined sources (the question, vector results, entities (name + description), relationship pairs, chat history) are all sent to the selected LLM model as context information in a custom prompt, asking to provide and format a response to the question asked based on the elements and context provided.
Of course, there is more magic to the prompt such as formatting, asking to cite sources, not speculating if the answer is not known, etc. The full prompt and instructions can be found in the GitHub repository.